Yahoo met TensorFlowOnSpark en Open Source afin que les scientifiques et les ingénieurs de données puissent effectuer des apprentissages et du service de modèles distribués sur les architectures CPU/GPU exécutant directement du Spark ou du Hadoop. La bibliothèque semble permettre le portage des programmes TensorFlow existants vers les nouvelles API et d'obtenir des améliorations de performance de l'apprentissage et du modèle.
Dans l'annonce, Yahoo a détaillé les motivations derrière TensorFlowOnSpark, telles que la surcharge opérationnelle pour la gestion de grappes supplémentaires à l'extérieur des pipelines de données Spark spécifiques pour l'apprentissage de réseaux de neurones profonds, les transferts de jeux de données limités par les E/S réseau vers et depuis la grappe d'apprentissage, la complexité indésirable du système et les latences globales d'apprentissage de bout en bout. L'effort de TensorFlowOnSpark est similaire à la démarche antérieure que Yahoo a entrepris avec CaffeOnSpark. Selon Yahoo, les travaux existants sur le défi de l'intégration entre TensorFlow et Spark par DataBricks avec TensorFrame et SparkNet d'Amp Lab ont été des pas dans la bonne direction mais n'ont pas réussi à permettre aux processus TensorFlow de communiquer directement entre eux. L'un des objectifs de Yahoo était de faire de TensorFlowOnSpark une API entièrement compatible avec Spark, qui fonctionne aussi bien que des composants comme SparkSQL, MLib et d'autres bibliothèques Spark de base en termes de capacité d'intégration dans un pipeline de traitement Spark.
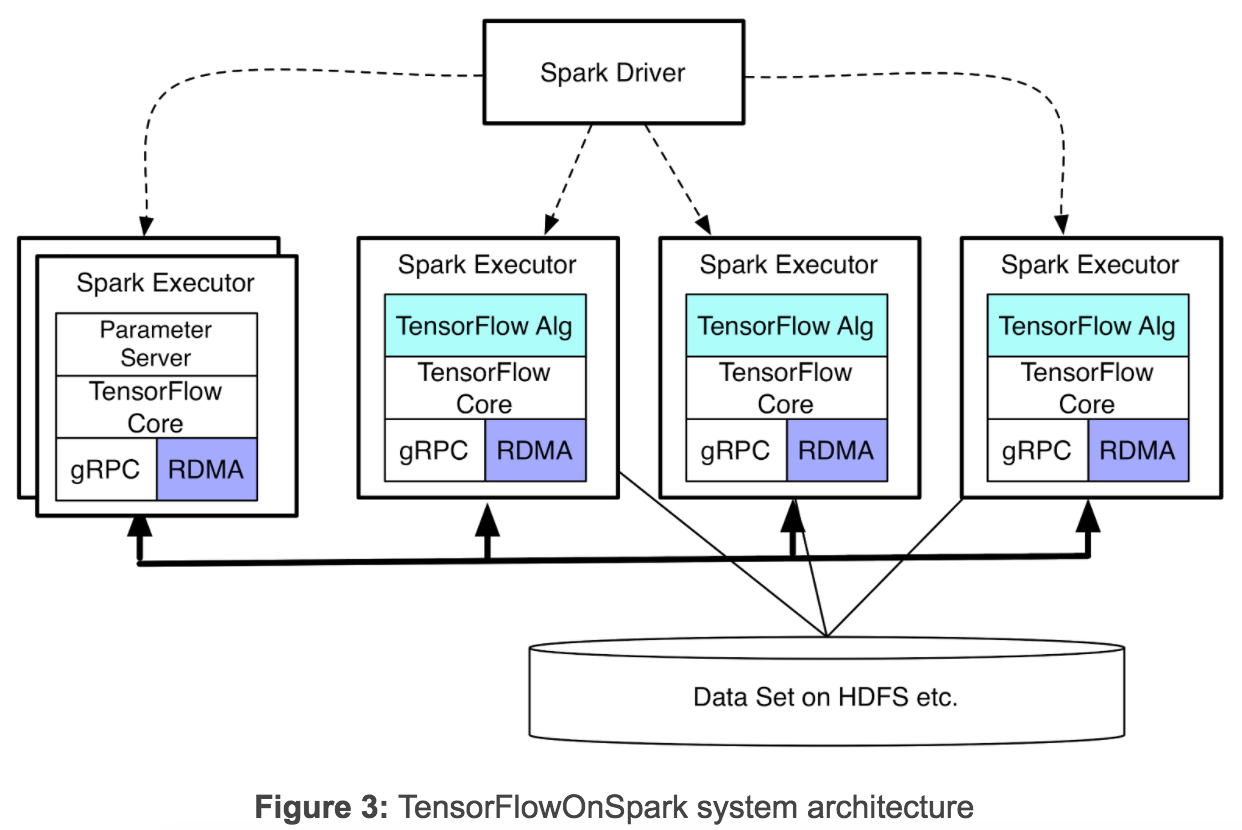
L'architecture place un algorithme TensorFlow donné et un noyau TensorFlow dans un Spark Executor et fournit au job TensorFlow un accès direct aux données HDFS via les lecteurs de fichiers et les QueueRunners TensorFlow, ce qui permet de réduire les E/S réseau et une approche "apporter le calcul aux données". TensorFlowOnSpark supporte les sémantiques de réservation/écoute de port pour les exécuteurs, de polling de messages pour les données et les fonctions de contrôle, de démarrage de la fonction principale TensorFlow, d'ingestion des données, des mécanismes de lecture et d'exécution de queue pour lire directement depuis HDFS, d'alimentation de RDD Spark dans TensorFlow via feed_dict et d'arrêt.
{kind=link}
En sus de TensorFlowOnSpark, Yahoo a également étendu le cœur du moteur C++ TenseFlow sur leur propre embranchement pour permettre RDMA sur Infiniband, une fonctionnalité qui avait été demandée et avait généré une discussion sur le projet principal de TensorFlow. Andy Feng de Yahoo a noté une amélioration de la vitesse d'apprentissage de dix à deux cent pour cent sur les différents réseaux en utilisant RDMA sur une communication inter-processus basée sur gRPC.