Key Takeaways
- There are many decisions and tradeoffs that must be made when moving from batch ETL to stream data processing. Engineers should not "stream all the things" just because stream processing technology is popular
- The Netflix case study presented here migrated to Apache Flink. This technology was chosen due to the requirements for real-time event-based processing and extensive support for customisation of windowing
- Many challenges were encountered during the migration, such as getting data from live sources, managing side (metadata) inputs, handling data recovery and out of order events, and increased operational responsibility
- There were clear business wins for using stream processing, including the opportunity to train machine learning algorithms with the latest data
- There were also technical wins for implementing stream processing, such as the ability to save on storage costs, and integration with other real-time systems
At QCon New York 2017, Shriya Arora presented “Personalizing Netflix with Streaming Datasets” and discussed the trials and tribulations of a recent migration of a Netflix data-processing job from the traditional approach of batch-style ETL to stream processing using Apache Flink.
Arora, a senior data engineer at Netflix, began by stating that the key goal of the presentation was to help the audience decide if a stream-processing data pipeline would help resolve problems they may be experiencing with a traditional extract-transform-load (ETL) batch processing job. In addition to this, she discussed core decisions and tradeoffs that must be made when moving from batch to streaming. Arora was clear to stress that “batch is not dead”, and although there are many stream-processing engines, there is no single best solution.
Netflix’s core mission is to entertain customers by allowing them to watch personalized video content anywhere at anytime. In the course of providing this personalized experience, Netflix processes 450 billion unique events daily from 100+ million active members in 190 different countries who view 125 million hours of content per day. The Netflix system uses the microservice architectural style and services communicate via remote procedure call (RPC) and messaging. The production system has a large Apache Kafka cluster with 700+ topics deployed that manages messaging and also feeds the data-processing pipeline.
Within Netflix, the Data Engineering and Analytics (DEA) team and Netflix Research are responsible for running the personalization systems. At a high level, microservice application instances emit user and system-driven data events that are collected within the Netflix Keystone data pipeline — a petabyte-scale real-time event streaming-processing system for business and product analytics. Traditional batch data processing is conducted by storing this data within a Hadoop Distributed File System (HDFS) running on the Amazon S3 object storage service and processing with Apache Spark, Pig, Hive, or Hadoop. Batch-processed data is stored within tables or indexers like Elasticsearch for consumption by the research team, downstream systems, or dashboard applications. Stream processing is also conducted by using Apache Kafka to stream data into Apache Flink or Spark Streaming.
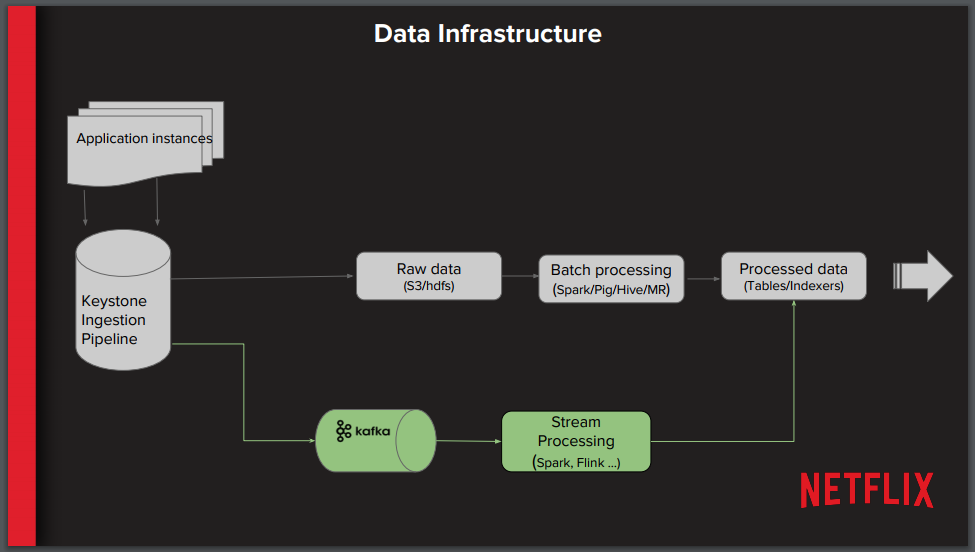
Before discussing her team’s decision to convert a long-running batch ETL job into a streaming process, Arora cautioned the audience against “streaming all the things”. There are clear business wins for using stream processing, including the opportunity to train machine-learning algorithms with the latest data, provide innovation in the marketing of new launches, and create opportunities for new kinds of machine-learning algorithms. There are also technical wins, such as the ability to save on storage costs (as raw data does not need to be stored in its original form), faster turnaround time on error correction (long-running batch jobs can incur significant delays when they fail), real-time auditing on key personalization metrics, and integration with other real-time systems.
A core challenge when implementing stream processing is picking an appropriate engine. The first key question to ask is will the data be processed as an event-based stream or in micro-batches. In Arora’s opinion, micro-batching is really just a subset of batch processing — one with a time window that may be reduced from a day in typical batch processing to hours or minutes — but a process still operating on a corpus of data rather than actual events. If results are simply required sooner than currently provided, and the organization has already invested heavily in batch, then migrating to micro-batching could be the most appropriate and cost-effective solution.
The next challenge in picking a stream-processing engine is to ask what features will be most important in order to solve the problem being tackled. This will most likely not be an issue that is solved in an initial brainstorming session — often a deep understanding of the problem and data only emerge after an in-depth investigation. Arora’s case study required “sessionization” (session-based windowing) of event data. Each engine supports this feature to varying degrees with varying mechanisms. Ultimately, Netflix chose Apache Flink for Arora’s batch-job migration as it provided excellent support for customization of windowing in comparison with Spark Streaming (although it is worth mentioning that new APIs supporting Spark Structured Streaming and advanced session handling have become stable as of Apache Spark 2.2.0, which was released in July 2017, after this presentation was delivered).
Another question to ask is whether the implementation requires the lambda architecture. This architecture is not to be confused with AWS Lambda or serverless technology in general — in the data-processing domain, the lambda architecture is designed to handle massive quantities of data by taking advantage of both batch-processing and stream-processing methods. This approach to architecture attempts to balance latency, throughput, and fault-tolerance by creating a batch layer that provides a comprehensive and accurate “correct” view of batch data, while simultaneously implementing a speed layer for real-time stream processing to provide potentially incomplete, but timely, views of online data. It may be the case that an existing batch job simply needs to be augmented with a speed layer, and if this is the case then choosing a data-processing engine that supports both layers of the lambda architecture may facilitate code reuse.

Several additional questions to ask when choosing a stream-processing engine include:
- What are other teams using within your organization? If there is a significant investment in a specific technology, then existing implementation and operational knowledge can often be leveraged.
- What is the landscape of the existing ETL systems within your organization? Will a new technology easily fit in with existing sources and sinks?
- What are your requirements for learning curve? What engines do you use for batch processing, and what are the most widely adopted programming languages?
The penultimate section of the talk examined the migration of a Netflix batch ETL job to a stream-processing ETL process. The Netflix DEA team previously analyzed sources of play and sources of discovery within the Netflix application using a batch-style ETL job that can take longer than eight hours to complete. Sources of play are the locations from the Netflix application homepage from which users initiate playback. Sources of discovery are the locations on the homepage where users discover new content to watch. The ultimate goal of the DEA team was to learn how to optimize the homepage to maximize discovery of content and playback for users, and to improve the overly long 24-hour latency between occurring events and analysis. Real-time processing could shorten this gap between action and analysis.
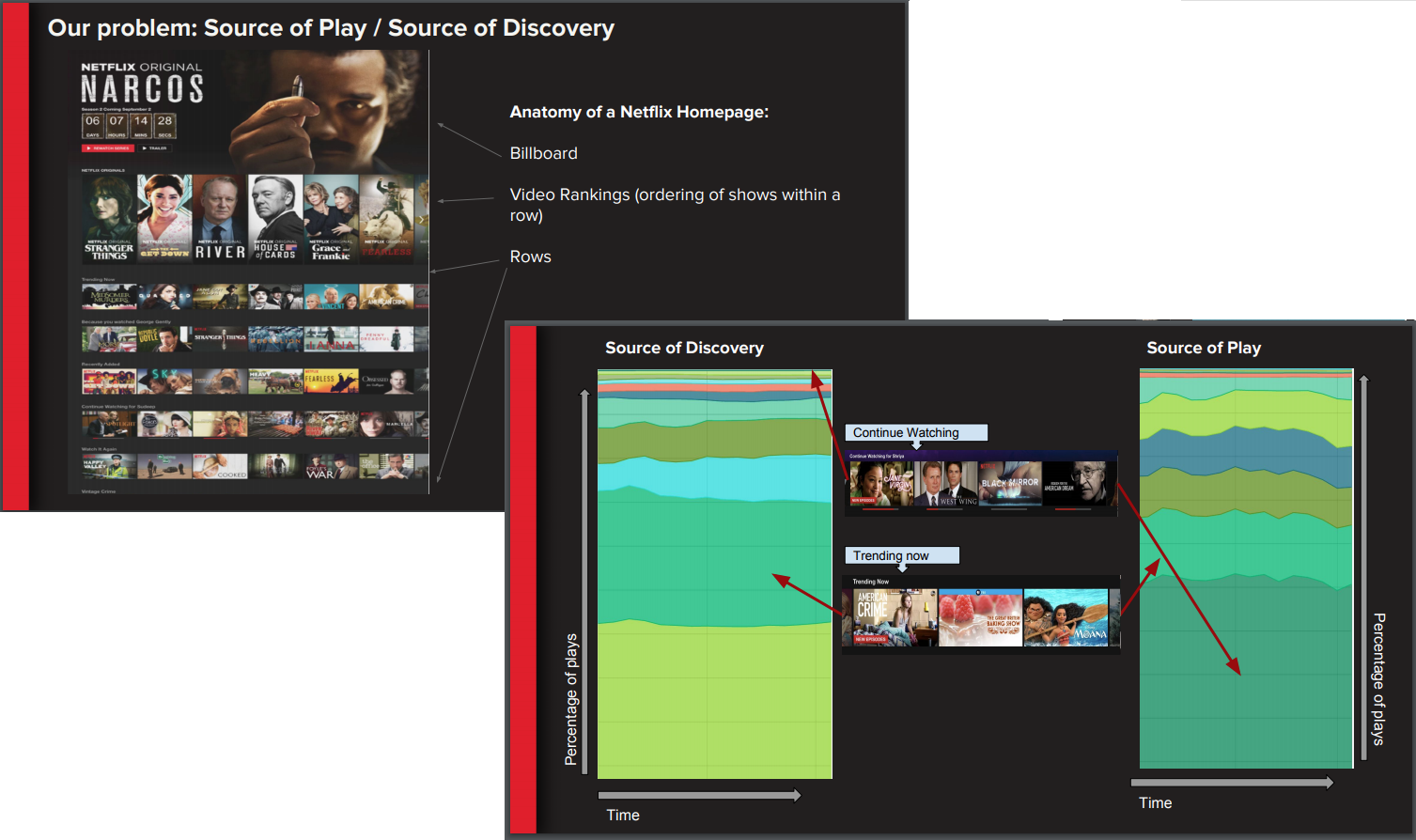
Examining the “source of discovery” problem in more depth revealed to Netflix that the stream-processing engine to choose had to be able to: handle a high throughput of data (users across the globe currently generate ~100 million discovery/playback events per day); communicate to live microservices via thick (RPC-style) clients in order to enrich the initial events; integrate with the Netflix platform ecosystem such as, for example, service discovery; have centralized log management and alerting; and allow side inputs of slowly changing data (e.g., a dimension or metadata table containing film metadata or country demographics).
Ultimately, Arora and her team chose Apache Flink with an ensemble cast of supporting technology:
- Apache Kafka acting as a message bus;
- Apache Hive providing data summarization, query, and analysis using an SQL-like interface (particularly for metadata in this case);
- Amazon S3 for storing data within HDFS;
- the Netflix OSS stack for integration into the wider Netflix ecosystem;
- Apache Mesos for job scheduling and execution; and
- Spinnaker for continuous delivery.
An overview of the complete source of discovery pipeline can be seen below.
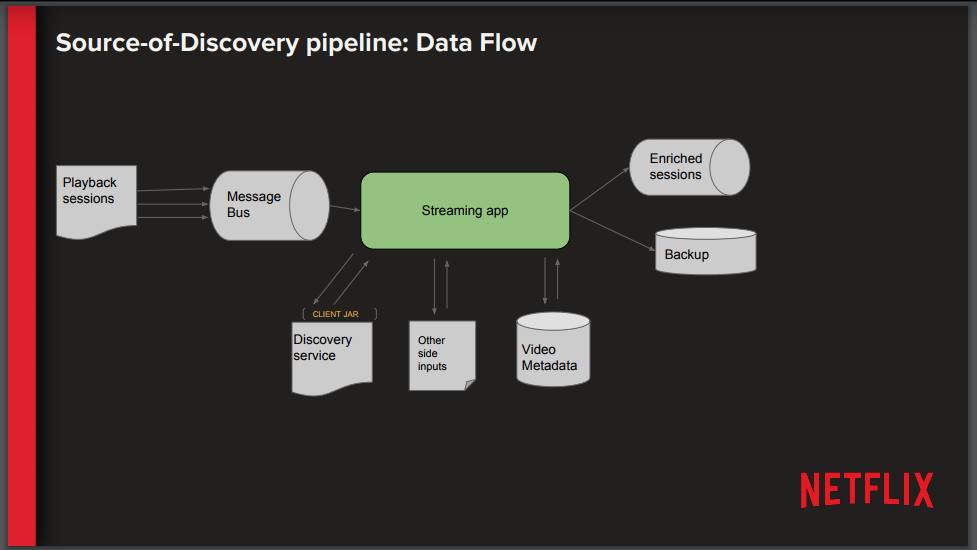
Arora outlined the implementation challenges that the DEA team faced with the migration process:
- Getting data from live sources:
- The job being migrated required access to the complete viewing history of the user of every playback initiation event.
- This was conceptually easy to implement with stream processing, as the integration with the Netflix stack and real-time nature of the data processing meant that a simple RPC-like call was required for each event as it was processed.
- However, because the Apache Flink stream-processing application was written using the Java API and the Netflix OSS stack is also written using Java, it was sometimes challenging to ensure compatibility between libraries within both applications (managing so-called “JAR hell”).
- Side inputs:
- Each item of metadata required within the stream-processing job could have been obtained by making a call in the same fashion as getting data from live sources.
- However, this would require many network calls, and ultimately be a very inefficient use of resources.
- Instead the metadata was cached into memory for each stream-processing instance, and the data refreshed every 15 minutes.
- Data recovery:
- When a batch job fails due to an infrastructure issue, it is easy to rerun the job, as the data is still stored within the underlying object store — i.e., HDFS. This is not necessarily the case with stream processing, as the original events can be discarded as they are processed.
- Within the Netflix ecosystem, the TTLs of the message bus (Kafka) that stores the original events can be relatively aggressive — due to the volume, as little as four to six hours. Accordingly, if a stream-processing job fails and this is not detected and fixed within the TTL time limit, data loss can occur.
- The solution for this issue was to additionally store the raw data in HDFS for a finite time (one to two days) in order to facilitate replay.
- Out-of-order events:
- In the event of a pipeline failure, the data-recovery process (and reloading of events) will mean that “old” data will be mixed in with real-time data.
- The challenge is that late-arriving data must be attributed correctly to the event time at which it was generated.
- The DEA team chose to implement time windowing and also post-process data to ensure that the results are emitted with the correct event-time context.
- Increased monitoring and alerts:
- In the event of a pipeline failure, the team must be notified as soon as possible.
- Failure to trigger a timely alert can result in data loss.
- Creating an effective monitoring, logging, and alerting implementation is vital.
Arora concluded the talk by stating that although the business and technical wins for migrating from batch ETL to stream processing were numerous, there were also many challenges and learning experiences. Engineers adopting stream processing should be prepared to pay a pioneer tax, as most conventional ETL is batch and training machine-learning models on streaming data is relatively new ground. The data processing team will also be exposed to high-priority operational issues — such as being on call and handling outages — as although “batch failures have to be addressed urgently, streaming failures have to be addressed immediately”. An investment in resilient infrastructure must be made, and the team should also cultivate effective monitoring and alerting, and create continuous-delivery pipelines that facilitate the rapid iteration and deployment of the data-processing application.
The full video of Arora’s QCon New York 2017 talk “Personalizing Netflix with Streaming Datasets” can be found on InfoQ.
About the Author
 Daniel Bryant is leading change within organisations and technology. His current work includes enabling agility within organisations by introducing better requirement gathering and planning techniques, focusing on the relevance of architecture within agile development, and facilitating continuous integration/delivery. Daniel’s current technical expertise focuses on ‘DevOps’ tooling, cloud/container platforms and microservice implementations. He is also a leader within the London Java Community (LJC), contributes to several open source projects, writes for well-known technical websites such as InfoQ, DZone and Voxxed, and regularly presents at international conferences such as QCon, JavaOne and Devoxx.
Daniel Bryant is leading change within organisations and technology. His current work includes enabling agility within organisations by introducing better requirement gathering and planning techniques, focusing on the relevance of architecture within agile development, and facilitating continuous integration/delivery. Daniel’s current technical expertise focuses on ‘DevOps’ tooling, cloud/container platforms and microservice implementations. He is also a leader within the London Java Community (LJC), contributes to several open source projects, writes for well-known technical websites such as InfoQ, DZone and Voxxed, and regularly presents at international conferences such as QCon, JavaOne and Devoxx.