Pontos Principais
- Existem muitas decisões e concessões que devem ser pensadas quando se muda o processamento de lotes por ETL para transmissão (streaming) de dados. Os engenheiros não devem "transmitir todas as coisas" apenas porque a tecnologia de processamento de fluxo é popular.
- O estudo de caso da Netflix apresentado aqui migrou para o Apache Flink. Essa tecnologia foi escolhida devido aos requisitos para processamento em tempo real baseado em eventos e suporte extensivo para personalização de janelas
- Muitos desafios foram encontrados durante a migração, como obter dados de fontes vivas, gerenciar entradas laterais (metadados), lidar com recuperação de dados, eventos fora de ordem e aumentar a responsabilidade operacional.
- Houve ganhos de negócios claros para usar o processamento de fluxo, incluindo a oportunidade de treinar o aprendizado de algoritmos de máquina com os dados mais recentes.
- Também houve ganhos técnicos para implementar o processamento de fluxo, como a capacidade de economizar em custos de armazenamento e a integração com outros sistemas em tempo real.
No QCon New York 2017, Shriya Arora falou sobre "Personalising Netflix with Streaming Datasets" e discutiu as experiências e as adversidades de uma recente migração de uma rotina de processamento de dados Netflix a partir da abordagem tradicional de ETL do estilo em lote para processamento de fluxo usando Apache Flink.
Arora é engenheira de dados sênior na Netflix e começou falando que o seu objetivo principal na apresentação era ajudar o público a decidir quando um pipeline de dados de processamento de fluxo (stream) ajudariam a resolver os possíveis problemas vivenciados em um extract-transform-load (ETL) tradicional de processamento em lote. Além disso, ela argumentou sobre as decisões básicas e os compromissos que devem ser feitos ao passar do lote para o streaming. Arora mostrou claramente ao destacar que "o lote não está morto", e embora existam muitos mecanismos de processamento de fluxo, não há uma única solução que seja a melhor.
A missão principal do Netflix é entreter os clientes permitindo que eles vejam conteúdo de vídeo personalizado em qualquer lugar, a qualquer momento. No fornecimento dessa experiência personalizada, o Netflix processa 450 bilhões de eventos únicos diariamente de mais de 100 milhões de membros ativos em 190 diferentes países que visualizam 125 milhões de horas de conteúdo por dia. O sistema do Netflix utiliza a arquitetura de microservice e os serviços se comunicam via chamada de procedimento remoto (RPC) e mensagens. O sistema de produção possui um grande cluster Apache Kafka com mais de 700 tópicos implantados que gerenciam mensagens e também alimentam o pipeline de processamento de dados.
Dentro do Netflix, os times de Engenheiros de dados analiticos (DEA) e o Netflix Research são responsáveis pela execução dos sistemas de personalização. Em um nível elevado, as instâncias de aplicações de microservice emitem eventos em que os dados do usuário e do sistema são coletados dentro de uma pipeline de dados no Netflix Keystone - um sistema de processamento de fluxo de eventos em tempo real numa escala de petabyte para análise de negócios e produtos. O processamento tradicional dos dados em lotes é realizado e armazenado em um sistema de arquivos distribuídos Hadoop (HDFS) executado no serviço de armazenamento de objetos do Amazon S3 e processado pelo Apache Spark, Pig, Hive ou Hadoop. Os dados processados em lote são armazenados em tabelas e/ou em indexadores como o Elasticsearch para que sejam consumidos pela equipe de pesquisa, sistemas downstream ou aplicações de painel de controle. O processamento desse fluxo também é realizado usando o Apache Kafka para transmitir dados no Apache Flink ou Spark Streaming.
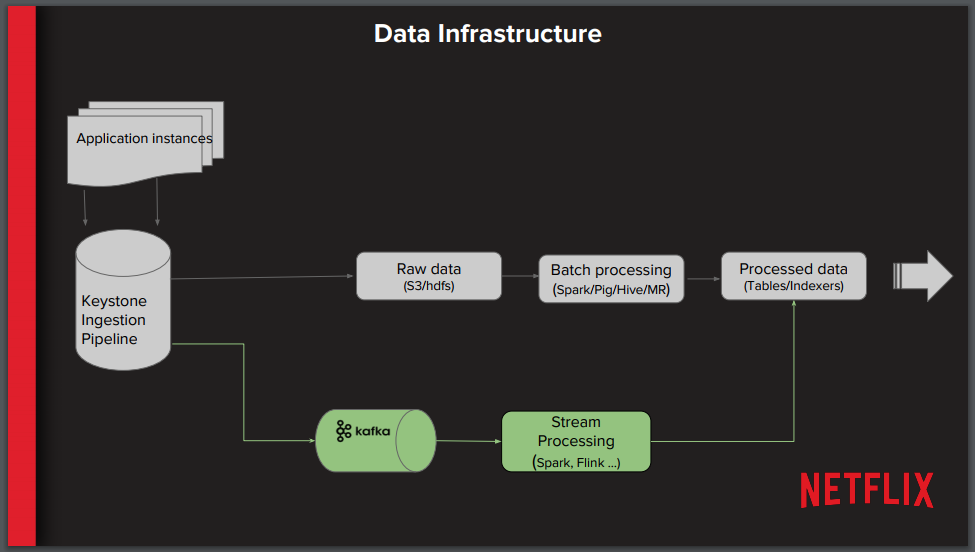
Antes de discutir sobre a decisão de sua equipe em converter uma rotina ETL em lote de longa duração para um processo de transmissão (streaming), Arora advertiu ao público para não "transmitir todas as coisas". Há ganhos de negócios claros por usar o processamento em fluxo, incluindo a oportunidade de treinar os algoritmos de aprendizagem de máquina com os dados mais recentes, oferecer inovação no marketing de novos lançamentos e criar oportunidades para novos tipos de algoritmos de aprendizagem. Há também ganhos técnicos, como a capacidade de economizar no custo de armazenamento (uma vez que os dados brutos não precisam ser armazenados em sua forma original), um tempo de resposta mais rápido na correção dos erros (os trabalhos em lotes de longa duração podem sofrer atrasos significativos quando falham), auditoria em tempo real de métricas de personalização chave e integração com outros sistemas de tempo real.
Um dos desafios centrais ao implementar o processamento em fluxo é escolher o mecanismo apropriado. A primeira questão-chave é perguntar se os dados serão processados como um fluxo baseado em eventos ou em micro-lotes. Na opinião de Arora, os micro-lotes são apenas um subconjunto do processamento em lote - com uma janela de tempo que pode ser reduzida de um dia no processamento típico para horas ou minutos - mas um processo ainda está funcionando em um conjunto de dados ao invés dos eventos reais. Se os resultados forem simplesmente exigidos com mais rapidez do que são fornecido atualmente, e caso a organização já tenha investido fortemente nos lotes, a migração para micro-lotes pode ser a solução mais adequada e econômica.
O próximo desafio na escolha de um mecanismo de processamento em fluxo é perguntar quais são os recursos mais importantes para resolver o problema abordado. Isso provavelmente não será um problema que se resolverá em apenas uma sessão inicial de brainstorming - muitas vezes necessitam de uma compreensão profunda do problema e uma imersão nos dados para uma investigação aprofundada. O estudo de caso de Arora exigiu a "sessão da sessão" (janela de sessões) de dados de eventos. Cada mecanismo suporta este recurso em graus variados com mecanismos diferenciados. Em uma última análise, o Netflix escolheu o Apache Flink para a migração das rotinas de lote, pois forneceu um excelente suporte para a personalização de janelas em comparação com o Spark Streaming (embora seja importante mencionar que as novas APIs que suportam Spark Structured Streaming e o gerenciamento avançado de sessões tornaram-se estáveis a partir do Apache Spark 2.2.0, que foi lançado em julho de 2017, após esta apresentação).
Outra questão a ser analisada é se a implementação requer uma arquitetura lambda. Esta arquitetura não deve ser confundida com AWS Lambda ou tecnologia sem servidor (serverless) em geral - no domínio do processamento de dados, a arquitetura lambda é projetada para lidar com grandes quantidades de dados, aproveitando os métodos de processamento em lote e processamento de fluxo. Essa abordagem, arquiteta tentativas de equilibrar a latência, a taxa de transferência e a tolerância a falhas criando uma camada de lote que fornece uma visão "correta e precisa" dos dados do lote, ao mesmo tempo em que implementa uma camada de velocidade para o processamento de fluxo em tempo real para fornecer mesmo que potencialmente incompleta, mas oportuna, pontos de vista dos dados on-line. Pode ser que uma rotina em lote existente simplesmente precise ser aumentada com uma camada de velocidade e, se for esse o caso, escolher um mecanismo de processamento de dados que suporte ambas as camadas da arquitetura lambda podendo facilitar a reutilização do código.

Várias são as perguntas adicionais a serem realizadas ao se escolher um mecanismo de processamento de fluxo:
- O que outras equipes utilizam dentro da sua organização? Se houver um investimento significativo em uma tecnologia específica, a implementação e o conhecimento operacional existentes podem ser alavancados.
- Qual é o cenário dos sistemas ETL existentes dentro da sua organização? Será que uma nova tecnologia se encaixa facilmente com os recursos existentes?
- Quais são os seus requisitos de curva de aprendizado? Quais os mecanismos que você usa para o processamento em lote e quais são as linguagens de programação mais adotadas?
A penúltima seção da palestra examinou a migração de uma rotina ETL em lote Netflix para um processo ETL em fluxo. A equipe da Netflix DEA analisou anteriormente as fontes de reprodução e as fontes de descoberta dentro do aplicativo do Netflix usando uma rotina ETL de estilo em lote que poderia levar mais de oito horas para ser concluído. As fontes de reprodução foram os locais da página inicial do aplicativo Netflix a partir dos quais os usuários iniciam a reprodução. As fontes de descoberta foram os locais na página onde os usuários descobrem novos conteúdos para assistir. O objetivo final da equipe da DEA foi aprender a otimizar a página inicial para maximizar a descoberta de conteúdo reproduzido para os usuários e melhorar a latência excessiva ao longo de 24 horas entre os eventos ocorridos e as análises. O processamento em tempo real pode encurtar essa lacuna entre a ação e a análise.
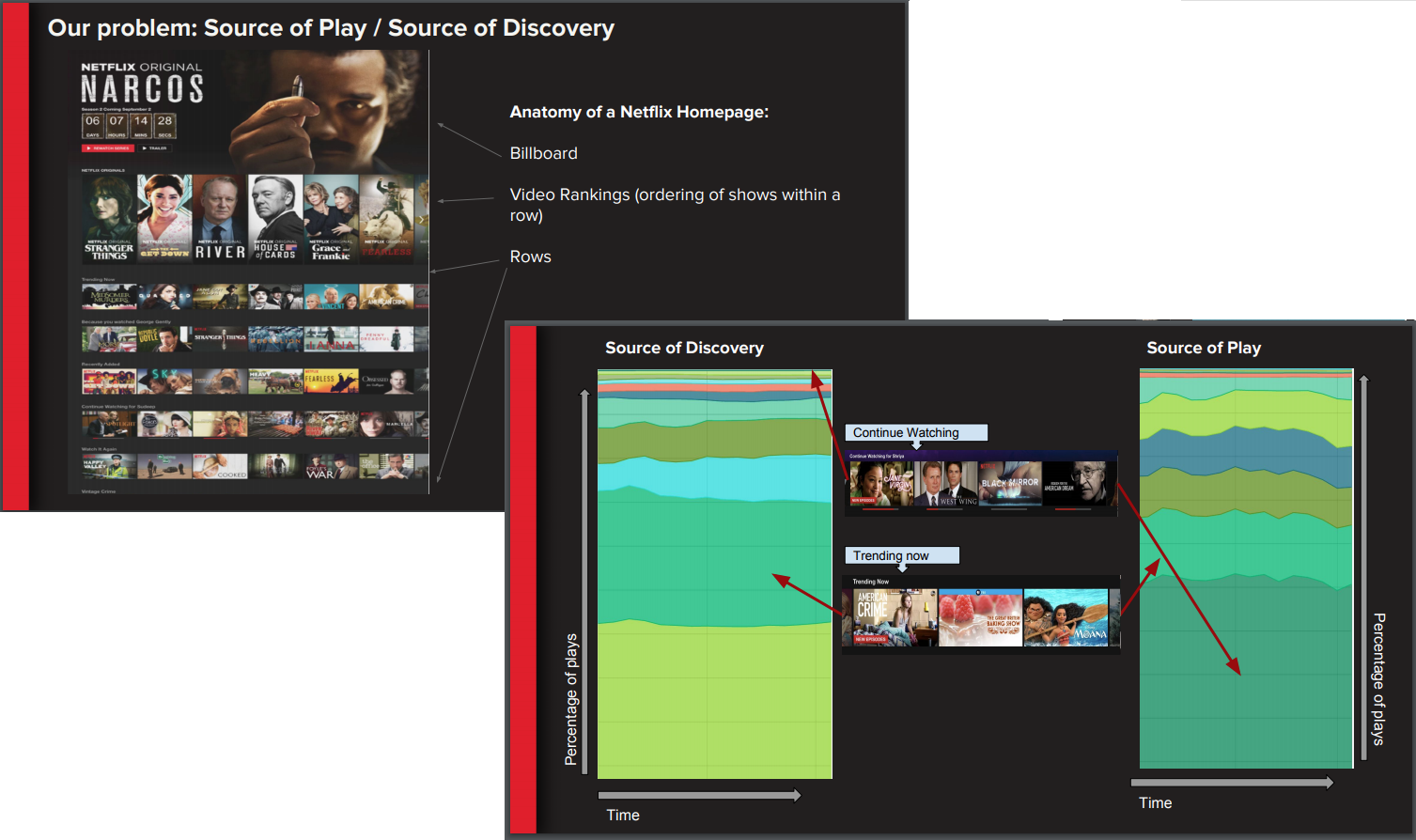
Examinando o problema de "descobrir a fonte" numa maior escala, revelou-se à Netflix que o mecanismo de processamento de fluxo a ser escolhido deveria ser capaz de: lidar com um alto fluxo de dados (usuários em todo o mundo geram atualmente ~100 milhões de eventos de descoberta/reprodução por dia); comunicar-se com os microservices através dos densos clientes (estilo RPC) para enriquecer os eventos iniciais; integrar-se ao ecossistema da plataforma Netflix, como por exemplo, a descoberta de serviço; ter um gerenciamento centralizado de log e alerta; e permitir entradas laterais de dados que mudam lentamente (por exemplo, uma dimensão ou tabela de metadados contendo metadados de filmes ou dados demográficos do país).
Em sua análise final, Arora e sua equipe escolheram o Apache Flink com um elenco de tecnologia de suporte:
- Apache Kafka agindo como um barramento de mensagens;
- Apache Hive, fornecendo resumo, consulta e análise de dados usando uma interface semelhante ao SQL (particularmente para metadados neste caso);
- Amazon S3 para armazenar dados dentro do HDFS;
- A pilha Netflix OSS para integração no ecossistema Netflix mais amplo;
- Apache Mesos para programação e execução de trabalhos;
- Spinnaker para entrega continua.
Uma visão geral da fonte completa de pipeline de descoberta pode ser vista abaixo.
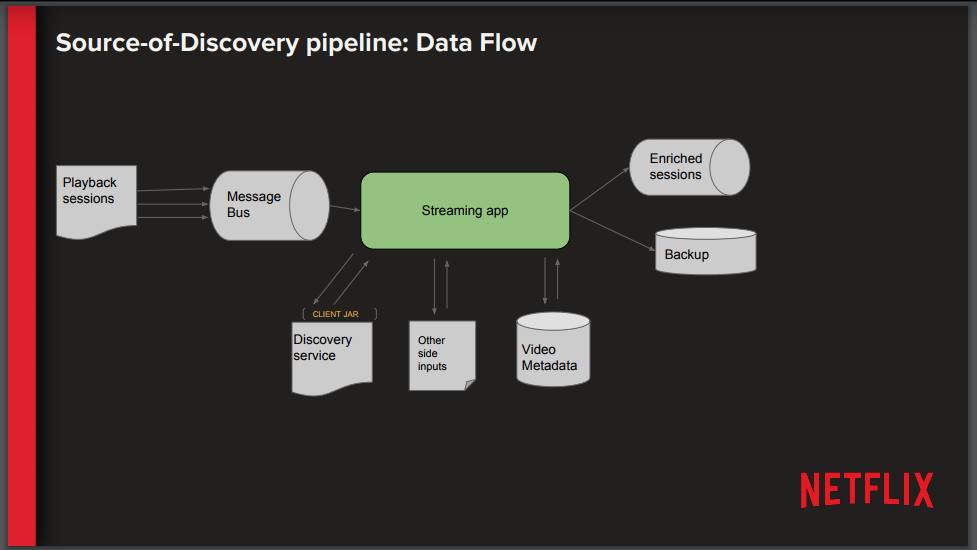
Arora descreveu os desafios de implementação que a equipe da DEA enfrentou com o processo de migração:
- Obtendo dados de fontes ao vivo:
- O trabalho que está sendo migrado requer o acesso ao histórico de visualização completo do usuário de cada evento de inicialização e reprodução.
- Isso foi conceitualmente fácil de implementar com o processamento de fluxo, pois a integração com a pilha Netflix e a natureza em tempo real do processamento de dados significava que uma simples chamada de RPC era necessária para cada evento conforme foi processada.
- No entanto, como o aplicativo de processamento de fluxo do Apache Flink, foi escrito usando a API Java e a pilha Netflix OSS também foi escrita usando Java, as vezes era desafiador assegurar a compatibilidade entre as bibliotecas dentro de ambas as aplicações (gerenciando o chamado "inferno JAR").
- Entradas laterais:
- Cada item de metadados requerido no trabalho de processamento de fluxo poderia ter sido obtido fazendo uma chamada da mesma maneira que obter dados de fontes vivas.
- No entanto, isso exigiria muitas chamadas de rede e, finalmente, seria um uso muito ineficiente de recursos.
- Ao invés disso, os metadados foram armazenados em cache na memória para cada instância de processamento de fluxo, e os dados atualizados a cada 15 minutos.
- Recuperação de dados:
- Quando um trabalho em lote falha devido a um problema de infraestrutura, é fácil executar o trabalho, pois os dados ainda estão guardados no armazenamento de objeto subjacente - ou seja, o HDFS. Este não é necessariamente o caso do processamento de fluxo, pois os eventos originais podem ser descartados à medida que são processados.
- Dentro do ecossistema Netflix, os TTLs do barramento de mensagens (Kafka) que armazenam os eventos originais podem ser relativamente agressivos - devido ao volume de apenas quatro a seis horas. Consequentemente, se um trabalho de processamento de fluxo falhar e isso não for detectado e corrigido dentro do limite de tempo TTL, pode ocorrer a perda de dados.
- A solução para essa questão foi armazenar os dados brutos no HDFS por um tempo finito (um a dois dias) para facilitar a reprodução.
- Eventos fora de ordem:
- No caso de uma falha nos fluxos, o processo de recuperação de dados é realizado (e a recarga de eventos) significando que os dados "antigos" serão fundidos com os dados de tempo real.
- O desafio é que os dados de chegada tardia devem ser atribuídos corretamente ao tempo do evento em que foi gerado.
- A equipe DEA escolheu implementar uma janela de tempo e também dados pós-processo para garantir que os resultados sejam emitidos com o contexto de tempo de evento correto.
- Maior monitoramento e alertas:
- No caso de uma falha no fluxo, a equipe deve ser notificada o mais rápido possível.
- A falta de disparo de um alerta dentro do prazo pode resultar em perda de dados.
- A criação de uma implementação efetiva de monitoramento, registro, e alerta é vital.
Arora concluiu a conversa afirmando que embora as conquistas comerciais e técnicas para migrar do ETL em lote para o processamento de fluxo fossem numerosas também haviam muitos desafios e experiências de aprendizado. Os engenheiros que adotam o processamento de fluxo devem estar preparados para pagar um imposto por serem pioneiros, já que a ETL mais convencional é o lote e os modelos de aprendizado de máquinas de treinamento em dados de transmissão são um terreno relativamente novo. A equipe de processamento de dados também estará exposta a problemas operacionais de alta prioridade - como estar em chamada e lidar com interrupções - como, embora "as falhas do lote tenham de ser abordadas com urgência, as falhas de transmissão devem ser abordadas imediatamente". Um investimento em infraestrutura resiliente deve ser feito, e a equipe também deve cultivar o monitoramento e alertas eficazes e criar pipelines de entrega contínua que facilitem a rápida interação e implantação do aplicativo de processamento de dados.
O video completo da palestra Arora no QCon New York 2017 pode ser visto no InfoQ.
Sobre o Autor
 Daniel Bryant está liderando mudanças dentro de organizações e tecnologias. Seu trabalho atual inclui habilidades dentro das organizações, introduzindo melhores técnicas de coleta e planejamento de requisitos, com foco na relevância da arquitetura no desenvolvimento ágil e facilitando a integração / entrega contínua. A experiência técnica atual de Daniel se concentra em ferramentas de 'DevOps', plataformas de cloud/container e implementações de microservices. Ele também é líder na Comunidade Java de Londres (LJC), contribui para vários projetos de código aberto, escreve para sites técnicos bem conhecidos, como InfoQ, o DZone e o Voxxed, e regularmente apresenta em conferências internacionais como QCon, JavaOne e Devoxx.
Daniel Bryant está liderando mudanças dentro de organizações e tecnologias. Seu trabalho atual inclui habilidades dentro das organizações, introduzindo melhores técnicas de coleta e planejamento de requisitos, com foco na relevância da arquitetura no desenvolvimento ágil e facilitando a integração / entrega contínua. A experiência técnica atual de Daniel se concentra em ferramentas de 'DevOps', plataformas de cloud/container e implementações de microservices. Ele também é líder na Comunidade Java de Londres (LJC), contribui para vários projetos de código aberto, escreve para sites técnicos bem conhecidos, como InfoQ, o DZone e o Voxxed, e regularmente apresenta em conferências internacionais como QCon, JavaOne e Devoxx.