Introduction
We all know the theory of distributed computing: by dividing tasks among several computers rather than having all processes originating from one central computer, we can increase overall throughput. The problem is that in reality the actual implementation of such a scheme is often quite complex.
Technologies like EJB were supposed to make it easier, but they proved extremely intrusive to both the design and development process. Fortunately, the emergence of JVM-level clustering technologies like Terracotta into the mainstream now provides a viable alternative.
Recently Shine Technologies distributed one of its applications using Terracotta and achieved significant performance gains. In the past, our application performance was generally limited by the server it was running on. With Terracotta this no longer appears to be the case. During our performance testing, when one server was at capacity, we just added another and the overall application throughput increased markedly - to the point that our main limiting factor was the database.
Some Background
Shine Technologies is a provider of IT consultancy and development services to a number of companies in the Australian energy industry. Following the adoption of Full Retail Contestability (FRC) in this industry, Shine has developed numerous products for these companies.
In a nutshell, these products help facilitate the financial interactions between distributors and retailers regarding network usage. These interactions are very high volume, with large retailers having to process millions of transactions per month. Consequently, the ability of the application to scale becomes business-critical - particularly when all of the transactions are received by the retailer on the same day.
A recent addition to this suite of products has been an application to be used by a service provider to electricity retailers. This application - known as the Market Reconciliation System (MRS) - receives large volumes of electricity usage data each week, and provides a reporting and reconciliation mechanism to retailers, highlighting any discrepancies between what they expect to be charged for usage and what they are actually being charged.
Given the high-volume nature of this product, scalability was a big driver in the application architecture. After an initial proof-of-concept involving various distributed computing frameworks, Terracotta was deemed to be the framework most likely to give MRS the grunt it needed.
Terracotta and the Master/Worker Pattern
Terracotta enables applications to be deployed on multiple JVMs, yet interact with each other as if they were running on the same JVM. The user nominates objects that are to be shared between JVMs and Terracotta transparently makes them accessible to all. Terracotta provides a number of pre-configured solutions for clustering particular Java enterprise environments - for example, Tomcat, JBoss or Spring. However, in our case we weren't using a container so needed to configure Terracotta ourselves.
Fortunately we found an approach that was both appropriate to our application and had already been proven to work well with Terracotta: the Master/Worker design pattern. Its usage with Terracotta was first described by Jonas Bonèr in his excellent blog entry How to Build a POJO-based Data Grid using Open Terracotta.
For those not familiar with the Master/Worker pattern, the ‘Master' is responsible for determining the items of work that need to be done and places each item onto a shared queue. It then continues to monitor the completion status of each item and completes when all have completed. The ‘Workers' pick the work items off the queue and process them, setting the item's completion status when the work is finished.
In our implementation, both the Master and Workers runs in their own JVMs. The JVMs are distributed across a number of machines. Any shared objects (such as the work queue and work item statuses) are managed (and effectively synchronized) by the Terracotta server.
There are a number of useful ways to visualise this architecture. The first is a purely physical one, showing how machines, JVMs and Master/Workers relate to one another on the network.

Note that it is possible to have multiple JVMs on a single machine. You might want to do this if the heap for a JVM has hit its maximum allowable size, but there is additional physical memory on the machine that another JVM could use.
So where does Terracotta fit into this physical architecture? Well, it oversees all of the JVMs - something perhaps best illustrated with a second, more logical visualization:
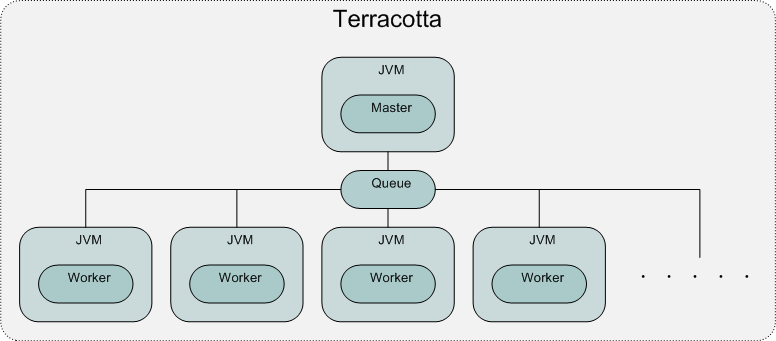
We see that Terracotta instruments the JVMs so that they can transparently share a queue of work items across the physical network. It's even possible to add additional Masters and have them share the queue as well.
Learning Terracotta: An Example
Whilst Terracotta does not require you to develop code specifically with distribution in mind, in the long run it can help with overall performance if the data shared between the master and workers is minimised. The more autonomously the workers can perform their operations, the less the Terracotta server needs to manage across the multiple JVM's.
Developing the solution with this in mind involved some trial and error for us. To help explain some of the hurdles encountered, we'll present a simplified example.
Our application processes multiple files containing records composed of comma-separated values (CSV). Furthermore, each CSV record contains a field called a Maximum Daily Usage (MDU). For the sake of simplicity, lets just say that, amongst other things, our task was to report the maximum MDU found for each file (the actual processing is far more complicated than this).
Initially, as per Jonas' blog entry, we created a WorkUnit that implemented the Work interface from the CommonJ WorkManager specification. This WorkUnit was responsible for processing a given file to find the maximum MDU. The code looked something like this:
public class WorkUnit implements Work
{
private String filePath;
private Reader reader;
public WorkUnit(String aFilePath)
{
filePath = aFilePath;
}
public void run()
{
private String maxMDU = "";
setReader(new BufferedReader(new FileReader(filePath)));
String record = reader.readLine();
while (record != null)
{
String[] fields = record.split(",");
String mdu = fields[staging:4];
if (mdu.compareTo(maxMDU) > 0)
{
setMaxMDU(mdu);
}
record = reader.readLine();
}
System.out.println("maximum MDU = " + maxMDU);
doStuffWithReader();
doMoreStuffWithReader();
doEvenMoreStuffWithReader();
}
private void setReader(Reader reader)
{
this.reader = reader;
}
... }
For each file in a given directory, the Master created a WorkUnit, providing it with location of the file it was to process. The WorkUnit was then wrapped in a WorkItem - which included a status flag - and ‘scheduled' by placing it on a shared queue. Our Worker implementations then picked up the WorkItem, extracted our WorkUnit and called its run() method, which in turn would process it's file and report the maximum MDU encountered. It would then go onto do a bunch of other things with the file.
The key thing to note is that we've chosen to store the Reader as an instance variable - it's actually being used by a number of methods and it would be impractical to use a local variable and pass it around everywhere.
To share the queue amongst workers, we configured Terracotta's tc-config.xml as follows:
<application>
<dso>
<roots>
<root>
<field-name>
com.shinetech.mrs.batch.core.queue.SingleWorkQueue.m_workQueue
</field-name>
</root>
</roots>
<locks>
<autolock>
<method-expression>* *..*.*(..)</method-expression>
<lock-level>write</lock-level>
</autolock>
</locks>
<instrumented-classes>
<include>
<class-expression>
com.shinetech.mrs.batch.core.queue..*
</class-expression></include> <include>
<class-expression>
com.shinetech.mrs.batch.input.workunit..*
</class-expression>
</include>
</instrumented-classes>
</dso>
</application>
You don't need to understand this in too much detail other than that it nominates the fields to be shared - in this case our queue - and specifies which classes should be instrumented to safely share it.
Our first run using this WorkUnit failed - when the WorkUnit tried to set the value of the reader variable an UnlockedSharedObjectException was thrown by Terracotta with the message "Attempt to access a shared object outside the scope of a shared lock". Essentially Terracotta was telling us that we had tried to update an attribute of an object that was shared between the Master and the Worker, but we had not told Terracotta that it needs to lock (or synchronize) the attribute.
The key problem here is that even if we don't initialise the instance variable until we run the worker, Terracotta regards it as shared by the master and the worker because the variable belongs to an object on a queue that is shared. (Incidentally, the Terracotta exception handling is excellent; if you try to do something that you can't, a Terracotta exception will tell you both what you did wrong and what you should do to fix it.)
At this stage there were a few different approaches we could have taken. One option was to have synchronized setReader() in the WorkUnit class. Terracotta would have then locked access to the reader thanks to the autolock section in tc-config.xml. Alternatively, rather than changing the code, we could have simply added a named-lock to the locks section of tc-config.xml, which in turn would have told Terracotta to effectively synchronize access to the reader across the JVM cluster:
<named-lock>
<lock-name>WorkUnitSetterLock</lock-name>
<method-expression>
* com.shinetech.mrs.batch.dataholder..*.set*(..)
</method-expression>
<lock-level>write</lock-level>
</named-lock>
Ultimately, however, neither of these approaches was what we needed. For in a more realistic and complex example, the WorkUnit may have many instance variables that are really only relevant when it is being run by the Worker. The Master does not need to know anything about them, and they exist really only for the duration of the run() method. From a performance perspective, we didn't want Terracotta to have to synchronize access to these WorkUnit attributes if the Master will never access them.
What we really wanted was the ability for the WorkUnit to be instantiated not by the master, but instead at the time that the Worker picked up the WorkItem off the queue. To accomplish this we introduced a WorkUnitGenerator:
public class WorkUnitGenerator implements Work
{
private String filePath;
public WorkUnitGenerator(String aFilePath)
{
filePath = aFilePath;
}
public void run()
{
WorkUnit workUnit = new WorkUnit(filePath);
workUnit.run();
}
}
Now, the Master creates a WorkUnitGenerator, providing it with the location of the file to process. The WorkUnitGenerator is wrapped in a WorkItem and scheduled. The Worker implementation picks up the WorkItem, extracts the WorkUnitGenerator and calls its run() method. The run() method instantiates a new WorkUnit and delegates the file processing to the WorkUnits run() method. So we now have a situation where the WorkUnit, which in our case should be independent of the Master, is indeed independent, and Terracotta doesn't need to perform any unnecessary synchronization across JVM's.
The code samples above outline just one approach to the Master / Worker pattern. There are probably other ways it could be done, and down the track after more experience with Terracotta, we may well find a better implementation. The main point is that whilst Terracotta and the Master / Worker pattern give you the ability to distribute work across many machines, you have to be careful about what you want to share and what you don't.
Performance Results
The proof-of-concept of Terracotta showed much promise, but did it actually deliver? A scenario was devised to test the scalability of the application. 89 data files were to be loaded, containing a total number of 872,998 records. These were taken from a real production system, thus giving us confidence that they constituted a realistic data set.
The Terracotta server and single master process were running on one machine. A varying number of distributed worker machines were used to process the data, with each machine running four workers. The results were as follows:
| Worker Machines | Workers | Time (seconds) |
| 1 | 4 | 416 |
| 2 | 8 | 261 |
| 3 | 12 | 214 |
| 4 | 16 | 194 |
| 5 | 20 | 193 |
These can be graphed as follows:

With only one worker machine running four workers, the total time taken to load the 89 files was 416 seconds. By simply adding one more worker machine to our distributed computing system, the time taken to load the 89 files was almost halved. Further performance improvements were obtained with the addition of each new worker machine.
As can be seen from the graph above, the scalability does begin to plateau. With the addition of more workers, the database server comes under increased load, and at some point in time most likely becomes the bottleneck
Conclusion
By expanding upon Joseph Boner's work with Terracotta and the Master/Worker pattern we were able to build a distributed computing component into our application.
At this stage, our application is running in a production environment for a customer whose data-processing requirements only warrant the use of a single machine. However, having performance-tested across multiple machines using a much larger data set taken from another production environment, we remain confident that Terracotta will be able to scale our application when the time comes.
The database ultimately proved to be the bottleneck, but given on the performance we are getting, this is something we can live with. Indeed, if you were running a process that was solely CPU-bound, who knows what scalability improvements could be achieved.
Currently in our architecture, the Masters (ie processes creating the tasks to be performed), all run on the same machine With Terracotta, it is now a trivial exercise for us to add additional Master machines to spread the Master load, should the current single Master machine become overloaded.
Terracotta has given our application some real grunt. We are looking forward to watching its performance over the next few months with additional real-world datasets and seeing how our other applications can benefit from our experience.
Offered by courtesy of http://www.shinetech.com.