Pontos Principais
- Boa parte das organizações lutam para desbloquear a ciência de dados para que possam otimizar seus processos operacionais e fazer com que cientistas de dados, analistas e equipes de negócios falem a mesma linguagem: equipes diferentes e o processo de ciência de dados são muitas vezes uma fonte de atrito;
- O framework "Healthy Data Science Organization" é um portfólio de metodologias, tecnologias e recursos que auxiliarão sua organização (do entendimento do negócio, passando pela modelagem, geração e aquisição de dados, chegando até a implantação e gerenciamento) a se tornar mais orientada a dados;
- Para traduzir com sucesso a visão e as metas de negócios em resultados tangíveis, é importante estabelecer métricas claras de desempenho;
- As organizações precisam pensar de forma mais orgânica o fluxo de dados de ponta a ponta e a arquitetura que suportará suas soluções de ciência de dados;
- Utilizando o serviço de machine learning da plataforma Azure, da Microsoft, a equipe produziu uma solução que recomenda o posicionamento e a composição de uma força de trabalho baseado na necessidade da equipe, experiência e conhecimento de cada indivíduo para novos projetos.
Nos últimos anos, milhares de diferentes fontes de dados tornaram-se disponíveis e aptas a serem consumidas, com isso as organizações começaram a procurar formas de usar as mais recentes técnicas de análise de dados para atender às necessidades do negócio e buscar novas oportunidades. Os dados não apenas se tornaram mais disponíveis e acessíveis, como também houve um aumento considerável de ferramentas e aplicações, permitindo que as equipes criem soluções sofisticadas de análise de dados. Por todas essas razões, as organizações estão cada vez mais formando equipes específicas e especializadas com o objetivo de trabalhar nos diversos objetivos da Ciência de Dados.
A Ciência de Dados é um campo que combina matemática, programação e visualização, aplicando métodos científicos a domínios ou problemas específicos de negócios, por exemplo, prever o comportamento futuro de um cliente, planejar rotas de tráfego aéreo ou reconhecer padrões de fala. Mas o que significa realmente ser uma organização orientada a dados?
Neste artigo, os líderes técnicos e de negócios serão apresentados a métodos para avaliar se sua organização é orientada por dados e o nível de maturidade na Ciência de Dados. Além disso, por meio de casos de uso reais e aplicados, esse trabalho apresenta uma forma de uso do framework "Healthy Data Science Organization" para nutrir uma mentalidade de Ciência de Dados saudável dentro da organização. Essa estrutura foi criada com base na experiência do autor como cientista de dados, trabalhando em soluções completas de Ciência de Dados e Aprendizado de Máquina (machine learning) com clientes externos de uma ampla variedade de setores, incluindo energia, petróleo e gás, varejo, aeroespacial, saúde e profissional e serviços. O framework fornece um ciclo de vida, descrevendo o passo a passo, do início ao fim, como estruturar o desenvolvimento dos projetos de Ciência de Dados.
Entendendo o framework "Healthy Data Science Organization"
Ser uma organização orientada a dados significa incorporar as equipes de Ciência de Dados totalmente com o negócio e adaptar o coração operacional da empresa (técnicas, processos, infra-estruturas e cultura). O framework "Healthy Data Science Organization" é um portfólio de metodologias, tecnologias, recursos que, se usados corretamente, ajudarão a organização (do entendimento do negócio, passando pela modelagem, geração e aquisição de dados, chegando até a implantação e gerenciamento) a se tornar mais orientada a dados. Essa estrutura, conforme mostrado na Figura 1, inclui seis princípios-chave:
1. Compreender o negócio e o processo de tomada de decisão;
2. Estabelecer métricas de desempenho;
3. Projetar a solução de ponta a ponta;
4. Desenvolva um ferramental que suporte a Ciência de Dados;
5. Unifique a visão da Ciência de Dados da organização;
6. Mantenha as pessoas envolvidas.

Figura 1. Healthy Data Science Organization Framework.
Dada a rápida evolução desse campo, as organizações geralmente precisam de orientação sobre como aplicar as mais recentes técnicas de Ciência de Dados para atender às suas necessidades de negócio ou buscar novas oportunidades.
Princípio 1: Entendendo o negócio e o processo de tomada de decisão
Para uma boa parcela das organizações, a falta de dados não é um problema. Na verdade, é o oposto: muitas vezes há muita informação disponível para tomar uma decisão clara. Com tantos dados para classificar, as organizações precisam de uma estratégia bem definida para esclarecer os seguintes aspectos de negócio:
- Como a Ciência de Dados pode ajudar as organizações a transformar negócios, gerenciar melhor os custos e impulsionar maior excelência operacional?
- As organizações têm um propósito e uma visão bem definida do que estão procurando realizar?
- Como as organizações podem obter apoio de executivos, incluindo os de nível C, que são os executivos mais seniores e de cargos mais altos (chiefs) de uma companhia, para levar a visão orientada a dados e conduzi-la pelas diferentes partes do negócio?
Em resumo, as empresas precisam ter uma compreensão clara do processo de tomada de decisões de seus negócios e uma melhor estratégia de Ciência de Dados para apoiar esse processo. Com a adoção de uma abordagem correta de Ciência de Dados, o que antes era um volume avassalador de informações diferentes torna-se um ponto de decisão simples e claro. Impulsionar a transformação exige que as empresas tenham um propósito e uma visão bem definida do que estão procurando realizar. Geralmente requer o apoio de um executivo de nível C para ter essa visão e conduzi-la pelas diferentes partes de um negócio.
As organizações devem começar com as perguntas certas. Elas devem ser mensuráveis, claras, concisas e diretamente correlacionadas às suas estratégias de negócio. Nesse estágio, é importante projetar perguntas para qualificar ou desqualificar possíveis soluções para um problema ou oportunidade de negócios específicos. Por exemplo, comece com um problema claramente definido: uma empresa de varejo está enfrentando custos crescentes e não é mais capaz de oferecer preços competitivos a seus clientes. Uma das muitas perguntas para resolver esse problema de negócio pode incluir: a empresa pode reduzir suas operações sem comprometer a qualidade?
Há duas tarefas principais que as organizações precisam endereçar para responder esse tipo de pergunta:
- Definir objetivos e metas de negócio: a equipe de Ciência de Dados precisa trabalhar com especialistas em negócio e outras partes interessadas para entender e identificar os problemas de negócio;
- Formule perguntas certas: as empresas precisam formular perguntas tangíveis que definam os objetivos de negócio que as equipes de Ciência de Dados podem atingir.
No ano passado, a equipe de machine learning da Azure, plataforma de cloud computing da Microsoft, desenvolveu uma solução de alocação de pessoal baseada em recomendação para uma empresa de serviços profissionais. Utilizando o serviço de aprendizado de máquina, foi desenvolvida uma solução de recomendação de posicionamento da força de trabalho que leva em consideração: a composição ideal da equipe; a experiência; e o conhecimento dos indivíduos para novos projetos. O objetivo principal do projeto é maximizar o lucro da empresa.
A alocação da equipe de funcionários do projeto é feita manualmente pelos gerentes de projeto, sendo baseada na disponibilidade da equipe, no conhecimento prévio e desempenho anterior do indivíduo. Este processo é demorado e os resultados são frequentemente abaixo do esperado. Se levado em consideração as informações históricas e técnicas avançadas de aprendizado de máquina, esse processo pode ser feito de forma mais eficiente.
Com o objetivo de traduzir esse problema de negócio em soluções e resultados tangíveis, a equipe do projeto juntamente com o cliente, formularam algumas perguntas pertinentes, como:
1. Como podemos prever a composição do pessoal para um novo projeto? Por exemplo, um gerente de programa sênior, um cientista de dados principal e dois assistentes de contabilidade seria uma boa composição?
2. Como podemos calcular a pontuação de aptidão da equipe para um novo projeto? Foi definido que o Índice de Aptidão Pessoal é um bom indicador para medir a adequação do pessoal para um determinado projeto.
O objetivo da solução de aprendizado de máquina foi sugerir o funcionário mais apropriado para um novo projeto, com base na disponibilidade, geografia, experiência do tipo de projeto, experiência no setor e margem de contribuição por hora gerada em projetos anteriores. A plataforma Azure, pode contribuir na criação de soluções analíticas de força de trabalho que forneçam a base para planos de ação específicos e investimentos em força de trabalho: o Azure Cloud, promove produtividade no processo de desenvolvimento de ponta a ponta, bem como o monitoramento, gestão e proteção dos recursos na nuvem. Além disso, o serviço de aprendizado de máquina fornece um ambiente baseado em nuvem que as organizações usam para preparar dados, treinar, testar, implantar, gerenciar e rastrear modelos de aprendizado de máquina. Esse serviço também inclui recursos que automatizam a geração de modelos e o ajuste que facilita o desenvolvimento de modelos mais precisos e eficazes. Essas soluções podem solucionar lacunas ou ineficiências na alocação de pessoal da organização que precisam ser superadas para gerar melhores resultados ao negócio. As organizações podem obter uma vantagem competitiva automatizando a análise da força de trabalho e concentrando esforços na otimização do uso de seu capital humano. Nos próximos parágrafos, será apresentado como a solução foi desenvolvida pela equipe da Azure.
Princípio 2: Estabelecer indicadores de desempenho
A fim de traduzir com sucesso essa visão e metas de negócios em resultados tangíveis, o próximo passo é estabelecer indicadores claros de desempenho. Nesta segunda etapa, as organizações precisam se concentrar nesses dois aspectos analíticos que são cruciais para definir o pipeline da solução com uso dos dados (Figura 2):
- Qual é a melhor abordagem analítica para lidar com o problema do negócio e tirar conclusões precisas?
- Como essa visão pode ser traduzida em resultados tangíveis capazes de melhorar o negócio?
 Figura 2. Pipeline da solução com uso dos dados.
Figura 2. Pipeline da solução com uso dos dados.
Esse passo é dividido em três fases:
- Decidir o que será mensurado
Analisemos um exemplo, a manutenção preditiva é uma técnica usada para prever quando uma máquina em serviço irá falhar, permitindo que sua manutenção seja planejada com antecedência. Essa é uma área muito ampla com vários objetivos finais, como: prever as causas-raiz da falha, quais peças precisarão de substituição e quando fornecer recomendações de manutenção após a falha dentre outros.
Muitas empresas estão adotando a abordagem da manutenção preditiva utilizando-se da enorme quantidade de dados disponíveis provenientes dos diversos tipos de sensores e sistemas. Todavia não é raro não terem dados suficientes sobre seu histórico de falhas o que dificulta muito a manutenção preditiva - afinal, os modelos precisam ser treinados nesses dados de histórico de falhas para prever futuros incidentes de falha. Por isso, embora seja importante definir a visão, a finalidade e o escopo de qualquer projeto, é essencial captar os dados certos. No exemplo da manutenção preditiva, dados certos incluem, mas não estão limitadas a: histórico de falhas, histórico de manutenção ou reparo, condições de operação da máquina, metadados do equipamento. No exemplo, consideremos um caso de uso de falha da roda: os dados de treinamento devem conter recursos relacionados às operações da roda. Se o problema é prever a falha do sistema de tração, os dados de treinamento devem abranger todos os diferentes componentes do sistema de tração. O primeiro caso tem como alvo um componente específico, enquanto o segundo caso visa a falha de um subsistema maior. A boa prática recomenda sempre projetar sistemas de previsão sobre componentes específicos em detrimento a subsistemas maiores.
Considerando as fontes de dados do problema citado anteriormente, os dois principais tipos de dados observados no domínio de manutenção preditiva são:
- Dados temporais (como telemetria operacional, condições da máquina, tipos de ordens de serviço, códigos de prioridade que terão registros de data e hora no momento da gravação. Falhas, manutenção ou reparo e histórico de uso também terão registros de data e hora associados a cada evento);
- Dados estáticos (características da máquina e recursos do operador, por exemplo, em geral, são estáticos, pois descrevem as especificações técnicas de máquinas ou atributos do operador. Se esses recursos pudessem mudar com o tempo, eles também deveriam ter, obrigatoriamente, data e hora associados). As variáveis preditoras e de destino devem ser pré-processadas e transformadas em tipos de dados numéricos, categóricos e outros, dependendo do algoritmo utilizado.
2. Decidir como mensurar
Pensar sobre como as organizações medem seus dados é igualmente importante, especialmente antes da fase de coleta e ingestão de dados. As principais perguntas para essa fase incluem:
- Qual é o período de tempo?
- Qual é a unidade de medida?
- Quais fatores devem ser incluídos?
O objetivo principal desta fase é identificar as principais variáveis de negócio que a análise precisa prever. Essas variáveis são denominadas alvos do modelo e utiliza-se as métricas associadas a elas para determinar o sucesso do projeto. Dois exemplos dessas metas são: previsões de vendas ou probabilidade de um pedido ser fraudulento.
3. Definição de indicador de sucesso
Após a identificação das principais variáveis de negócio, é importante traduzir seu problema de negócio em um problema de ciência de dados e definir os indicadores que definirão o sucesso do projeto. As organizações geralmente usam ciência de dados ou aprendizado de máquina para responder cinco tipos de perguntas:
- Quanto ou quantos? (regressão)
- Qual categoria? (classificação)
- Qual grupo? (clustering)
- Isso é estranho? (detecção de anomalia)
- Qual opção deve ser tomada? (recomendação)
É importante determinar quais dessas perguntas as empresas estão perguntando e como elas atendem às metas de negócio e permitem a medição dos resultados. Neste ponto, é importante revisitar os objetivos do projeto, perguntando e refinando questões que sejam relevantes, específicas e não ambíguas. Numa situação hipotética de uma empresa que deseja obter uma previsão de perda de clientes, um exemplo de objetivo poderia ser uma taxa de precisão de "x" por cento ao final de um projeto de três meses. A partir desses dados, pode-se tomar decisões como oferecer promoções aos clientes para reduzir a rotatividade.
No caso da empresa de serviços profissionais, foi decidido abordar a primeira questão comercial (como é possível prever a composição da equipe, por exemplo, um contador sênior e dois assistentes contábeis, para um novo projeto?). Para esse engajamento do cliente, levou-se em consideração cinco anos de dados do histórico diário dos projetos em nível individual. Foram desconsiderados da análise, todos os dados que tinham uma margem de contribuição negativa ou um número total de horas negativo. Primeiramente, foi retirada uma amostragem, aleatoriamente, de 1000 projetos do conjunto de dados de teste para acelerar o ajuste de parâmetros. Depois de identificar a combinação ideal de parâmetros, foi executada a mesma preparação de dados em todos os projetos no conjunto de dados de teste.
A Figura 3 é uma representação do tipo de dados e fluxo de solução que foi criada para este engajamento:
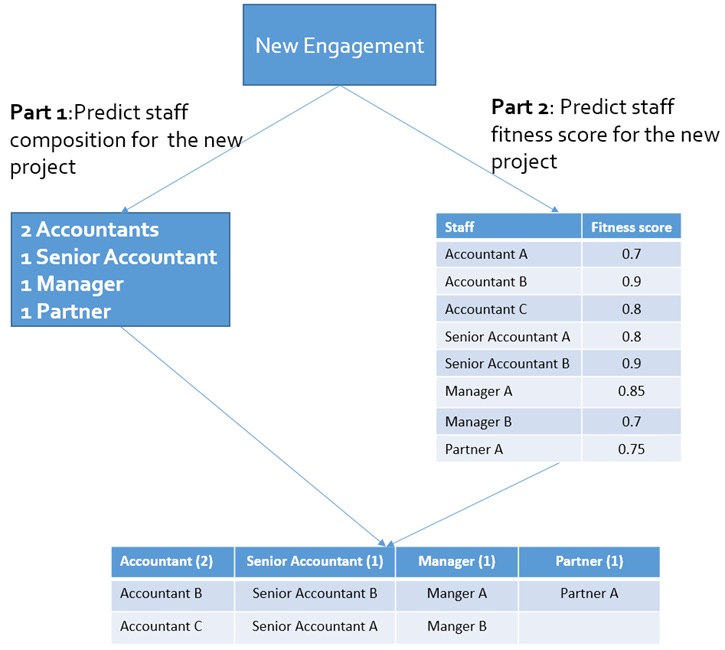
Figura 3. Representação dos tipos de dados e do fluxo da solução.
O método de agrupamento utilizado foi o algoritmo de k vizinhos mais próximos (KNN). O KNN é um algoritmo de aprendizado de máquina supervisionado simples e de fácil implementação que pressupõe que coisas semelhantes existem em estreita proximidade, encontra os pontos de dados mais semelhantes nos dados de treinamento e faz uma previsão com base em suas classificações. Embora simples, esse método tem sido amplamente aplicado em muitos domínios, como em sistemas de recomendação, pesquisa semântica e detecção de anomalias.
Nesta primeira etapa, utilizou-se o KNN para prever a composição da equipe, ou seja, os números de cada classificação / título da equipe, de um novo projeto usando dados históricos do projeto. Foram levantados projetos históricos semelhantes ao novo projeto com base em propriedades como Tipo de Projeto, Cobrança Total, Indústria, Cliente, Faixa de Receita, etc. Atribuiu-se diferentes pesos a cada propriedade do projeto com base em regras e padrões de negócio. Foram excluídos da análise todos os dados que tinham margem de contribuição negativa (lucro). Para cada classificação de equipe, a contagem de pessoal é prevista pelo cálculo de uma soma ponderada de contagens de pessoal de projetos históricos semelhantes. Os pesos finais são normalizados para que a soma de todos os pesos seja 1. Antes de calcular a soma ponderada, remove-se 10% de valores discrepantes altos e 10% de valores discrepantes baixos.
Para a segunda questão de negócio (Como podemos calcular a pontuação de aptidão da equipe para um novo projeto?), foi utilizado um método de filtragem baseado em conteúdo personalizado: especificamente, foi implementado um algoritmo baseado em conteúdo para prever quão bem a experiência da equipe corresponde às necessidades do projeto. Em um sistema de filtragem baseado em conteúdo, um perfil de usuário geralmente é calculado com base nas avaliações históricas dos itens do usuário. Este perfil de usuário descreve as preferências do usuário e para prever a adequação de um novo projeto para a equipe, foi criado dois vetores de perfil da equipe usando dados históricos: um vetor é baseado no número de horas que descreve a experiência e o conhecimento da equipe para diferentes tipos de projetos; o outro baseado na margem de contribuição por hora (CMH), que descreve a lucratividade da equipe para diferentes tipos de projetos. Os Índices de Aptidão da Equipe para um novo projeto são calculados tomando os produtos internos entre esses dois vetores e um vetor binário que descreve os atributos importantes de um projeto.
Essas etapas foram implementadas utilizando o serviço de aprendizado de máquina da Azure. Usando o SDK principal em Python e o Data Prep SDK de machine learning da Azure, os modelos foram criados e treinados. Esse ambiente de trabalho é o recurso de nível superior para o serviço e fornece um local centralizado para trabalhar com todos os artefatos que foram desenvolvidos para o projeto.
Para criar um ambiente de trabalho, foram definidas as seguintes configurações:
|
Campo |
Descrição |
|
Nome do ambiente de trabalho |
Um nome exclusivo que identifique o ambiente de trabalho. Os nomes devem ser exclusivos em todo o grupo de recursos. Um nome fácil de lembrar e diferencie de espaços de trabalho criados por outras pessoas. |
|
Inscrição |
A assinatura da Azure a ser utilizada. |
|
Grupo de recursos |
Grupo de recursos existente na assinatura ou um nome para criar um novo grupo de recursos. Um grupo de recursos é um contêiner que contém recursos relacionados para uma solução da Azure. |
|
Localização |
O local mais próximo dos usuários e os recursos de dados. Este local é onde o ambiente de trabalho é criado. |
Quando um ambiente de trabalho é criado, os seguintes recursos da Azure são adicionados automaticamente:
O ambiente de trabalho mantém uma lista de objetivos computacionais que podem ser utilizados para treinar o modelo e também mantém um histórico das execuções de treinamento, incluindo registros, métricas, saída e um snapshot de seus scripts. Essas informações são utilizadas para determinar qual execução de treinamento produz o melhor modelo.
Após essas etapas os modelos são registrados no ambiente de trabalho, e são utilizados, juntamente com os scripts de pontuação para criar uma imagem que será usada na implantação (mais detalhes sobre a arquitetura de ponta a ponta criada para esse caso de uso serão discutidos a seguir). A Figura 4 apresenta uma representação do conceito de ambiente de trabalho e fluxo de aprendizado de máquina:

Figura 4. Concepção da área de trabalho e do fluxo do aprendizado de máquina
Princípio 3: Projetar a arquitetura da solução ponta a ponta
Na era do Big Data, há uma tendência crescente de acumulação e análise de dados, muitas vezes não estruturados, provenientes de aplicativos, ambientes web e uma grande variedade de dispositivos. Nesta terceira etapa, as organizações precisam pensar mais organicamente em como o fluxo de dados de ponta a ponta e a arquitetura que suportará suas soluções de ciência de dados, e para isso pensar nas seguintes perguntas:
- O volume de dados é realmente necessário?
- Como as organizações garantem a integridade e confiabilidade dos dados?
- Como os dados devem ser armazenados, tratados e manipulados para responder às perguntas e necessidades de negócio?
- O mais importante, como os dados integrarão essa solução de ciência de dados em seus próprios negócios e operações para consumi-los com sucesso ao longo do tempo?
Arquitetura de dados é o processo de planejamento da coleta de dados, incluindo a definição das informações a serem coletadas, os padrões e normas que serão utilizadas para sua estruturação e as ferramentas utilizadas na extração, armazenamento e processamento desses dados.
Esta etapa é fundamental para qualquer projeto que realize análise de dados, pois é nessa etapa que são garantidas a disponibilidade e integridade das informações que serão exploradas no futuro. Para isso é necessário entender como os dados serão armazenados, processados e utilizados, bem como quais análises serão esperadas para o projeto. Pode-se dizer que neste ponto há uma intersecção das visões técnicas e estratégicas do projeto, uma vez que o objetivo desta tarefa de planejamento é manter os processos de extração e manipulação de dados alinhados com os objetivos do negócio.
Depois de definir os objetivos de negócio (Princípio 1) e traduzi-los em métricas tangíveis (Princípio 2), agora é necessário selecionar as ferramentas certas que permitirão que uma organização realmente crie uma solução de Ciência de Dados de ponta a ponta. Fatores como volume, variedade de dados e a velocidade com que são gerados e processados ajudarão as empresas a identificar quais tipos de tecnologia devem usar. Entre as várias categorias existentes, é importante considerar:
- Ferramentas de coleta de dados, como o Azure Stream Analytics e o Azure Data Factory são as utilizadas nesse projeto para a extração e organização de dados brutos;
- Ferramentas de armazenamento, como o Azure Cosmos DB e o Azure Storage, armazenam dados no formato estruturado ou não estruturado e podem agregar informações de várias plataformas de maneira integrada;
- Ferramentas de processamento e análise de dados, como o Azure Time Series Insights e o Azure Machine Learning Data Prep, utilizam os dados armazenados e processados e para criar uma lógica de visualização que permitem o desenvolvimento de análises, estudos e relatórios que suportam decisões operacionais e estratégicas;
- Ferramentas de operacionalização do modelo, como o serviço de machine learning da Azure e o Machine Learning Server são utilizadas para que, após uma organização ter um conjunto de modelos com bom desempenho, poder operacionalizá-los para o consumo de outros aplicativos. Dependendo dos requisitos do negócio, as previsões são feitas em tempo real ou em lotes. Para implantar modelos, as empresas precisam expô-los com uma interface de API aberta que permita que o modelo seja facilmente consumido de várias aplicações, como:
- Sites online;
- Planilhas;
- Dashboards;
- Aplicativos de linha de negócios (LoB);
- Aplicações back-end.
As ferramentas podem variar de acordo com as necessidades do negócio, mas idealmente devem oferecer a possibilidade de integração entre elas para permitir que os dados sejam utilizados em qualquer uma das plataformas escolhidas que seja necessário tratamentos manuais. Essa arquitetura ponta-a-ponta (Figura 5) também oferece algumas vantagens e valores importantes para as empresas, como:
 Figura 5. Exemplo de arquitetura ponta a ponta
Figura 5. Exemplo de arquitetura ponta a ponta
- Implementação com menor tempo e risco reduzido: uma arquitetura integrada de ponta a ponta pode minimizar o custo e o esforço necessários para projetar uma solução, além de permitir um tempo mais rápido para implantar casos de uso;
- Componentização: permite que as empresas iniciem em qualquer parte o projeto de arquitetura de ponta a ponta com a garantia de que os componentes principais serão integrados e se encaixam;
- Flexibilidade: Interoperabilidade, possibilidade de execução em qualquer tipo de ambiente, incluindo ambientes multi-nuvem ou nuvem híbrida;
- Análise de ponta a ponta e aprendizado de máquina: permite uma visão analítica de ponta a ponta, com a capacidade de levar os modelos de aprendizado de máquina de volta ao limite para a tomada de decisões em tempo real;
- Segurança e conformidade de dados de ponta a ponta: segurança e capacidade de gerenciamento pré-integradas em toda a arquitetura, incluindo acesso, autorização e autenticação;
- Permitindo a inovação com código aberto: construído a partir de projetos de código aberto e um modelo vibrante de inovação da comunidade que garante padrões abertos.
No caso da empresa de serviços profissionais, a arquitetura da solução consiste nos seguintes componentes (Figura 6):

Figura 6. Arquitetura de ponta a ponta desenvolvida pela equipe Microsoft Azura ML.
1. Os cientistas de dados treinaram um modelo usando serviço de aprendizado de máquina da Azure e um cluster do HDInsight. O Azure HDInsight é um serviço de análise de código aberto gerenciado e de amplo espectro para empresas e por ser um serviço de nuvem torna fácil, rápido e econômico para o processamento de grandes quantidades de dados. O modelo é contêinerizado e colocado em um registro de contêiner da Azure, o Azure Container Registry permite criar, armazenar e gerenciar imagens para todos os tipos de implantações de contêiner. Para o projeto específico do cliente, foi criada uma instância do Azure Container Registry usando o Azure CLI. Em seguida, foi utilizado os comandos do Docker para enviar uma imagem do contêiner ao registro e, finalmente, extrair e executar a imagem do registro. O Azure CLI (command line interface) é uma ferramenta de linha de comando cujos pontos positivos são: ótima experiência para o gerenciamento de recursos da Azure e foi projetada para facilitar a criação de scripts, consultar dados, oferecer suporte a operações de longa duração.
2. O modelo foi implantado utilizando um instalador offline em um cluster do Kubernetes no Azure Stack. O Serviço de Kubernetes do Azure (AKS) simplifica o gerenciamento do Kubernetes, permitindo o provisionamento fácil de clusters por meio de ferramentas como o Azure CLI e simplificando a manutenção do cluster com atualizações e escalonamento automatizados. Além disso, a capacidade de criar clusters de GPU permite que o AKS seja usado para serviço de alto desempenho e escalonamento automático de modelos de aprendizado de máquina.
3. Os usuários finais fornecem dados que são pontuados no modelo. O processo de aplicar um modelo preditivo a um conjunto de dados é chamado de escoragem dos dados. Uma vez que um modelo tenha sido construído, as especificações do modelo podem ser salvas em um arquivo que contém todas as informações necessárias para reconstruir o modelo, sendo possível utilizar esse arquivo para gerar pontuações preditivas em outros conjuntos de dados.
4. Insights e anomalias de pontuação são colocados no armazenamento para upload posterior. O armazenamento do Azure Blob é usado para armazenar todos os dados do projeto e se integra ao Serviço de Aprendizado de Máquina da Azure para que os usuários não precisem mover dados manualmente pelas plataformas de computação e pelo armazenamento do Blob. O armazenamento de blobs também é muito econômico para o desempenho exigido para essa carga de trabalho.
5. Insights relevantes e compatíveis globalmente estão disponíveis no aplicativo global, o Azure App Service é um serviço que hospeda aplicativos da Web, APIs REST e back ends móveis e tem como benefícios: segurança, balanceamento de carga, escalonamento automático e gerenciamento automatizado, sendo possível também a utilização dos recursos de DevOps, como a implantação contínua do DevOps do Azure, do GitHub, do Docker Hub e de outras fontes, gerenciamento de pacotes, ambientes de preparação, domínio personalizado e certificados SSL.
6. Finalmente, os dados da cujas pontuações estão próximas ao limite são usados para melhorar o modelo.
Princípio 4: Construindo uma suite de ferramentas personalizadas para Ciência de Dados
Ao trabalhar na solução de alocação de pessoal com base em recomendação para o caso da empresa de serviços profissionais, foi observado imediatamente que a empresa possuía recursos limitados de tempo e não tinha uma quantidade infinita de recursos de computação, isso posto: como as organizações podem organizar seu trabalho para que possam manter o máximo de produtividade?
Esse projeto foi realizado em estreita colaboração com a equipe de Ciência de Dados do cliente e um dos trabalhos principais foi definir os pontos que pudessem otimizar seu trabalho e acelerar o tempo de produção, por exemplo:
- Inicialmente treinar o modelo em um subconjunto de informações muito menor do que todo o conjunto de dados: uma vez que as equipes de ciência de dados tenham uma compreensão clara do que precisam alcançar em termos de recursos, função de perda, métricas e valores de hiperparâmetros, dimensione as necessidades;
- Reutilizar conhecimentos adquiridos de projetos anteriores: muitos problemas de ciência de dados são semelhantes entre si e reutilizar os melhores valores de hiperparâmetros ou extratores de recursos de problemas semelhantes que outros cientistas de dados resolveram no passado economizará muito tempo no desenvolvimento;
- Configuração de alertas automatizados que informarão às equipes de ciência de dados que um experimento específico acabou: isso economizará tempo das equipes de ciência de dados caso algo dê errado com o experimento;
- Utilização dos notebooks da Jupyter para prototipagem rápida: os cientistas de dados podem reescrever seu código em pacotes / classes do Python, uma vez que estejam satisfeitos com o resultado;
- Mantenha o código usado na experimentação em um sistema de controle de versão, como o GitHub;
- Utilização de ambientes pré-configurados na nuvem para desenvolvimento de ciência de dados: são imagens de máquina virtual (como Máquinas Virtuais do Windows e Máquina Virtual de Ciência de Dados do Azure), pré-instaladas, configuradas e testadas com várias ferramentas populares usadas para análise de dados e treinamento em aprendizado de máquina;
- Importante também manter uma lista de coisas para fazer enquanto as experiências estão sendo executadas, por exemplo: coleta de dados, limpeza, anotação; lendo sobre novos tópicos de ciência de dados, experimentando um novo algoritmo ou framework. Todas essas atividades contribuirão para o sucesso de projetos futuros. Alguns sites sugeridos da Data Science são: Data Science Central, KDnuggets, Revolution Analytics.
Princípio 5: Unificar a visão da organização a respeito da Ciência de Dados
Desde o primeiro dia de um processo de ciência de dados, as equipes de ciência de dados devem interagir com os parceiros de negócios. Cientistas de dados e parceiros de negócios entram em contato com a solução com pouca frequência. Os parceiros de negócios querem ficar longe dos detalhes técnicos e dos cientistas de dados das empresas. No entanto, é essencial manter uma interação constante para entender a implementação do modelo paralelo à construção do modelo. A maioria das organizações luta para desbloquear a ciência de dados para otimizar seus processos operacionais e fazer com que cientistas de dados, analistas e equipes de negócios falem a mesma linguagem: equipes diferentes e o processo de ciência de dados são muitas vezes uma fonte de atrito. Esse atrito é o que define o novo triângulo de ferro da ciência de dados e é baseado em uma orquestração harmônica da ciência de dados, operações de TI e operações de negócios.
Para realizar essa tarefa, no estudo de caso deste trabalho, foi implementado as seguintes etapas:
- Solicite o apoio de um executivo de nível C para ter essa visão e conduzi-la pelas diferentes partes do negócio: em que há um propósito, visão e patrocínio claros, o sabor do sucesso inicial ou dos primeiros ganhos estimula mais a experimentação e a exploração, resultando em um efeito dominó de mudança positiva;
- Construa uma cultura de experimentação: mesmo em situações em que há um objetivo claramente articulado, isso, por si só, muitas vezes não leva a uma transformação de negócios bem-sucedida. Um obstáculo importante em muitas organizações é o fato de que os funcionários não têm poder suficiente para provocar mudanças. Ter uma força de trabalho capacitada ajuda a envolver seus funcionários e os envolve ativamente na contribuição para um objetivo comum.
Envolva todos na conversa: criar consenso irá aumentar o desempenho muscular. Se os cientistas de dados trabalharem em silos sem envolver os outros, a organização não terá visão compartilhada, valores e propósito comum. É a visão compartilhada e o propósito comum da organização em várias equipes que fornecem um aumento sinérgico.
Princípio 6: Mantenha as pessoas envolvidas
Tornar-se uma empresa orientada por dados é mais uma mudança cultural do que números: por esse motivo, é importante que as pessoas avaliem os resultados de qualquer solução de ciência de dados. A formação de equipes de dados com envolvimento das pessoas resultará em melhores resultados do que qualquer um sozinho forneceria.
Por exemplo, no caso de estudo de projeto, utilizar a combinação de ciência de dados e experiência humana ajudou-os a criar, implantar e manter uma solução de recomendação de colocação de equipes e que muitas vezes levou a ganhos financeiros. Depois de implantar a solução, a organização decidiu conduzir um piloto com algumas equipes de projeto. Eles também criaram uma equipe de cientistas de dados e especialistas em negócios cuja finalidade era trabalhar em paralelo com a solução de aprendizado de máquina e comparar os resultados de aprendizado de máquina em termos de tempo de conclusão do projeto, receita gerada, funcionários e satisfação do cliente dessas duas equipes piloto, isso antes e depois de usar a solução do Azure Machine Learning. Essa avaliação off-line conduzida por uma equipe de especialistas em dados e negócios foi muito benéfica para o projeto em si por duas razões principais:
1. Confirmou que a solução de aprendizado de máquina foi capaz de melhorar ~ 4/5% da margem de contribuição para cada projeto;
2. A equipe V foi capaz de testar a solução e criar um mecanismo sólido de feedback imediato que permitiu monitorar constantemente os resultados e melhorar a solução final.
Após esses projetos piloto, a empresa integrou com sucesso a solução em seu sistema interno de gerenciamento de projetos.
Existem algumas diretrizes que as empresas devem ter em mente ao iniciar essa mudança cultural orientada por dados:
- Trabalhando lado a lado: as empresas líderes reconhecem cada vez mais que essas tecnologias são mais eficazes quando complementam os seres humanos e não os substituem. Entender os recursos exclusivos que a ciência de dados e os humanos trazem para diferentes tipos de trabalho e tarefas será essencial à medida que a ênfase passa da automação para o replanejamento do trabalho;
- Reconhecendo o toque humano: é importante lembrar que mesmo os trabalhos com maiores níveis de informatização precisam manter um aspecto orientado a serviços e ser interpretativos para serem bem-sucedidos para a empresa - esses papéis, como cientistas de dados e desenvolvedores, ainda precisam ser essenciais. Habilidades humanas de criatividade, empatia, comunicação e solução complexa de problemas;
- Investir no desenvolvimento da força de trabalho: um foco renovado e imaginativo no desenvolvimento da força de trabalho, aprendizagem e modelos de carreira também será importante. Talvez o mais crítico de todos seja a necessidade de criar um trabalho significativo - trabalho que, apesar de sua nova colaboração com máquinas inteligentes, os seres humanos estarão ansiosos para abraçar.
O componente humano será especialmente importante nos casos de uso em que a ciência de dados precisaria de arquiteturas adicionais, atualmente proibitivamente caras, como vastos gráficos de conhecimento para fornecer contexto e suplantar a experiência humana em cada domínio.
Conclusão
Ao aplicar esses seis princípios para construção de um modelo sustentável de Ciência de Dados no processo de análise de dados, as organizações podem tomar melhores decisões para seus negócios. Suas escolhas serão apoiadas por dados que foram coletados e analisados de forma robusta.
No caso de estudo, a organização conseguiu implementar uma solução de ciência de dados bem-sucedida que recomenda a composição ideal da equipe e ao alinhar a experiência da equipe com as necessidades do projeto, os gerentes de projeto foram auxiliados na composição de uma alocação de pessoal melhor e mais rápida.
Com a prática, os processos de ciência de dados ficarão mais rápidos e precisos - o que significa que as organizações podem tomar decisões melhores e mais informadas para executar as operações com mais eficiência.
A seguir estão alguns recursos úteis adicionais para aprender mais como nutrir uma mentalidade de ciência de dados saudável e construir uma organização orientada a dados de sucesso:
- Documentação do processo da equipe de Ciência de Dados
- Repositório GitHub do processo da equipe de Ciência de Dados
- Architecture Guia Arquitetura de Dados
- Anotações da Azure
- Máquina Virtual Ciência de Dados
- Documentação Azure Machine Learning
- Blog Microsoft Azure Data Science
Sobre a autora
 Francesca Lazzeri, PhD (Twitter: @frlazzeri) é cientista de aprendizado de máquina sênior na Microsoft, atuando na equipe de apoio das soluções em nuvem e especialista em inovações em tecnologia de big data e aplicações de soluções baseadas em aprendizado de máquina para problemas do mundo real. É autora do livro “Time Series Forecasting: A Machine Learning Approach” (O'Reilly Media, 2019) e ministra periodicamente aulas de análise aplicada e aprendizado de máquina em universidades dos EUA e da Europa. Antes de ingressar na Microsoft, foi bolsista de pesquisa em economia comercial na Harvard Business School, onde realizou análises estatísticas e econométricas na unidade de gerenciamento de operações e tecnologia. Também é mentora de Ciência de Dados para alunos de PhD e pós-doutorado no Massachusetts Institute of Technology (MIT), oradora principal e palestrante em conferências acadêmicas do setor, compartilhando seu conhecimento e paixão por IA, aprendizado de máquina e codificação.
Francesca Lazzeri, PhD (Twitter: @frlazzeri) é cientista de aprendizado de máquina sênior na Microsoft, atuando na equipe de apoio das soluções em nuvem e especialista em inovações em tecnologia de big data e aplicações de soluções baseadas em aprendizado de máquina para problemas do mundo real. É autora do livro “Time Series Forecasting: A Machine Learning Approach” (O'Reilly Media, 2019) e ministra periodicamente aulas de análise aplicada e aprendizado de máquina em universidades dos EUA e da Europa. Antes de ingressar na Microsoft, foi bolsista de pesquisa em economia comercial na Harvard Business School, onde realizou análises estatísticas e econométricas na unidade de gerenciamento de operações e tecnologia. Também é mentora de Ciência de Dados para alunos de PhD e pós-doutorado no Massachusetts Institute of Technology (MIT), oradora principal e palestrante em conferências acadêmicas do setor, compartilhando seu conhecimento e paixão por IA, aprendizado de máquina e codificação.