QCon San Francisco 2016で、Nega Narkheda氏は“ETL is Dead; Long Live Stream”と題して講演し、エンタープライズデータ処理の変化する状況について論じました。講演の中心は、オープンソースのストリーミングプラットフォームであるApache Kafkaが、データの転送や処理に関する現在の要求をサポートするに十分な、柔軟かつ統一化されたフレームワークを提供することができる、という主張です。
Confluentの共同設立者でCTOを務めるNarkhede氏の講演は、この10年間でデータとデータシステムが大幅に変化した、という指摘から始まりました。かつてこの分野は、オンライントランザクション処理(OLTP)提供するオペレーショナルデータベースと、オンライン分析処理(OLAP)を提供するリレーショナルデータウェアハウスで構成されるのが一般的でした。さまざまなオペレーショナルデータベースからのデータは、データウェアハウス内のマスタスキーマに1日1~2回、バッチロードされるのが普通の方法だったのです。このようなデータ統合プロセスは、一般にETL(Extract-Transform-Load)と呼ばれます。
ここ最近のデータトレンドのいくつかは、これまでのETLを大きく変えようとしています。
- 単一サーバのデータベースは、企業規模で運用される無数の分散データプラットフォームに置き換えられつつある。
- トランザクションデータ以外に、ログやセンサ、測定値など、さまざまなタイプのデータが存在する。
- ストリームデータがますます普及する一方で、日次バッチよりも高速な処理を求めるビジネスニーズがある。
このようなトレンドの結果として、独自の転送スクリプト、ESB(Enterprise Service Bus)やMQ(Message Queue)技術のようなエンタープライズミドルウェア、Hadoopなどのバッチ処理技術を組み合わせた従来のデータ統合のアプローチは、もはや役に立たないものと見なされるようになっています。
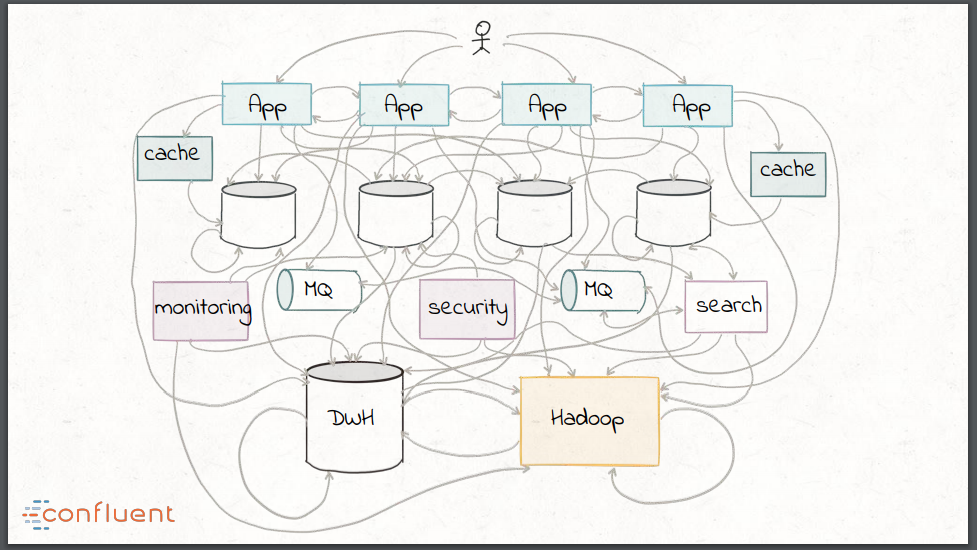
現代的なストリーミング技術への移行が、この問題の軽減に有効かどうかを検討する前に、Narkhede氏はまず、データ統合の歴史を簡単に説明しました。1990年代初頭の小売業界では、当時新たに利用可能になったデータ形式を使った購入者のトレンド分析が注目を集めていました。OLTPデータベースに格納されたオペレーショナルデータでは、データを抽出し、転送先のウェアハウスのスキーマに変換した上で、中央データウェアハウスにロードしなくてはなりませんでした。この技術自体は、過去20年間にわたって十分に完成されたものですが、ETLの持つ欠点のため、データウェアハウスにおけるデータカバレッジは依然として高くありません。
- グローバルスキーマが必要である。
- データのクレンジングとキュレーションが手作業であり、基本的にエラーを起こしやすい。
- ETLの運用コストの高さ — 処理時間が長く、時間およびリソース集約的であることが少なくない。
- ETLのツールは、データベースとデータウェアハウスのバッチ形式での接続のみを念頭に設計されている。
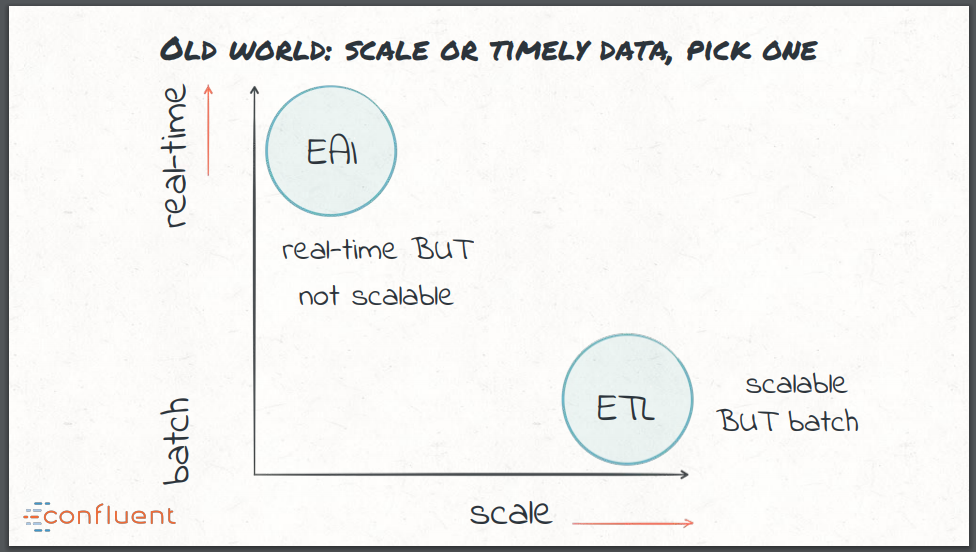
EAI(Enterprise Application Integration)はリアルタイムETLの初期の試みで、ESBとMQをデータ統合に使用していました。リアルタイム処理には有効だったのですが、必要な規模にスケールアップできないことが多々ありました。このために従来のデータ統合では、スケーラブルでないリアルタイム処理か、スケーラブルなバッチ処理かという、難しい選択を強いられていたのです。
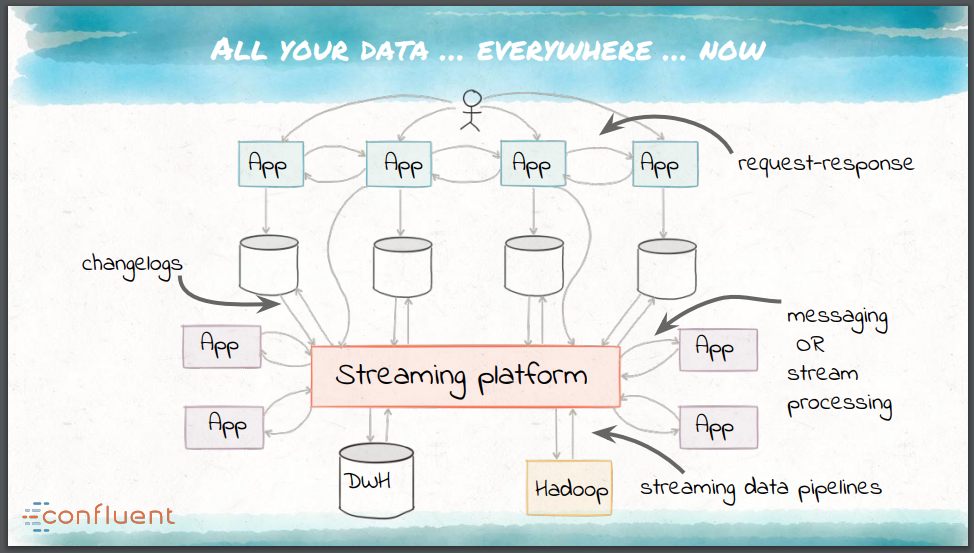
現代的なストリーミングの世界には、データ統合に関する新たな要求がある、とNarkhede氏は主張します。
- 大容量で極めて多様なデータを処理する能力。
- イベント中心の考え方への根本的な転換を促進するために、プラットフォームの基本からリアルタイムをサポートする必要がある。
- フォワードコンパチブルなデータアーキテクチャを実現し、同じデータを異なる方法で処理する必要のある、新たなアプリケーションのサポートを可能にしなければならない。
このような要件が、カスタムツールの寄せ集めではない、一体化したデータ統合プラットフォームの形成を促しています。このプラットフォームは、現代的なアーキテクチャやインフラストラクチャの基本原則を取り入れるとともに、フォールトトレラントで、並列処理能力を持ち、複数のデリバリセマンティクスをサポートし、効率的な運用機能と監視機能を提供し、スキーマ管理の可能なものでなくてはなりません。7年前にLinkedInで開発されたApache Kafkaは、そのようなオープンソースのストリーミングプラットフォームのひとつ、企業データの中枢神経システムとして、次のような役割を果たすことができます。
- EAIを使用せずに、アプリケーションにリアルタイムかつスケーラブルなメッセージバスを提供する。
- すべての処理にデータを提供する“真実の源(source-of-truth)”のパイプラインとして機能する。
- ステートフルなストリーム処理マイクロサービスを構築する上で、ビルディングブロックの役割を果たす。
Apache Kafkaは現在、LinkedInで1日14兆件のメッセージを処理するとともに、CisoやNetflix、PayPal、Verisonといったフォーチュン500企業を含む数千の企業において、世界中で運用されています。Kafkaはストリーミングデータに最適なストレージとして急速に普及しており、複数のデータセンタにまたがるアプリケーションの統合に、スケーラブルなメッセージバックボーンを提供しています。
Kafkaの基本となっているのはログの概念 — 追加のみ可能な、完全に順序付けられたデータ構造です。ログはパブリッシュ-サブスクライブ(pubsub)のセマンティクスに適しています。発行側(publisher)は不変かつ単調な方法でデータをログに書き込めばよく、受信側(subscriber)は現在のメッセージ処理部分を示す自分自身のポインタを持っていればよいのです。
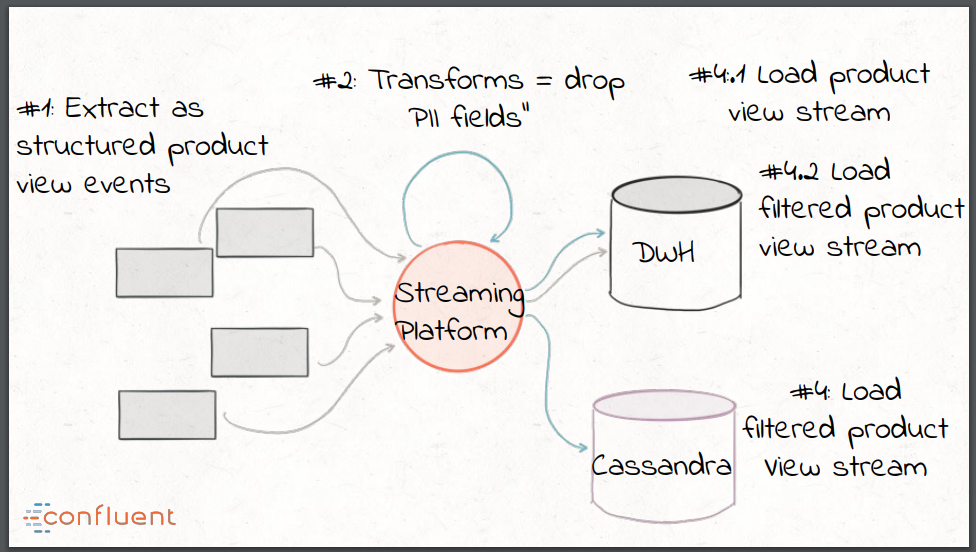
KafkaはKafka Connect APIを通じて、ストリーミングパイプライン — ETLの’E’と’L’ — の構築を可能にします。Connect APIはKafkaのスケーラビリティを活用し、Kafkaのフォールトトレランスモデル上に構築されており、すべてのコネクタを監視する統一的な方法を提供します。ストリーム処理と変換はKafka Streams APIで実装することができます — これがETLの’T’に相当します。Kafkaをストリーミングプラットフォームとして使用することで、対象とするシンクやデータストア、あるいはシステムごとに抽出、変換、ロード用のコンポーネントを開発する必要はなくなります。ソースから取得したデータは、構造化イベントとしてプラットフォームに一度取り出された後、ストリーム処理を通じて任意の形式に変換されます。
講演の最後の部分では、ストリーム処理 — ストリームデータの変換 — の概念を詳しく説明した後に、2つの競合するビジョンとして、リアルタイムMapReduceとイベント駆動マイクロサービスが紹介されました。リアルタイムMapReduceは分析的な用途に適していますが、運用には中央クラスタと独自のパッケージング、デプロイメント、監視が必要です。Apache Storm、Spark Streaming、Apache Flinkがこれを実装しています。イベント駆動のマイクロサービスのビジョン — Kafka Streams APIの実装する — によって、ライブラリを組み入れたJavaアプリケーションと利用可能なKafkaクラスタさえあれば、ストリーム処理へのアクセスが可能になる、というのがNarkhedes氏の意見です。
Kafka Streams APIは、結合やマップ、フィルタ、ウィンドウ集約などの演算子を備えた、使い勝手のよいフルーエントDSLを提供します。

これは真にイベント個別型(event-at-a-time)なストリーム処理であって、マイクロバッチは存在しません。また、遅延データを処理するために、イベント時間をベースとしたデータフロー形式のウィンドウニングアプローチを使用しています。Kafka Streamsはローカル状態を最初からサポートすると同時に、高速でステートフル、かつフォールトトレラントな処理をサポートします。さらにストリームの再処理もサポートするので、アプリケーションのアップグレードやデータのマイグレーション、A/Bテストの実行には最適です。
バッチ処理によるウィンドウ経由でのデータ取得と、到着したアイテムを個々に調査するリアルタイム処理の両方が可能なログは、バッチとストリームの融合であり、Apache Kafkaは“ETLの輝かしい未来”を約束している、と述べて、Narkhede氏は自身の講演を締め括りました。
Narkhede氏のQCon SFでの講演“ETL Is Dead; Long Live Streams”の全体を通じて撮影したビデオが、InfoQで公開されています。
著者について
 Daniel Bryant氏は企業とテクノロジの変革を指導しています。氏の現在の仕事には、要件収集と計画に関する優れた技術の導入による企業内のアジリティ実現、アジャイル開発におけるアーキテクチャの関連性の重視、継続的統合/デリバリの推進などが含まれています。氏は現在、’DevOps’ツーリング、クラウドおよびコンテナプラットフォーム、マイクロサービス実装といった技術的専門知識に注目しています。氏はLJC(London Java Community)のリーダでもあり、いくつかのオープンソースへのコントリビューション、InfoQ、DZone、Voxxedといった著名な技術Webサイトでの執筆、QCon、JavaOne、Devoxxなどの国際カンファレンスにおける定期的な講演を行っています。
Daniel Bryant氏は企業とテクノロジの変革を指導しています。氏の現在の仕事には、要件収集と計画に関する優れた技術の導入による企業内のアジリティ実現、アジャイル開発におけるアーキテクチャの関連性の重視、継続的統合/デリバリの推進などが含まれています。氏は現在、’DevOps’ツーリング、クラウドおよびコンテナプラットフォーム、マイクロサービス実装といった技術的専門知識に注目しています。氏はLJC(London Java Community)のリーダでもあり、いくつかのオープンソースへのコントリビューション、InfoQ、DZone、Voxxedといった著名な技術Webサイトでの執筆、QCon、JavaOne、Devoxxなどの国際カンファレンスにおける定期的な講演を行っています。