Pontos Principais
- O suporte a sistemas de alta disponibilidade deve se adaptar à evolução dos modelos arquiteturais e organização das equipes;
- Dominar um sistema significa que precisamos examinar mais do que as entregas do negócio;
- Construir e dar suporte a um sistema tecnicamente complexo usando cinco boas práticas;
- Repensar o suporte, automação, captura de erros, compreender o que seus clientes realmente se preocupam e uma combinação sólida de quebrar coisas e prática, é a melhor esperança para uma boa noite de sono.
Estamos construindo sistemas distribuídos realmente complicados. O aumento da adoção de microservices, alimentado pela migração para nuvem, na qual as arquiteturas e infraestruturas podem ser flexíveis e efêmeras, adiciona complexidade todo dia aos sistemas que criamos e mantemos. Toda esta complexidade acontece aliada a modelos de operação com equipes autônomas e com total liberdade, sendo assim, cada sistema distribuído tem o próprio conjunto de abordagens técnicas, linguagens e serviços.
Apesar destas complicações, é graças a essas tecnologias que podemos construir um sistema tecnicamente complexo e dar suporte a ele, usando um conjunto de boas práticas, acumuladas a partir da experiência no desenvolvimento de uma nova geração de APIs, em um horizonte completamente novo.
Complexidade é o custo da flexibilidade
Imagem: rastreamento de serviços da Skyscanner.
Microservices são autônomos e empacotáveis, e somos capazes de fazer a implantação de forma independente, sem ficar preso a uma longa operação de deploy. Como são nativos na nuvem, temos uma grande flexibilidade no quesito escalabilidade. Porém, essas novas abordagens e capacidades técnicas são usadas para finalidades organizacionais, como escalar as equipes sem perder o ritmo, e não para reduzir complexidade técnica. Portanto, tudo isso leva a um custo operacional e uma crescente complexidade.
Martin Fowler fala dos trade-offs dos microsserviços, como sendo:
Complexidade Operacional: é necessário uma equipe de operações madura para gerenciar vários serviços, que estão sendo regularmente reimplantados.
Durante o tempo que trabalhei no Financial Times, tive a oportunidade de ajudar a equipe a construir uma nova geração de APIs de conteúdo com grande liberdade. Tínhamos autonomia - uma equipe auto organizada que pode escolher como re-arquitetar, implantar e manter todas as novas funcionalidades. Pudemos escolher todos os aspectos do conjunto de tecnologias, além de podermos definir também o modelo de suporte - tínhamos toda responsabilidade e consciência disso, então desenvolvemos com isso em mente. Esta responsabilidade nos fez ver o modelo de suporte e operação de forma diferente dos projetos anteriores.
Inicialmente, a implementação era muito superficial, com as APIs ficando constantemente indisponíveis - ou ainda pior - servindo dados não confiáveis. Isso levou a um consumidor maior, uma nova versão do site ft.com, e protegemos armazenando dados em cache para o caso da API cair. Quando chegou a data de entrada de operação deste novo site, eles queriam que déssemos garantias - acordos de nível de serviço (SLAs).
A coisa mais importante para o Financial Times é notícia de última hora. Éramos, portanto, questionados a ter um SLA muito apertado de 15 minutos de recuperação para as APIs envolvendo notícias de últimas horas. Ora, isso é muito difícil, especialmente no caso de ter grandes quantidades de dados armazenados por debaixo dos panos. Este SLA não trouxe apenas uma quantidade de desafios técnicos, mas também vários desafios organizacionais, como o suporte fora do expediente. Por sorte tínhamos autonomia para definir como fazer isso da melhor maneira possível. Ao fazer isso foi possível eliminar virtualmente os atendimentos fora do expediente.
Não construímos um sistema mítico e mágico que era livre de falhas, mas sim um sistema de operação resiliente. Cinco boas práticas nos trouxeram este ponto de resiliência.
1. Capacite o engenheiro
Isso é a parte mais importante da construção de um sistema resiliente. Todo engenheiro deve começar a pensar na operabilidade como um conceito primário, não como uma consequência. Cada engenheiro deve começar questionando suas implementações continuamente - "O que quero que aconteça se houver algum erro: ser chamado independentemente do tempo? Executar novamente? Registrar um log para analisar depois (possivelmente)?"
Estamos trabalhando agora ou ao menos mudando para equipes ou squads autônomos com total liberdade. Esta abordagem dá não só responsabilidade, mas também uma influência sobre o modelo de suporte que se quer usar. Não importa se está atuando em um modelo tradicional de uma empresa dedicada a isso, equipe de suporte de linha de frente, ou equipes que são chamadas diretamente por meio de ferramentas como bipes.
Claro que trabalhando com outras equipes complica o processo, mas pode também tirar a pressão dos engenheiros - isso é um trade-off e com frequência depende do modelo adotado na empresa. As equipes precisam definir como trabalham juntas da melhor forma e se certificar que tem as ferramentas adequadas. Acima de tudo, para as equipes trabalharem de forma efetiva, elas precisam cultivar e evoluir os relacionamentos dentro de cada equipe e a colaboração entre as equipes.
Repensando o suporte fora do expediente
Quando o SLA mudou por conta das APIs de conteúdo com o lançamento do novo site, houve obrigações de suporte fora do expediente. Aproveitamos a oportunidade para avaliar a forma de fazermos isso. Estávamos focados em reduzir a quantidade de horas extras de suporte. Alcançamos isso usando dois grupos de engenheiros, como mostrado na figura a seguir.
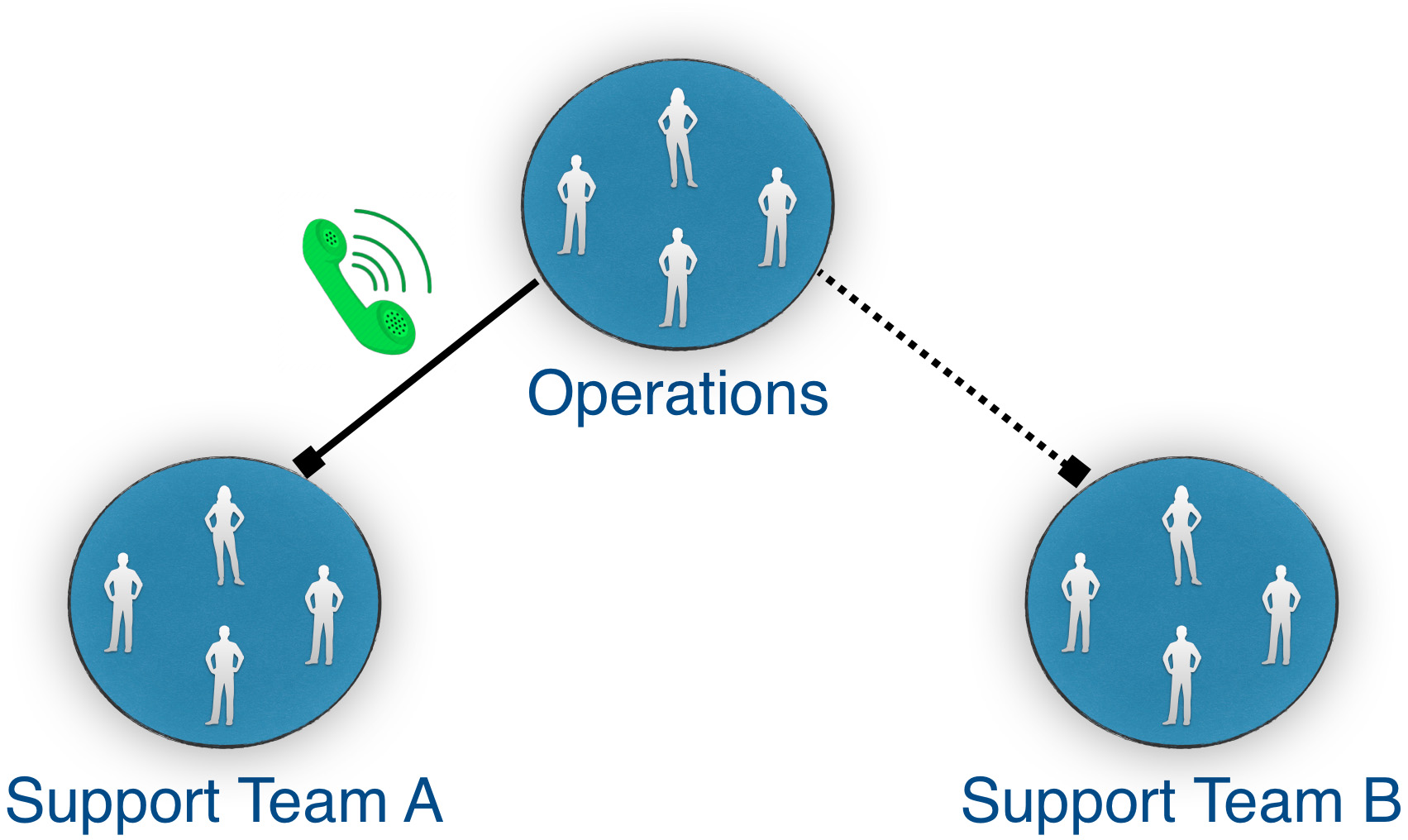
Modelo de suporte definido pelo Content Programme no Financial Times.
A equipe de operações poderia alternar a escala dos engenheiros no grupo, com um grupo ficando "de plantão" a cada semana. Os engenheiros não eram obrigados a cumprir a escala, e se eles não o fizessem, então a próxima pessoa poderia ser escalada. Isso permitiu as pessoas irem ao bar, andar de bicicleta, ou nadar sem a preocupação que poderiam serem chamadas. Este sistema foi totalmente voluntário e bem recompensado - as pessoas recebiam por horas extras se respondessem ao chamado. Isso é importante para reconhecer que algumas pessoas são impossibilitadas de assumir este compromisso, além da importância de reconhecer que isto não é parte do dia a dia do trabalho, sendo assim eles deveriam ser pagos.
Este modelo de suporte também foi aplicado durante a semana. Havia duas pessoas para responder aos incidentes, as dúvidas e trabalhar na melhoria da plataforma e processos operacionais. Eles se revezavam dentro da equipe de engenharia. Essa foi uma função dedicada porque a reconhecemos, como uma função crítica e que nenhuma melhoria operacional poderia acontecer se eles não estivessem trabalhando alocados em um projeto. Além disso, significava que os engenheiros estavam aumentando os pull requests em todas as áreas, não apenas naquelas que já estavam familiarizados. Essa forma de lidar com os problemas foi um aspecto importante. Ajudou a reforçar a confiança dos engenheiros em lidar com os chamados fora do expediente e encorajá-los a pensar de forma operacional quando estavam implementando as funcionalidades do negócio. O sofrimento das más práticas poderia afligi-los durante a escala, ou pior ainda, às 3 da manhã.

As pessoas projetam sistemas diferente se elas entendem que o código pode resultar em um chamado fora do expediente. "Este erro irá afetar o negócio?" Para o Financial Times, a questão sempre foi, "Este erro irá afetar a marca?" Porém, para o negócio pode ser muito mais ruim se está trabalhando em um hospital ou estação de energia!
Lidando com erros
A próxima melhoria foi identificar os erros usando os alertas de uma maneira sensata. Pensar sobre os níveis de gravidade é uma forma útil para diferenciar coisas que podem ser resolvidas durante as horas normais. Nem todos os erros que chegam são causados por questões relacionadas a funcionalidades primárias do sistema. Aqui está um exemplo do que adotamos:

O nível de gravidade é claramente declarado nos dados da verificação de saúde do sistema.
A plataforma usa containers, no início fazíamos tudo manualmente até migrarmos para Kubernetes. Queríamos saber imediatamente quando a plataforma estava impossibilitada de executar atividades críticas do negócio, como publicar um conteúdo. Porém, havia alguns serviços que não funcionavam e poderiam ser restabelecidos em horas, durante a folga. O exemplo anterior mostra a página para verificar a saúde, que consolida o status de saúde e gravidade da plataforma inteira, e dependendo da situação alguém pode ser chamado. Entretanto, no exemplo mostrado, já estamos avisados que temos uma versão do CoreOS desatualizada, o sistema operacional do container que usamos. Este aviso era muito importante para ser tratado, porque poderia ter um ponto crítico de segurança; mas isso não precisa ser feito às 3 horas da madrugada de um domingo. Isso pode ser resolvido depois do café da manhã na segunda-feira.
Os engenheiros podem lidar com as questões que lhe são encaminhadas, tão bem quanto olhar para trás e manter as aplicações legadas atualizadas conforme o estilo operacional é refinado.
A lei de evolução de software de Lehman diz:
A qualidade de um sistema parecerá estar caindo a menos que ela seja rigorosamente mantida."
Como um sistema evolui, sua complexidade também aumenta a menos que se trabalhe para mantê-la ou reduzi-la."
Isso pode ser aplicado a implementações técnicas e ao modelo de suporte. Os engenheiros devem manter e elevar os aspectos operacionais do sistema para mantê-lo funcionando de acordo com o que foi solicitado.
2. Evite chamados fora do expediente, pegando mais chamados no horário comercial
Esta é provavelmente a maior categoria, responsável pelos chamados fora do expediente. Porém há algumas coisas que podemos fazer para reduzir essa probabilidade.
Implantações
As implantações são as grandes culpadas. Mesmo no melhor dos mundos, não podemos garantir totalmente que a implantação está livre de problemas. Cenários que não foram cobertos - um pequeno "vazamento" de uma questão torna-se mais perceptível ao longo das horas, ou semanas. Implantações estão sempre levando ao aumento da chance de chamados, mas podemos fazer algumas coisas para reduzir este risco.
Não é uma solução parar de fazer as implantação às 5 horas da tarde. O medo das implantações feitas a tarde é um bom indicador que há pouca confiança no processo ou com a equipe de suporte a implantações. Claro, há sempre um balanceamento do risco:
- Qual é o impacto dessa implantação?
- Quão rápido podemos voltar a versão?
- Quanto confiante estou de que esta implantação não vai quebrar as coisas?
Charity Majors postou em seu blog sobre isso, comparando o medo da sexta-feira ao "assassinato de filhotinhos":

De "Friday Deploy Freezes Are Exactly Like Murdering Puppies" postado por @mipsytipsy.
Os deploys devem ser tão rápidos quanto possível; não subestime o tempo de atenção das pessoas. Se demorar muito tempo, as pessoas vão sair e pegar uma xícara de chá ou pior ainda, vão para casa antes de verificar se o deploy foi feito corretamente. Se não é possível fazer a implantação de forma super rápida, então garanta que irá certificar que a implantação foi feita com sucesso. Um simples alerta no Slack enviado pelo CI pode ser suficiente. Por outro lado, pode-se automatizar esta verificação.
Uma vez em produção, deve ter uma maneira de verificar, mas esta maneira não precisa ser sofisticada. Isso significa fazer testes em produção, e que não seja tão terrível quanto isso possa soar. Não estou dizendo para alguém jogar o código em produção e esperar pelo melhor. Algumas opções:
- Tenha os detalhes de produção e seja capaz de executar um teste manual;
- Use feature flags com um pequeno número de usuários expostos às mudanças iniciais;
- Desabilite as novas funcionalidades durante a noite, enquanto ganha confiança na nova versão;
- Reenvie constantemente requisições para descobrir problemas o quanto antes.
James Governor chamou isso de "Entrega Progressiva" e Cindy Sridharan também fala deste teste em produção.
Além das implantações, há outro ponto que pode aumentar ainda mais as chances de ser chamado no meio da noite - processos em lote.
Processos em lote
Processos em lote fazem todo o trabalho pesado de uma tarefa no meio da noite, significa que levará um tempo para receber o retorno, e o retorno será exatamente na hora não esperada.
A próxima figura ilustra isso:

Um sistema de pedidos que pega um pedido em tempo real, mas transforma ele às 3 horas da manhã.
Aqui temos um simples sistema de pedidos, que pega os pedidos usando uma forma orientada a eventos. Porém, ele agrega e transforma todos estes pedidos às 3 horas da manhã, antes de enviar a um terceiro para reconciliação.
Se podemos mover uma parte desta computação pesada para acontecer durante o dia, conseguimos transferir a chamada para o horário comercial, como mostrado a seguir:

Um sistema de pedidos melhorados que mudou o aspecto de transformação para tempo real.
Então, se transformamos e agregamos os pedidos em tempo real, a tarefa às 3 horas da manhã será simplesmente colocar o arquivo no FTP do terceiro.
3. Automatize recuperação de falhas sempre que possível
Não acorde para fazer uma coisa que um computador pode fazer; computadores sempre irão fazer da melhor forma.
A melhor coisa que abriu o caminho para automação é que temos agora todas as ferramentas em nuvem e suas abordagens. Se gosta de serverless ou containers, ambos te dão uma escala de automação que antes poderiam ser uma mão na roda.
O Kubernetes monitora a saúde dos seus serviços e reinicia sob demanda; ele também mudará seus serviços quando "achar" que tornou-se indisponível. O serverless vai enviar novamente as requisições que serão capturadas pelo sistema de alerta do seu fornecedor.
Estas plataformas vieram de uma longa jornada, mas elas ainda são boas como as aplicações que escrevemos. Precisamos escrever código sabendo como serão executados, e como podem ser automaticamente recuperados.
Desenvolva aplicações que podem se recuperar sem ajuda de humanos
Garanta que suas aplicações tenham as seguintes características:
- Finalizar de forma elegante: finalizar aplicações deve ser considerado uma norma, não uma exceção. Se perde um nó do cluster de Kubernetes, então o Kubernetes precisará alocar as aplicações em uma VM diferente;
- Transacional: certifique que a aplicação pode falhar em qualquer ponto e não gerar dados incompletos;
- Reinicialização limpa: com certeza perderemos VMs em nuvem, e é preciso lidar com isso - se é uma nova função sendo executada ou um container sendo movido;
- Baseados em fila: uma forma de dizer à aplicação em que ponto parou, caso tenham parado - voltar o processamento de onde parou;
- Idempotência: isso significa que requisições repetidas vão ter a mesma saída, e é realmente útil para ser capaz de replicar eventos que falharam;
- Não guardar estado: microservices que não guardam estado são muito fáceis de serem movidos; então sempre que possível, faça-os sem guardar estado.
Permitir a possibilidade de uma falha completa do sistema
Há também técnicas para lidar com situações quando uma interrupção acontece em um serviço, ou quando o impacto da interrupção ainda não é conhecido. Uma dessas técnicas é executar a plataforma em mais de uma região, então se tem problemas em uma região, pode recuperar em outra região.
Por exemplo, no Financial Times, tínhamos uma configuração active-active, no qual o cluster inteiro estava executando na Europa e nos Estados Unidos, e as requisições são roteadas de acordo com a localização, como mostrado a seguir:

Um sistema implantado em várias regiões, usando abordagem ACTIVE/ACTIVE.
Temos o monitoramento da saúde de cada cluster, e se qualquer um deles estiverem em nível crítico, poderemos direcionar todo tráfico a outro cluster. Na recuperação, podemos automaticamente voltar a servir de ambos. Se tem uma configuração active-passive pode ser necessário definir alguma rotina para o estado de recuperação e verificação em suas opções para recuperação de falha.
4. Saiba o que é importante para os clientes
Saber o que realmente importa para os clientes não é, na verdade, como se deve pensar primeiramente, porque se perguntá-los, eles dirão "tudo!". Quando conhecemos o domínio, entendemos a natureza da gravidade de certas funcionalidades. Por exemplo, no Financial Times, a marca é completamente importante e ligado a isso está a necessidade de publicar as notícias de última hora, então enquanto estava trabalhando na plataforma de conteúdo visamos como pontos importantes a publicação e a capacidade de ler conteúdo.
Uma vez que entendemos os fluxos importantes, é preciso saber quando as coisas estão quebradas ANTES do cliente. Não deixe os clientes serem os primeiros a informar as interrupções ou problemas. Certifique-se de receber alertas caso tenha problema com algum fluxo importante, sem causar ruído com o cliente.
Tenha apenas alertas que necessitam de alguma ação.
- Sarah Wells, Diretora de Operações e Confiabilidade no Financial Times
"Fadiga de alertas" significa que se é alertado sobre todo erro, torna-se praticamente cego para estes alertas. Tenha apenas alertas para coisas que irá tomar alguma ação imediatamente, mesmo se esse alerta seja de um erro que não tem nenhum planejamento, porque poderá lidar com ele, se e quando ele se tornar importante ao sistema. Tenha logs para consultar posteriormente, caso queira resolver os problemas que não possuem alerta. Depois de tudo, não há nada como um sistema perfeito.
Nem todas as aplicações são iguais. Tenha alertas apenas de aplicações importantes que afetam os fluxos do negócio que foram identificados, anteriormente. Algumas quedas precisam de um suporte imediato, enquanto outras podem ficar para depois do café no dia seguinte.
Ter os alertas no lugar certo é ótimo, mas não queira esperar até que tenha uma falha real e receber o alerta, principalmente se tiver um pico de tráfego. Uma plataforma de conteúdo é um real exemplo disso. O Financial Times é global, mas a maioria do conteúdo é escrito no Reino Unido, então nas primeiras horas da segunda-feira tinha poucas publicações, se houvesse. Então, esta situação parece uma "Schrodinger's platform" - a plataforma está morta ou não há publicações?
Para garantir que tínhamos um fluxo estável de feedback nos fluxos importantes, introduzimos algumas requisições sintéticas, ou simplesmente, republicação de conteúdo que lançamos no sistema continuamente. Isso nos alertava se alguma coisa quebrou com a nova publicação.
Estas requisições sintéticas dava alguns benefícios adicionais bem interessantes - monitoramos os sistemas implantados e estas requisições em ambientes menores, e por fim finalizamos com monitoramento de testes fim a fim.
Instrumentamos o código com rastreamentos rudimentares, que apenas embarcava um identificador da transação. Há agora uma abundância de ferramentas como o Zipkin que fornece um rastreamento mais rico. Ben Sigelman fez uma grande palestra na QCon de Londres em 2019 sobre a importância do rastreamento: "Restoring Confidence in Microservices: Tracing That's More Than Traces."
Este rastreamento permitiu seguir a publicação pelo sistema e reagir quando ela ficar presa em algum lugar durante o processo. Inicialmente escrevemos um serviço que fazia o monitoramento, mas isso se tornou muito inseguro e precisava entender muitas lógicas de negócio espalhadas pelo sistema, que foram vistas como anti padrões no mundo dos microservices. Então mudamos para log estruturado que permite identificar no monitoramento dos eventos. Pudemos então alimentar o Kinesis com estes logs e executar SQL neste fluxo de resultados, como mostrado a seguir:

Análise de logs usando SQL sobre o stream do Kinesis.
Esta abordagem significa que podemos perguntar: "temos todos os resultados esperados dentro de um certo tempo?".
5. Quebre coisas e pratique
Depois de trabalhar usando as boas práticas citadas, pode parecer que fez tudo possível para não ser chamado, mas o que deve ser feito se tudo isso falhar e te chamarem às 3 horas da manhã?
"Engenharia de caos é a maneira de avaliar uma aplicação em produção, com o objetivo de construir a confiança na capacidade do sistema, a fim de suportar condições turbulentas e inesperadas."
Podemos testar o quão resiliente o sistema é desligando pequenas ou grandes partes dele. Isso pode ser feito a nível de sistema, mas pode também ser muito útil quando se testa o elemento humano do suporte operacional.
Quando devemos implantar o chaos monkeys? Todo mundo está em um ponto diferente na jornada de maturidade dos seus sistema, então a resposta é - depende. Porém se está fazendo a jornada comum de migração de um monolito para microservices, então quando vamos começar a experimentar? Obviamente não dá para fazer isso enquanto ainda tem o monolito, porque não pode desligar todo o sistema. Porém não acho que tenha que esperar até estar muito no fim da jornada para fazer este tipo de experiência. Da mesma forma, não precisa implementar tudo automatizado ou elaborar estratégia para obter valor desta experiência. Pode manualmente pegar os serviços ou VMs desligados e ver como o sistema reage.
Há outras formas de avaliar a tolerância do sistema, também. Sobre a plataforma de conteúdo do Financial Times, havia um único ponto de falha na entrada das publicações, como mostrado a seguir:

Uma visão simplificada da plataforma e conteúdos do Financial Times.
Este único ponto de falha era definitivamente uma coisa que queríamos resolver, mas o impacto era muito abrangente, então gerenciamos a alocação de esforço. Isso também foi uma coisa que não causou muita dor como se pode esperar. De fato, nos deu algum benefício - quando queríamos implantar uma atualização, poderíamos falhar em outra região até terminar a implantação.
Então, na realidade, praticamos a tolerância a falha de forma muito normal. Se tem confiança em um mecanismo para processo de suporte rápido, pratique isso regularmente para garantir que continua funcionando e para que diminua o medo e as incertezas do processo. A seguir, temos uma sugestão de práticas, que te ajudaram a ter uma boa noite de sono:
- Construa equipes que entendem o que ser chamado significa, e eles como donos do sistema, são também donos de todos os aspectos do suporte;
- Certifique que o processo de desenvolvimento abrange as melhores práticas para reduzir o risco que causa chamadas a partir de atividades feitas durante o dia;
- Automação da recuperação de falhas está se tornando cada vez mais fácil de se alcançar, então utilize-a o máximo possível;
- Entenda profundamente a necessidade dos clientes para tomar medidas rápidas em relação às falhas;
- Não espere até que uma falha catastrófica teste a capacidade de resposta - coloque processos e abordagens em ação para que possa testar todos aspectos do suporte.
Práticas regulares aumentam a confiança no suporte dos sistemas, que por sua vez aumenta a confiança para saber o que fazer se for chamado às 3 horas da manhã.
Sobre a autora
 Nicky Wrightson é atualmente uma engenheira-chefe trabalhando com plataforma de dados na Skyscanner, a engine de busca de viagens do mundo. Antes disso Nicky trabalhou como engenheira-chefe no Financial Times, uma organização de imprensa - lá liderou a troca da plataforma de conteúdos e metadados junto com um novo modelo operacional. Tem paixão por promover mudanças maiores do que apenas a criação de novas arquiteturas baseadas na nuvem, mas também a evolução cultural necessária.
Nicky Wrightson é atualmente uma engenheira-chefe trabalhando com plataforma de dados na Skyscanner, a engine de busca de viagens do mundo. Antes disso Nicky trabalhou como engenheira-chefe no Financial Times, uma organização de imprensa - lá liderou a troca da plataforma de conteúdos e metadados junto com um novo modelo operacional. Tem paixão por promover mudanças maiores do que apenas a criação de novas arquiteturas baseadas na nuvem, mas também a evolução cultural necessária.