Pontos Principais
- O Apache Spark Structured Streaming traz recursos de consulta SQL para streaming de dados, permitindo processamento de dados de forma escalável e em tempo real.
- O Redis Streams, estrutura de dados introduzida na versão 5.0 do Redis, permite coletar, persistir e distribuir dados em alta velocidade com latência menor do que um milissegundo. A integração do Redis Streams e o Structured Streaming simplifica a escalabilidade contínua das aplicações.
- A biblioteca de código aberto Spark-Redis conecta o Apache Spark ao Redis, oferece APIs de RDD (Resilient Distributed Datasets) e Dataframe para estruturas de dados do Redis e permite usar o Redis Streams como uma fonte de dados para o Structured Streaming.
O Structured Streaming, um novo recurso introduzido com na versão 2.0 do Apache Spark, chamou bastante a atenção da indústria e da comunidade de engenharia de dados. Desenvolvido baseado no mecanismo do Spark SQL, as APIs do Structured Streaming fornecem uma interface semelhante ao SQL para transmissão de dados.
Inicialmente, o Apache Spark processava consultas do Structured Streaming em microlotes, com uma latência de cerca de 100 milissegundos.
A versão 2.3, lançada em 2018, introduziu o "processamento contínuo" de baixa latência (1 milissegundo), o que está fomentando ainda mais a adoção da ferramenta.
Para trabalhar na velocidade do processamento contínuo do Spark, é necessário combiná-lo com um banco de dados de streaming de alta velocidade, como o Redis.
Esse banco de dados in-memory de código aberto é conhecido por sua alta velocidade e latência abaixo dos milissegundos. A versão 5.0 do Redis introduz uma nova estrutura de dados chamada Redis Streams, que permite que o Redis consuma, mantenha e distribua dados de streaming entre vários produtores e consumidores.
A pergunta é, qual é a melhor maneira de implantar o Redis Streams, como um banco de dados streaming, em conjunto com o mecanismo de processamento de dados do Apache Spark?
A biblioteca Spark-Redis, escrita em Scala, integra o Apache Spark e o Redis, para que seja possível:
- Ler e gravar dados como RDDs (Resilient Distributed Datasets) no Redis;
- Ler e gravar dados como DataFrames no Redis (isto é, permite mapear tabelas do Spark SQL para estruturas de dados do Redis);
- Utilizar o Redis Streams como uma fonte para o Structured Streaming;
- Implementar o Redis como um coletor após o Structured Streaming.
Este artigo apresenta um cenário do mundo real e como podemos processar os dados de streaming em tempo real usando o Redis e o Apache Spark.
Um cenário hipotético: calculando cliques em tempo real
Suponhamos que somos uma empresa de publicidade que publica anúncios gráficos em sites populares. Criamos memes dinâmicos baseados em imagens difundidas em mídias sociais e os colocamos como anúncios. Para maximizar nossos lucros, precisamos identificar os recursos que se tornam virais ou recebem mais cliques para exibi-los com mais frequência.
A maioria dos nossos recursos têm uma vida útil curta e o processamento de cliques em tempo real nos permite aproveitar rapidamente as imagens com tendências, o que é fundamental para o negócio. Nossa solução ideal de dados de streaming deve registrar todos os cliques em anúncios, processá-los e calcular a quantidade de cliques, tudo em tempo real. A figura a seguir mostra um esboço desse projeto:

Figura 1. Diagrama de blocos para contagem e cálculo de cliques em tempo real
Entrada
Para cada clique, a solução de entrada de dados (bloco 1 na Figura 1) coloca o ID do recurso e o custo do anúncio no Redis Stream como mostra o código a seguir:
XADD clicks * asset [asset id] cost [actual cost]
Exemplo:
XADD clicks * asset aksh1hf98qw7tt9q7 cost 29
Saída
Após o processamento de dados pelo bloco 2 na Figura 1, o resultado é armazenado em uma estrutura de persistência de dados. A solução de consulta de dados (bloco 3 na Figura 1) fornece uma interface SQL para os dados, para que seja possível consultar os principais cliques nos últimos minutos, como mostra o exemplo de código e o resultado da consulta a seguir:
select asset, count from clicks order by count desc
asset count
----------------- -----
aksh1hf98qw7tt9q7 2392
i2dfb8fg023714ins 2010
jsg82t8jasvdh2389 1938
Projetando a arquitetura da solução
Uma vez definidos os requisitos de negócio, é necessário explorar como é possível utilizar o Redis 5.0 e o Apache Spark 2.4 para criar uma solução que atend-os. Os exemplos deste artigo foram desenvolvidos utilizando a linguagem Scala, mas é possível utilizar a biblioteca do Spark-Redis utilizando também Java ou Python.
[Clique na imagem para ampliá-la]
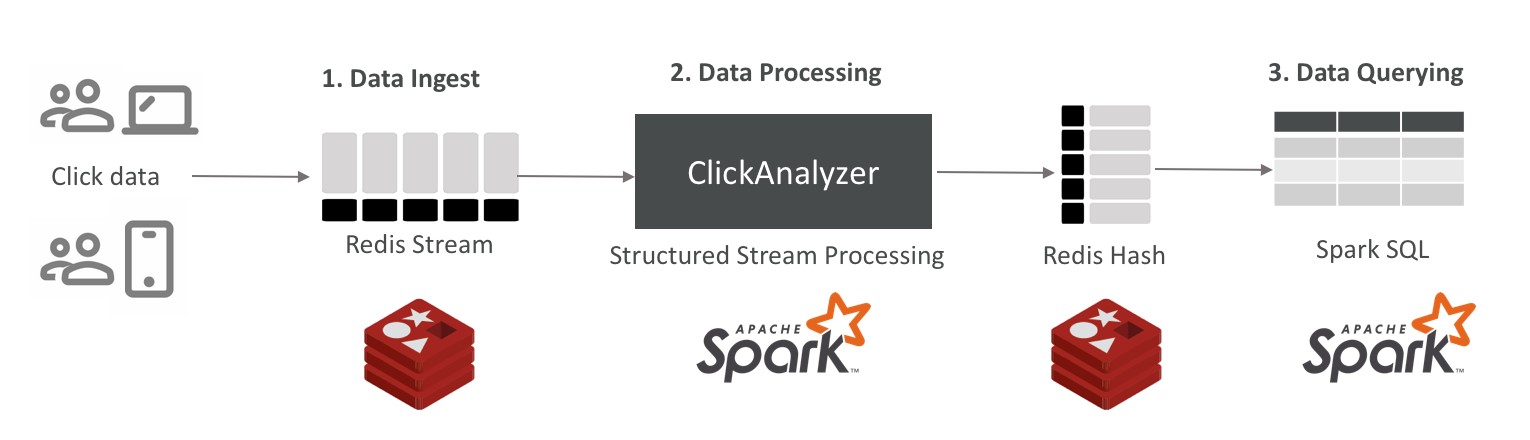
Figura 2. Arquitetura da Solução
Esse diagrama de fluxo parece bastante simples: primeiro, o sistema ingere os dados em um Redis Stream, consome os dados como um processo do Spark e agrega os resultados de volta ao Redis para que finalmente, seja consultado os resultados no Redis usando a interface do Spark-SQL.
- Ingestão de dados: o Redis Streams foi escolhido para ingestão de dados porque é uma estrutura de dados integrada no Redis que permite manipular mais de um milhão de operações de leitura e gravação por segundo. Além disso, o Redis Streams automaticamente solicita dados de acordo com o tempo e oferece suporte a grupos de consumidores que simplificam a maneira como os dados são lidos. A biblioteca Spark-Redis oferece suporte ao Redis Streams como fonte de dados e se ajusta perfeitamente à necessidade do banco de dados de streaming funcionar em conjunto com o mecanismo do Apache Spark.
- Processamento de dados: A API do Apache Spark Structured Streaming é uma ótima opção para o processamento de dados, e a biblioteca do Spark-Redis permite transformar os dados que chegam no Redis Streams em DataFrames. Com o Structured Streaming, é possível executar as consultas em microlotes ou no modo de processamento contínuo do Spark. Também é possível desenvolver um "inseridor" personalizado que permite gravar os dados em qualquer outro destino. Como apresentado na Figura 2, a saída será gravada no Redis utilizando uma estrutura de dados Hash.
- Consulta de dados: A biblioteca do Spark-Redis permite mapear estruturas de dados nativas do Redis como DataFrames. É possível declarar uma "tabela temporária" que mapeia colunas para chaves específicas de uma estrutura de dados Hash, e pelo desempenho e pela sua latência abaixo de milissegundo do Redis, é possível utilizar os recursos de consulta em tempo real com o Spark-SQL.
A partir de agora, esse artigo mostrará como desenvolver e executar cada componente dessa solução. Mas primeiro, é necessário inicializar o ambiente de desenvolvimento com as ferramentas apropriadas.
Encontrando as ferramentas de desenvolvimento corretas
No exemplo que vamos dar, foi utilizado o gerenciador de pacotes Homebrew para baixar e instalar o software no macOS, embora seja possível escolher outros gerenciadores de pacotes dependendo do sistema operacional.
1. Redis 5.0 ou superior: Primeiro, é necessário fazer o download e instalar o Redis 5.x no ambiente. Importante ressaltar que versões anteriores do Redis não suportam Redis Streams.
No Homebrew, foi instalado e inicializado Redis 5.0 via código, como mostra o exemplo abaixo:
$ brew install Redis
$ brew services start Redis
Se uma versão anterior do Redis já está em execução, é possível fazer um upgrade da versão utilizando o código a seguir:
$ brew upgrade Redis
2. Apacke Spark 2.3 ou superior: Em seguida, precisamos fazer o download e instalar o Apache Spark a partir do site ou instalá-lo usando o Homebrew, como mostra o código a seguir:
$ brew install apache-spark
3. Scala 2.12.8 ou superior: Fazer o mesmo para o Scala, seguindo a linha de comando a seguir:
$ brew install scala
4. Apache Maven: Será necessário instalar, como mostra o modelo a seguir, o Maven para compilar a biblioteca Spark-Redis.
$ brew install maven
5. JDK 1.8 ou superior: É possível fazer o download e instalar este JDK a partir do site da Oracle ou no Homebrew, executando o comando mostrado abaixo. Para a versão mais recente do JDK, é necessário substituir, no exemplo abaixo, java8 por java.
$ brew cask install java8
6. Spark-Redis library: Essa é a parte principal da solução, é importante fazer o download da biblioteca do GitHub e criar o pacote como mostra o código abaixo:
$ git clone https://github.com/RedisLabs/spark-redis.git
$ cd spark-redis
$ mvn clean package -DskipTests
Este comando resultará no arquivo "spark-redis-<version>-jar-with-dependencies.jar" dentro do diretório "./target/directory". No exemplo deste artigo, o arquivo gerado foi o "spark-redis-2.3.1-SNAPSHOT-jar-with-dependencies.jar"
7. SBT 1.2.8 ou superior: O SBT é uma ferramenta de compilação do Scala que simplifica a organização e a criação de arquivos.
$ brew install sbt
8. Ambiente de Desenvolvimento: Por fim, é necessário configurar a estrutura de pastas e criar o arquivo. Para este exemplo, o diretório base para a codificação dos programas será o "scala", que pode ser criado utilizando o exemplo de código a seguir:
$ mkdir scala
$ cd ./scala
Crie um novo arquivo, build.sbt, com o seguinte conteúdo:
name := "RedisExample"
version := "1.0"
scalaVersion := "2.12.8"
val sparkVersion = "2.4.0"
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % sparkVersion,
"org.apache.spark" %% "spark-sql" % sparkVersion,
"org.apache.spark" %% "spark-catalyst" % sparkVersion
)
Inicialize o diretório do pacote utilizando as linhas de comando a seguir:
$ mkdir ./src/main/scala/
$ mkdir ./lib
$ sbt package
Copie o arquivo "spark-redis- <version> -jar-with-dependencies.jar" para o diretório "lib".
Compilando a solução de contagem de cliques
Conforme descrito na seção de arquitetura, a solução tem três partes - o componente de dados, um processador de dados dentro do mecanismo Spark e a interface de consulta de dados. Nesta seção, será detalhado cada uma dessas partes e apresentada uma solução funcional.
1. Ingestão para o Redis Stream
O Redis Streams é uma estrutura de dados que permite apenas anexação de informação. Supondo que os dados serão consumidos pela unidade de processamento contínuo do Apache Spark, é possível limitar o número de mensagens em um milhão, conforme a linha de comando abaixo:
XADD clicks MAXLEN ~ 1000000 * asset aksh1hf98qw7tt9q7 cost 29
Os clientes Redis mais populares suportam Redis Streams e dependem da linguagem de programação, é possível escolher, por exemplo, o redis-py para Python, Jedis ou Lettuce para Java, nó-redis para Node.js dentre outros.
[Clique na imagem para ampliá-la]

Figura 3. Ingestão de Dados
2. Processamento de dados
Esta seção será dividida em três partes, para total cobertura desta fase da solução:
- A. Leitura e processamento de dados do Redis Stream;
- B. Armazenando os resultados no Redis;
- C. Executando o programa.
[Clique na imagem para ampliá-la]
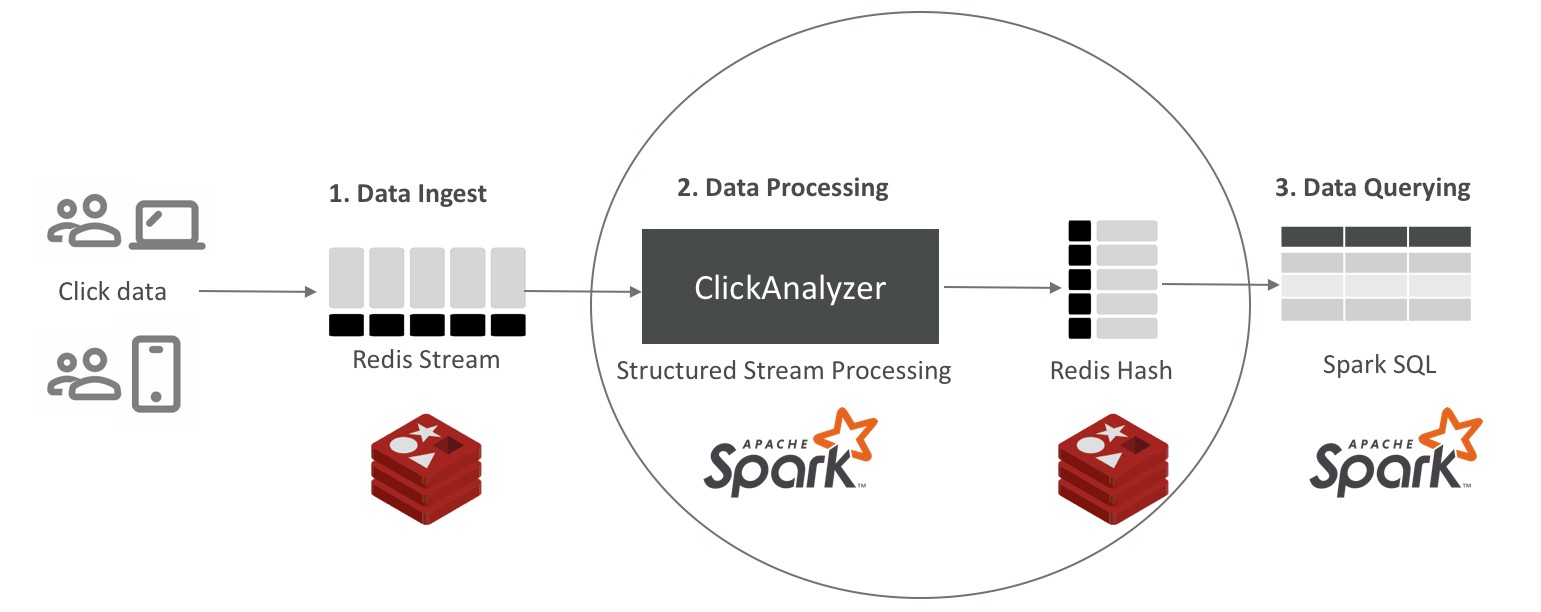
Figura 4. Processamento de Dados
A. Lendo dados do Redis Streams
Para ler os dados do Redis Streams no Spark, é preciso primeiramente definir como se conectar ao Redis, bem como a estrutura do esquema dos dados no Redis Streams.
Para conectar-se ao Redis, é necessário criar um novo SparkSession com os parâmetros de conexão, como exibido abaixo:
val spark = SparkSession
.builder()
.appName("redis-example")
.master("local[*]")
.config("spark.redis.host", "localhost")
.config("spark.redis.port", "6379")
.getOrCreate()
Para configurar a estrutura do esquema, iremos nomear a stream como "clicks" e definir uma opção para "stream.keys" como "clicks". Como cada um dos elementos da stream contém um recurso e o custo associado a ele, criaremos um StructType de uma Matriz com dois StructFields - um para "asset" (recurso) e outro para "cost" (custo), conforme mostra o código a seguir:
val clicks = spark
.readStream
.format("redis")
.option("stream.keys","clicks")
.schema(StructType(Array(
StructField("asset", StringType),
StructField("cost", LongType)
)))
.load()
No primeiro programa, estamos interessados no número de cliques por recurso. Portanto, vamos criar um DataFrame que contenha dados agrupados por contagem de recursos, que é o objetivo do código abaixo:
val byasset = clicks.groupBy("asset").count
A última etapa é iniciar a consulta como sendo uma Structured Stream, conforme o código:
val query = byasset
.writeStream
.outputMode("update")
.foreach(clickWriter)
.start()
Observe o uso de um ForeachWriter próprio para gravar os resultados no Redis. Caso seja necessário escrever a saída no console, utilize o código a seguir como base:
val query = byasset
.writeStream
.outputMode("update")
.format("console")
.start()
Para processamento contínuo, queremos adicionar um comando "trigger" à nossa consulta como ".trigger (Trigger.Continuous ("1 second"))", todavia essa abordagem não funciona para consultas agregadas, inviável para o exemplo deste artigo.
A seguir está o programa completo que lê novos dados de cliques do Redis Streams e os processa usando as APIs do Spark Structured Streaming. É possível reproduzir esse código em outro ambiente, salvando o programa em "src/main/scala" como "ClickAnalysis.scala". (Caso o servidor Redis não esteja sendo executado localmente na porta 6379, precisamos definir os parâmetros de conexão apropriados.)
// Program: ClickAnalysis.scala
//
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import com.redislabs.provider.redis._
object ClickAnalysis {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("redis-example")
.master("local[*]")
.config("spark.redis.host", "localhost")
.config("spark.redis.port", "6379")
.getOrCreate()
val clicks = spark
.readStream
.format("redis")
.option("stream.keys","clicks")
.schema(StructType(Array(
StructField("asset", StringType),
StructField("cost", LongType)
)))
.load()
val byasset = clicks.groupBy("asset").count
val clickWriter : ClickForeachWriter =
new ClickForeachWriter("localhost","6379")
val query = byasset
.writeStream
.outputMode("update")
.foreach(clickWriter)
.start()
query.awaitTermination()
} // Fim do main
} //Fim do object
B. Armazenando os resultados no Redis
Para escrever os resultados de volta no Redis, foi desenvolvido um ForeachWriter personalizado chamado ClickForeachWriter que estende a própria classe ForeachWriter e se conecta ao Redis usando o Jedis, o cliente Java para Redis. A seguir o programa completo, salvo como "ClickForeachWriter.scala":
// Program: ClickForeachWriter.scala
//
import org.apache.spark.sql.ForeachWriter
import org.apache.spark.sql.Row
import redis.clients.jedis.Jedis
class ClickForeachWriter(p_host: String, p_port: String) extends
ForeachWriter[Row]{
val host: String = p_host
val port: String = p_port
var jedis: Jedis = _
def connect() = {
jedis = new Jedis(host, port.toInt)
}
override def open(partitionId: Long, version: Long):
Boolean = {
return true
}
override def process(record: Row) = {
var asset = record.getString(0);
var count = record.getLong(1);
if(jedis == null){
connect()
}
jedis.hset("click:"+asset, "asset", asset)
jedis.hset("click:"+asset, "count", count.toString)
jedis.expire("click:"+asset, 300)
}
override def close(errorOrNull: Throwable) = {
}
}
Precisamos observar uma coisa importante neste programa: os resultados são armazenados em uma estrutura de dados Hash, cuja chave segue a sintaxe, "click: <asset id>". Essa estrutura será transformada para ser usada como um DataFrame na última seção deste artigo. Outra coisa a salientar é a expiração da chave, que é totalmente opcional. No exemplo, é possível observar como estender a vida útil da chave em cinco minutos toda vez que um clique é gravado.
C. Executando o programa
Antes da execução do exemplo, precisamos compilar os programas e para fazer isso basta, no diretório inicial (o diretório onde armazenamos o build.sbt), executar o comando:
$ sbt package
Os programas devem compilar sem erros. Em caso de erros, é necessário correção e somente após este passo executar novamente o pacote sbt. Cumprida essa etapa, para iniciar o programa basta, no mesmo diretório, executar o seguinte comando:
spark-submit --class ClickAnalysis --jars
./lib/spark-redis-2.3.1-SNAPSHOT-jar-with-dependencies.jar
--master local[*] ./target/scala-2.12/redisexample_2.12-1.0.jar
Para desabilitar as mensagens de depuração basta parar o programa (ctrl-c), editar o arquivo "log4j.properties" dentro de "/usr/local/Cellar/apache-spark/2.4.0/libexec/conf/" (ou onde o arquivo .properties estiver armazenado) e alterar o valor da propriedade "log4j.rootCategory" para "WARN" conforme mostra o exemplo a seguir:
log4j.rootCategory=WARN, console
Este programa irá extrair automaticamente mensagens do Redis Stream. Se não houver mensagens, o nosso programa aguardará novas mensagens de forma assíncrona. É possível iniciar o redis-cli em um console diferente e adicionar uma mensagem ao Redis Stream para testar se a aplicação está consumindo mensagens corretamente, utilizando o exemplo a seguir:
$ redis-cli
redis-cli> XADD clicks * asset test cost 100
Se tudo ocorrer bem, é possível ler os resultados na estrutura de dados Hash como:
redis-cli> hgetall click:test
1) "asset"
2) "test"
3) "count"
4) "1"
3. Consultando os dados: Lendo os dados do Redis como DataFrames
Este último componente da solução fornece essencialmente uma interface SQL para os dados do Redis. Ler os dados por meio de comandos SQL é mais uma vez um processo de duas etapas, sendo: a. definir o esquema SQL para os dados do Redis e, b. executar o comando SQL.
[Clique na imagem para ampliá-la]
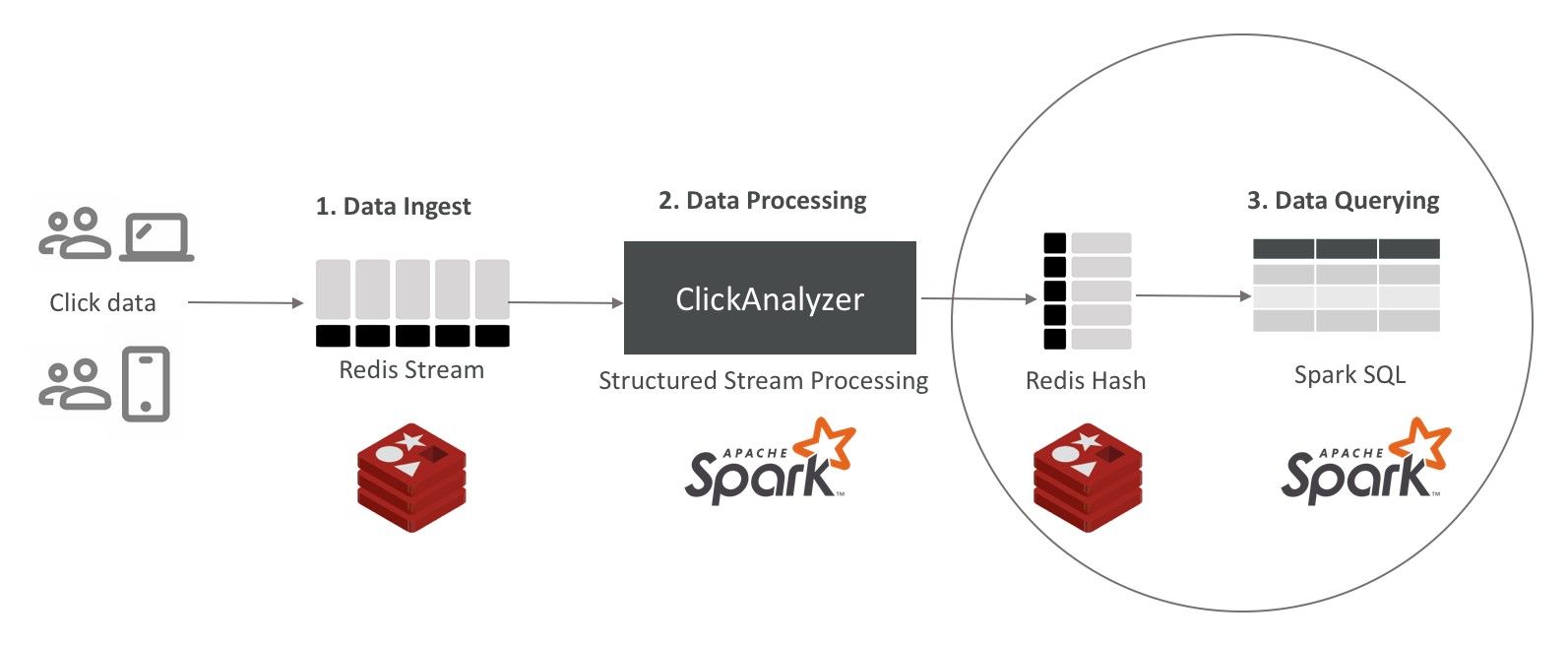
Figura 5. Consultando dados
Mas antes de tudo isso, é preciso executar o spark-sql no seu console a partir do diretório home, como mostrado a seguir:
$ spark-sql --jars
./lib/spark-redis-2.3.1-SNAPSHOT-jar-with-dependencies.jar
Esse comando nos levará a um prompt spark-sql como a seguir:
spark-sql>
Nesse ponto, o esquema SQL será definido para os dados armazenados na estrutura de dados do Redis Hash. Importante lembrar que os dados são armazenados para cada recurso em uma estrutura de dados de hash indicada pela chave, "click: <asset id>" e o Hash tem outra chave, "count". O comando para criar o esquema e mapeá-lo para a estrutura de dados do Redis Hash é:
spark-sql> CREATE TABLE IF NOT EXISTS clicks(asset STRING, count
INT) USING org.apache.spark.sql.redis OPTIONS (table 'click')
O comando cria uma nova visão de tabela chamada "clicks" e usa as diretivas especificadas na biblioteca do Spark-Redis para mapear as colunas "asset" e "count" para os respectivos campos em Hash. Agora é possível executar a consulta como mostra o exemplo a seguir:
spark-sql> select * from clicks;
test 1
Time taken: 0.088 seconds, Fetched 1 row(s)
Caso seja necessário executar as consultas SQL programaticamente, consulte a documentação fornecida pelo Apache Spark sobre como se conectar ao mecanismo Spark usando os drivers ODBC/JDBC.
Quais resultados foram atingidos?
Este artigo demonstra como usar o Redis Streams como uma fonte de dados para o mecanismo Apache Spark, e também como o Redis Streams pode alimentar um caso de uso do Structured Streaming. Este trabalho mostra também como ler dados do Redis usando a API DataFrames no Apache Spark e colocar os conceitos independentes de Structured Streaming e DataFrames juntos para demonstrar o que é possível conseguir usando a biblioteca do Spark-Redis.
O Redis Streams simplifica a tarefa de coletar e distribuir dados em alta velocidade. Ao combiná-lo com o Structured Streaming no Apache Spark, é possível alimentar todos os tipos de soluções que exigem cálculos em tempo real para cenários que vão desde IoT, detecção de fraudes, AI , machine learning, análise em tempo real , dentre outras.
Sobre o Autor
 Roshan Kumar é gerente sênior de produtos na Redis Labs, Inc. Possui vasta experiência em desenvolvimento de software e gerenciamento de produtos no setor de tecnologia. No passado, Kumar trabalhou na Hewlett-Packard e em algumas startups de sucesso do Vale do Silício. É bacharel em Ciência da Computação e possui MBA pela Universidade de Santa Clara, Califórnia, EUA..
Roshan Kumar é gerente sênior de produtos na Redis Labs, Inc. Possui vasta experiência em desenvolvimento de software e gerenciamento de produtos no setor de tecnologia. No passado, Kumar trabalhou na Hewlett-Packard e em algumas startups de sucesso do Vale do Silício. É bacharel em Ciência da Computação e possui MBA pela Universidade de Santa Clara, Califórnia, EUA..