Key Takeaways
- Data captured within modern systems has become increasingly “big”, and may be generated as an unordered and (effectively) infinite stream. Data may also be captured with unknown delays, particularly if it is collected via an unreliable (distributed) network.
- A large amount of data processing requires aggregation operations, such as counting and joining, and this means that the stream of data must be chopped up in finite chunks or “windows”.
- A watermark is a concept that attempts to address the issue of late-arriving data. When the data-processing system receives a watermark timestamp, it assumes that it is not going to see any message older than that timestamp.
- The Google Dataflow model — and corresponding Apache Beam implementation — encourages users to ask four questions in order to understand the approach required when processing data: What are you computing? Where in event time? When in processing time? How do refinements relate?
- The Apache Beam project includes: the conceptual unified Beam model (the what/where/when/how), SDKs for writing data-processing pipelines using the Beam model APIs, and runners for executing the data-processing pipelines using existing distributed processing back ends like Apache Flink or Apache Spark.
At QCon San Francisco 2016, Frances Perry and Tyler Akidau presented “Fundamentals of Stream Processing with Apache Beam”. Perry and Akidau, both senior staff engineers at Google, began the talk with a discussion of how data captured within modern systems has become increasingly “big”, and may be generated as an unordered and (effectively) infinite stream. This can make it challenging for data-processing systems and end users to extract meaningful and timely results and insight for the business.
For example, capturing ongoing player scores from a mobile-game application results in a continual stream of data, and the business may want to mine this data in order to understand and improve player retention or “stickiness”. In addition to being unordered, data may also be captured with unknown delays, particularly if it is collected via an unreliable network: data may arrive delayed by a few seconds due to a network glitch, a few minutes due to loss of signal, or potentially hours (or days) delayed if the player continues to play the game aboard a transatlantic flight without mobile reception until they land.
Some data processing is relatively straightforward — for example, element-wise transformations like parsing, translating, or filtering. However, a large amount of data processing requires aggregation operations such counting and joining, and this means that the stream of data must be chopped up in finite chunks before the aggregation can occur and a result be emitted.
The logical approach to this would be to divide the stream into processing time windows — for example, two-minute or one-hour chunks — but the challenge with this approach is the potential late arrival of data. This can lead to processing data out of context, where the processing time is significantly different than the original event time, which may be a problem for some algorithms. Somehow, late arriving data needs to be shuffled back into the appropriate time window and context from which it originated.

Although this reshuffling of late-arriving data makes conceptual sense, it can be challenging to implement. In an idealized world, the event data would be processed as it was generated, but in reality there is a variable skew between the event generation and processing time for which a formal method needs to account and compensate. The solution is to use a watermark to describe event-time progress. A watermark is essentially a timestamp, and when the processing system receives a watermark, it assumes that it is not going to see any message older than that timestamp. A watermark can be perfect — for example, with data taken from a static set of sequentially increasing log files — or heuristic, where the system has to best guess about when all events for a given time window have arrived.

If a watermark is too slow, the system waits for late data to arrive, and the computational results of the stream-processing operation may be delayed. If a watermark is too fast, then some data arrives late, and an early (speculative) result that was emitted may have to be updated. The reality is that many modern systems will be processing infinite streams or unordered data that is collected via a distributed system and so the data-processing system must account for these issues.
The bulk of the talk explored the challenges of modern stream processing and used the Dataflow model alongside the corresponding practical implementation of this model in the Apache Beam API in order to ask four questions in order to understand the approaches required when processing data:
- What are you computing?
- Where in event time?
- When in processing time?
- How do refinements relate?
For the question “What are you computing?”, the answer may be element-wise (single-element) processing, perhaps a translation or filter — this is effectively the map part of the popular MapReduce paradigm — or it may be aggregating, such as a join or a count — this can be thought of as the reduce part of MapReduce. The answer to this question could also involve composite operations: these are operations that are made up of primitives, but we would like to think of them as conceptually simpler higher-level operations. The talk presented an example of using the Apache Beam API and pseudo Java code that computes integer sums from the exemplar mobile-phone game app. The PCollection abstraction represents a potentially distributed, multi-element data set: we can think of a PCollection as pipeline data, and Beam transforms use PCollection objects as inputs and outputs.
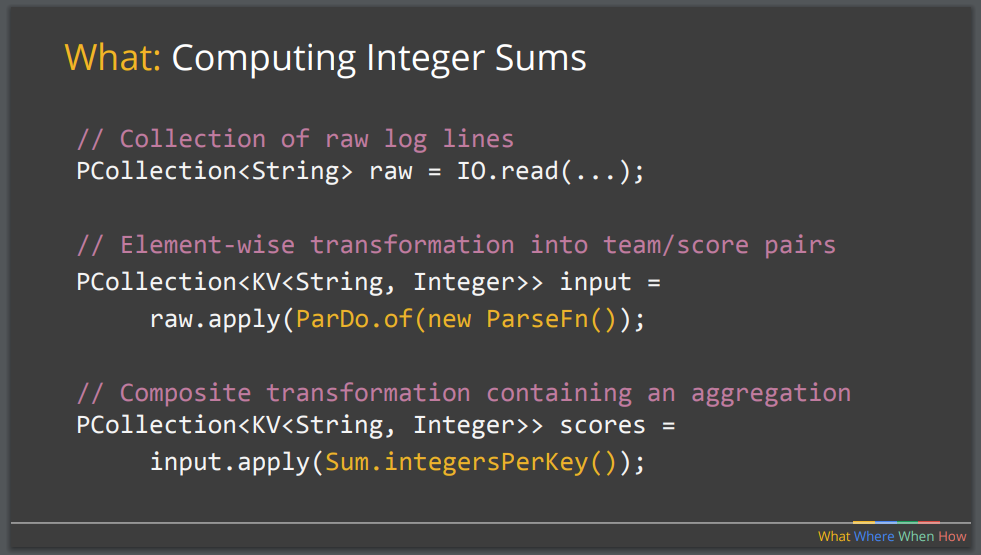
For the next question, “Where in event time?”, the typical approach is to use windowing to divide data into event-time-based finite chunks. These windows can be fixed (e.g., every five minutes), sliding (e.g., the previous 24 hours for every hour) or session-based (e.g., an application-specific burst of activity). Windowing is very similar to the concept of using a composite key to group data within batch processing.

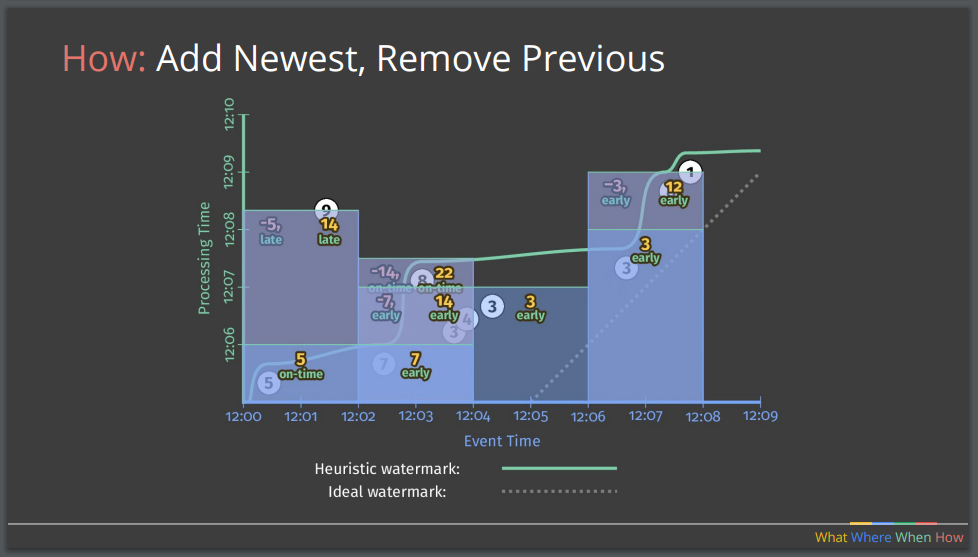
The third question, “When in processing time?”, relates to the requirements for triggers that control when results are emitted. Triggers are often relative to the watermark — when the watermark is seen, we believe that all the results for this event-time have been seen, and therefore the computation result can be emitted. If a perfect watermark is used, this can lead to the late emission of results as the system waits for all data elements to be processed before emitting any result. If a heuristic watermark is used, the results can be emitted in a more timely fashion, but the processing of late elements can provide additional challenges.
The issues with defining triggers can be mitigated by using early and late firings. An early firing can provide a speculative result at specific time periods — i.e., after every minute — and late firing allows results to be updated as late arriving data is processed. A key consideration when using early and late triggers relates to the fourth question, “How to make refinements (or updates) on speculative results?” Three tactics are available: discarding, simply throwing away any previous speculative results; accumulating, updating the result emitted for every update; or accumulating and retracting, updating the result emitted for every update but also issuing a retraction on the previous result. There are tradeoffs with each approach between the ease of implementation and the correctness of last observed and total observed values. This must be taken into account if, for example, a downstream service is performing multiple aggregations within a distributed pipeline — without the issuing of a retraction accompanying an update, the wrong result may be computed.
The final section of the talk examined properties that make the Apache Beam model of stream processing “awesome”. The first property discussed was correctness. It has historically been challenging to achieve correctness in a distributed stream-processing system; the very nature of a distributed system means that data will arrive with variable latency. However, modern stream-processing systems provide primitives to allow engineers to make tradeoffs between accuracy and result-emission latency. The second property is power. The Apache Beam API provides an engineer with powerful primitives and abstractions that can be implemented with relative ease. For example, the fluent-style Beam DSL allows easy swapping of approaches and algorithms, such as changing from a fixed window-aggregation strategy to a session-based one. This also relates to the third useful property of composability, as it is easy to compose new pipelines within the Beam API in order to test new hypothesis or experiment with the data. The final two properties, flexibility and modularity, allow various approaches to processing the data with minimal (and easily understandable) changes to code.
The concepts for Apache Beam evolved from the original 2004 MapReduce paper, which were in turn further refined at Google through the creation of internal systems like Bigtable, Dremel, Spanner, and MillWheel. Although Google focused on satisfying internal requirements with these systems, company engineers published a series of papers at conferences and within academic journals, and this led to the creation of a vibrant open-source ecosystem formed around these ideas. This in turn led to the creation of numerous successful open-source Apache projects like Hadoop, Drill, Spark, and Tez. In 2014, Google Cloud Platform began to offer Cloud Dataflow, which is a fully managed stream and batch data-processing service created based on the years of experience working on the internal data-processing systems. There were two parts to Cloud Dataflow: the Dataflow programming model discussed previously and the SDK, a “no knobs” managed service for executing the models. Google ultimately contributed the Dataflow model and SDK to the open-source community as the Apache Beam project.

The Apache Beam project includes three things:
- The conceptual Beam model
- The what/where/when/how model presented in the talk
- SDKs for writing Beam pipelines
- Runners for existing distributed processing back ends
Fundamentally, the Beam model attempts to generalize the semantics of this modern style of data processing and provides three core levels of abstraction for various personas within the data-processing community: end users who simply want to write data pipelines or transform libraries in a language that is either familiar to them or that their organization has invested in, SDK writers who want to make Beam concepts available in new languages, and runner writers who have a distributed processing environment and want to support Beam pipelines. It is worth noting that since not all runners offer the same capabilities (although many are converging), the Apache Beam project has created a series of runner capability matrices that provide further details.
Additional information on the topic of streaming fundamentals can be found in Akidau’s articles “The world beyond batch: Streaming 101” and “The world beyond batch: Streaming 102”. The Apache Beam website also contains many useful references and tutorials, and the Beam community offers user and developer mailing lists at user-subscribe@beam.apache.org and dev-subscribe@beam.apache.org.
The complete video for the talk Perry and Akidau presented at QCon SF, “Fundamentals of Stream Processing with Apache Beam”, can be found on InfoQ.
About the Author
 Daniel Bryant is leading change within organisations and technology. His current work includes enabling agility within organisations by introducing better requirement gathering and planning techniques, focusing on the relevance of architecture within agile development, and facilitating continuous integration/delivery. Daniel’s current technical expertise focuses on ‘DevOps’ tooling, cloud/container platforms and microservice implementations. He is also a leader within the London Java Community (LJC), contributes to several open source projects, writes for well-known technical websites such as InfoQ, DZone and Voxxed, and regularly presents at international conferences such as QCon, JavaOne and Devoxx.
Daniel Bryant is leading change within organisations and technology. His current work includes enabling agility within organisations by introducing better requirement gathering and planning techniques, focusing on the relevance of architecture within agile development, and facilitating continuous integration/delivery. Daniel’s current technical expertise focuses on ‘DevOps’ tooling, cloud/container platforms and microservice implementations. He is also a leader within the London Java Community (LJC), contributes to several open source projects, writes for well-known technical websites such as InfoQ, DZone and Voxxed, and regularly presents at international conferences such as QCon, JavaOne and Devoxx.