Key Takeaways
- A log — an append-only, totally ordered data structure — is a powerful primitive for building distributed systems. Many RDBMSs use change logs (or “write-ahead logs”) to improve performance, for point-in-time recovery (PITR) after a crash, and for distributed replication.
- The Amazon DynamoDB team exposed the underlying DynamoDB change log as DynamoDB Streams (a Kinesis Data Stream), which provides building blocks for end-user engineers to more efficiently implement several architectural trends that had been identified.
- Understanding ordering and deduplication is vital for building correct systems, particularly distributed systems. Implementing global ordering within a distributed system is generally not possible.
- It is not possible to obtain exactly once end-to-end delivery within a distributed system, although systems can be implemented to provide exactly once processing. This is typically implemented using checkpointing, deduplication, and idempotency filters.
- Checkpointing consists of maintaining a pointer that specifies the latest transaction that has been read or processed within a log, which indicates the current state of processing.
At QCon San Francisco 2016, Akshat Vig and Khawaja Shams presented “Demystifying DynamoDB Streams”. The core takeaway from the talk was that an append-only, totally ordered log data structure is a powerful primitive for building a distributed system, but engineers using this technology must understand the key principles of ordering, deduplication, and checkpointing. They explored these concepts in depth and provided practical examples using DynamoDB Streams, which is effectively an end-user service that exposes the underlying change log of the Amazon DynamoDB data-store technology.
Shams, VP of engineering at AWS Elemental, began the talk by discussing the longstanding relationship between relational-database technology and the log data structure. Many RDBMSs use change logs — such as MySQL’s binary log or PostgreSQL’s write-ahead log — to improve performance, provide point-in-time recovery (PITR) after a crash, and implement replication. A database change log also effectively allows the creation of a distributed database via replication of data on additional external hosts. For example, MySQL replicates data between a master and associated slave hosts through its binary log. Each slave maintains two threads for the process of replication: one to continually write a copy of the master binary log on the local slave’s disk and one to sequentially read through the log and apply each transaction to the local replicated copy of the database.
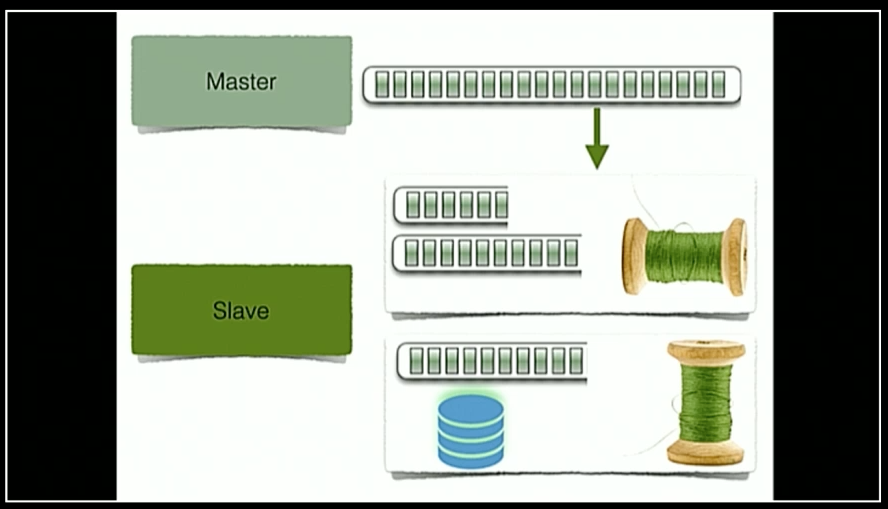
In order to build something even as simple as a master-slave replication, there are several primitives to understand. The first and foremost is ordering. Imagine if two transactions were to be applied sequentially to a database — the first writes a new entry and the second deletes this entry, which ultimately results in no data persisting in the database — but if the ordering is not guaranteed, the delete transaction could be processed first (causing no effect) and then the write transaction applied, which results in data incorrectly persisting in the database. The second core primitive is duplication: each single transaction should appear exactly once within the log. Failure to enforce ordering or prevent duplication within a log can result in the master and slave becoming inconsistent.
Shams posed the question of why these core primitives are important, given that not many engineers will be writing crash-recovery tooling or implementing distributed databases. He quickly pointed out that many engineers are indeed building distributed systems — such as those based on the microservices architecture — and often rely on log processing and event-driven architecture to share data, for example, via Apache Kafka or Amazon Kinesis. Accordingly, an awareness of these fundamental log-processing concepts is essential.
Vig, senior software engineer at AWS, discussed the concept of checkpointing. As the log is being processed, a pointer must be kept in order to specify the latest transaction that has been read or processed. In essence, this indicates the current state of processing. If the processing of the log is interrupted — for example, by a crash in the consuming system — the current checkpoint can be examined and processing resumed from the indicated transaction. This not only prevents extra work but also attempts to ensure accuracy by preventing the reprocessing of transactions that have already been seen.
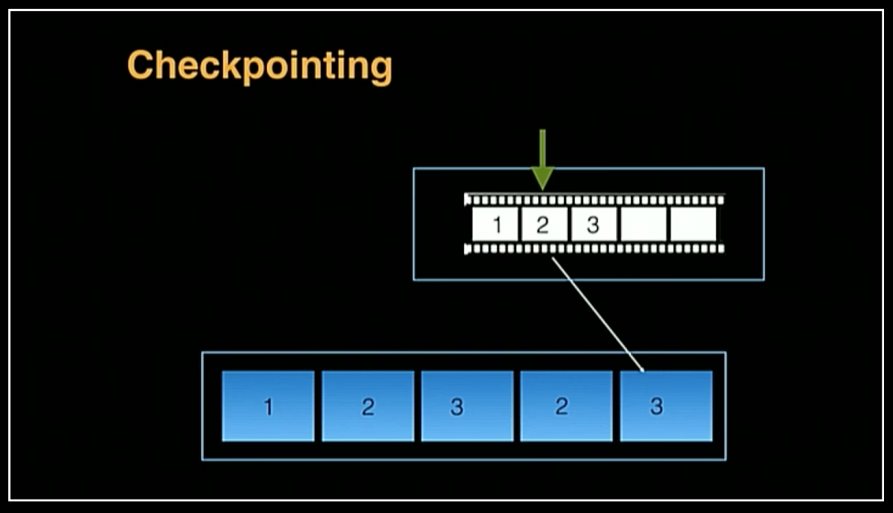
There are multiple strategies to checkpointing, each of which is a trade-off between specificity and throughput. For example, checkpointing after every transaction is processed provides a specific pointer to the last read item, but is high cost in that it requires a checkpoint write for every item. Checkpointing after every, say, 10 reads is less specific to the exact item that has most recently been processed but requires an order of magnitude less cost in checkpoint writes.
On the other hand, the larger the number of transactions that occur between checkpoints, the more transactions that have to be read (and processed) if a crash does occur. Not only does this take time but, Shams cautioned, in some systems it may be unacceptable to reprocess transactions (which could give the impression of going back through time) and therefore the only strategy in this case is to checkpoint every processed transaction.
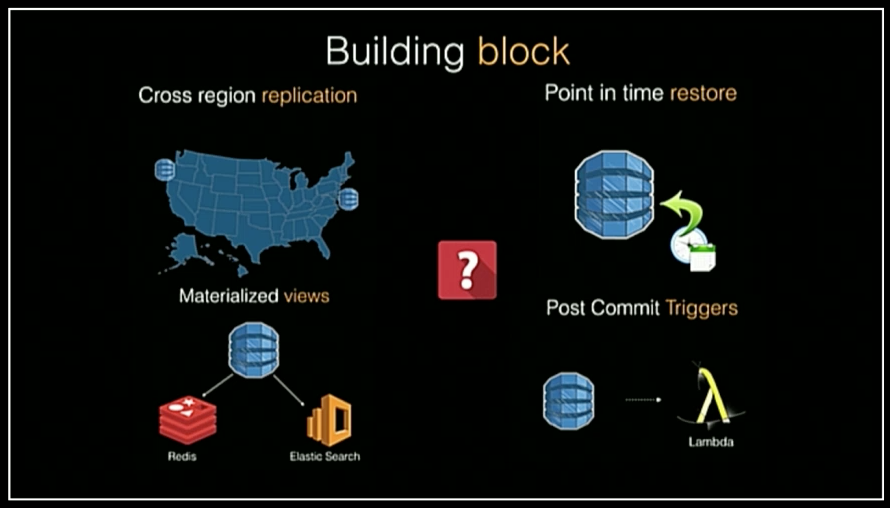
Vig presented a series of trends that the AWS team has identified within current software architectures. The first, optimizing global latency, occurs when engineers attempt to provide a consistent experience across different geographic regions — for example, by implementing cross-region replication of data. There are multiple approaches to implementing this; for example, engineers can build the geo-replication logic directly into the application, or transactions can be written to a distributed queue before being processed independently within each geographic region. However, none of these implementations is trivial, and the complexity increases as the transaction throughput and number of supported geographic regions increases.
The second trend, protection of logical corruption, is an attempt by engineers to prevent application-level issues that are not physical in nature — for example, if a new release of an application incorrectly mutates data by accident, the system should be able to recover. Typical approaches to this include using PITR snapshots or delayed replicas that maintain a live copy of a data store at various points in time (for example, multiple live standby databases of one running one hour in the past, a second running two hours in the past, etc.). There is obviously an operational cost to implementing and maintaining both of these approaches.
The third trend AWS detected within modern architectures is the requirement for flexible querying of data: engineers frequently want both online transaction processing (OLTP) and online analytical processing (OLAP) queries on data within a system. Storing the single source of truth within a log allows the processing of data multiple times, and the data can also materialize in a variety of ways. This can often be seen within event sourcing (ES) and command-query responsibility segregation (CQRS) architectures, by which data materializes using a data-store technology most appropriate to each query use case — for example, using a graph database for queries involving connectedness or shortest-path algorithms in combination with a RDMS for relational queries and a key-value store for direct identifier-driven lookups.
The fourth trend Vig discussed was the rise in popularity of event-driven architectures (EDA), in which engineers are increasingly building systems that process streams of events, potentially in parallel. An example of this style of architecture can be seen within function-as-a-service (FaaS) serverless applications, in which engineers write functions that are triggered by an event, such as a write to an object store or a request from an API gateway.
The presentation shifted gears in the second half as Shams and Vig discussed how the DynamoDB team at AWS attempted to provide building blocks that end-user engineers could use to implement solutions that address the trends identified above. The solution was AWS DynamoDB Streams, which essentially exposes the change log of DynamoDB to engineers as an Amazon Kinesis Stream. Following the principles discussed earlier in the presentation, DynamoDB Streams are highly available, durable, ordered and deduplicated. It is worth noting that at the 2017 AWS re:Invent conference, Amazon announced end-user services for DynamoDB cross-region replicated Global Tables and automated on-demand DynamoDB backup, presumably built using these primitives.
Shams and Vig presented a sample voting application that was built using DynamoDB Streams. Optimistic concurrency can be implemented within systems built upon DynamoDB by using the put if not exists command. In the voting application, this could be used to prevent duplicate votes, perhaps those occurring by accident via a logical error within the application. If the put if not exists command detects an attempt to make a duplicate write then this write would fail and no corresponding DynamoDB Stream entry would be generated. A conditional put could be used to allow a voter to change their vote within the application, where the condition specified would be a different candidate ID. If the condition is satisfied, then the new write (the vote update) would succeed, and a DynamoDB Stream entry would be generated that contains both the updated NewImage and the previous OldImage data.

When processing a DynamoDB Stream using Kinesis, the application should checkpoint the logs using the Kinesis client library. As Shams and Vig had noted earlier, this can be used to prevent re-processing of data. Shams cautioned that implementing global ordering within a distributed system is only possible if a single process within the system generates a unique sequence number, and this typically limits throughput. An application can attempt to implement global ordering using timestamps, but this assumes that all processes within the system have access to a reliable and uniformly configured clock. This is generally considered an unreasonable assumption, but it is worth noting that AWS have recently released the Amazon Time Sync Service, which provides a “highly accurate and reliable time reference that is natively accessible from Amazon EC2 instances”.
Implementing partial ordering within a system — ordering for each individual item within a DynamoDB table — is, however, relatively simple, as mutations for an individual item are written to the same shard within Kinesis. As long as the application processes data in order within a shard, this will be sufficient.
Vig concluded the talk by stating that it is possible to consume DynamoDB Streams using at-most once or at-least once semantics, but not exactly once. It is not possible to obtain exactly once end-to-end delivery within a distributed system, although systems can be implemented to provide exactly once processing. This is typically implemented using deduplication or idempotency filters.
The full video for Shams and Vig’s QCon SF 2016 presentation “Demystifying DynamoDB Streams” can be found on InfoQ.
About the Author
 Daniel Bryant is leading change within organisations and technology. His current work includes enabling agility within organisations by introducing better requirement gathering and planning techniques, focusing on the relevance of architecture within agile development, and facilitating continuous integration/delivery. Daniel’s current technical expertise focuses on ‘DevOps’ tooling, cloud/container platforms and microservice implementations. He is also a leader within the London Java Community (LJC), contributes to several open source projects, writes for well-known technical websites such as InfoQ, DZone and Voxxed, and regularly presents at international conferences such as QCon, JavaOne and Devoxx.
Daniel Bryant is leading change within organisations and technology. His current work includes enabling agility within organisations by introducing better requirement gathering and planning techniques, focusing on the relevance of architecture within agile development, and facilitating continuous integration/delivery. Daniel’s current technical expertise focuses on ‘DevOps’ tooling, cloud/container platforms and microservice implementations. He is also a leader within the London Java Community (LJC), contributes to several open source projects, writes for well-known technical websites such as InfoQ, DZone and Voxxed, and regularly presents at international conferences such as QCon, JavaOne and Devoxx.