Amazon Web Services (AWS) recently announced the availability of Elastic Compute Cloud (EC2) P4d instances with UltraClusters capability. These GPU-powered instances will deliver faster performance, lower cost, and more GPU memory for machine learning (ML) training and high-performance computing (HPC) than previous generation of P3 instances.
The new P4d instances have eight NVIDIA A100 Tensor Core GPUs and 400 Gbps of network bandwidth. These GPUs are capable of up to 2.5 petaflops of mixed-precision performance and 320 GB of high bandwidth GPU memory in a single instance. To unblock scaling bottlenecks across multi-node distributed workloads, AWS utilized NVIDIA GPUDirect RDMA network interfaces for direct communication between GPUs across servers, which creates a lower latency and higher scaling efficiency environment. The 96 Intel Xeon Scalable vCPUs, 1.1 TB of system memory, and 8 TB of local NVMe storage in each P4d instance all help to reduce single node ML training times.
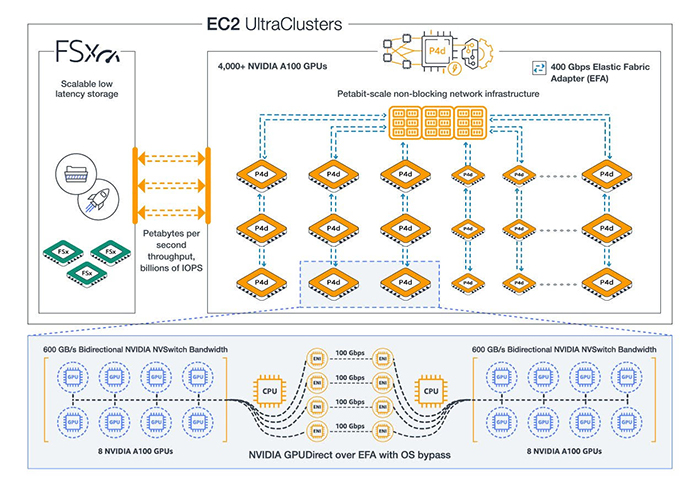
AWS is promising 3x faster performance, 60% lower cost, and 2.5x more GPU memory to help data scientists and engineers create larger and more-complex ML models that have data sets that continue to grow in size for many common ML tasks. Customers training models for autonomous vehicles vision, natural language processing, image classification, object detection, and general predictive analytics want to cut down on both time-to-train costs.
Some of AWS’ largest customers commented on the challenges that their ML engineers face, and how multiple generations of AWS GPU-based instances have helped them tackle these challenges. Karley Yoder, VP & GM, Artificial Intelligence at GE Healthcare, said:
Our medical imaging devices generate massive amounts of data that need to be processed by our data scientists. With previous GPU clusters, it would take days to train complex AI models, such as Progressive GANs, for simulations and view the results. Using the new P4d instances reduced processing time from days to hours. We saw two- to three-times greater speed on training models with various image sizes, while achieving better performance with increased batch size and higher productivity with a faster model development cycle.
Mike Garrison, a technical lead in infrastructure engineering at Toyota Research Institute, said:
The previous generation P3 instances helped us reduce our time to train machine learning models from days to hours and we are looking forward to utilizing P4d instances, as the additional GPU memory and more efficient float formats will allow our machine learning team to train with more complex models at an even faster speed.
Currently, P4 instances are available as p4d.24xlarge size and can be launched in the US East and US West regions.