Pontos Principais
- As técnicas de detecção de fraudes derivam principalmente do ramo de detecção de anomalias do data science;
- Se o conjunto de dados tiver um número suficiente de exemplos de fraude, algoritmos supervisionados de machine learning para classificação como Random Forest e Regressão Logística poderão ser usados para uma detecção de fraude;
- Se o conjunto de dados não tiver exemplos de fraude, podemos usar a abordagem de detecção de discrepâncias usando a técnica de Isolation Forest ou a detecção de anomalias usando o autoencoder neural;
- Depois que o modelo de machine learning for treinado, será avaliado por meio de um conjunto de testes usando métricas como sensibilidade e especificidade ou de Cohen's Kappa.
Com o crescente problema global relacionado a fraudes com cartão de crédito, tornou-se importante que os bancos e as empresas de comércio eletrônico possam detectar transações fraudulentas (antes mesmo que sejam concluídas).
Segundo o Nilson Report, uma publicação que abrange o setor de cartões e pagamentos via mobile, às perdas globais por fraude com cartões totalizaram US$ 22,8 bilhões em 2016, um aumento de 4,4% em relação a 2015. Isso confirma a importância da detecção precoce de fraudes nas transações com cartão de crédito.
A detecção de fraudes é um campo muito amplo e complexo. Ao longo dos anos, várias técnicas foram propostas, principalmente decorrentes do ramo de detecção de anomalias do data science. Dito isto, a maioria dessas técnicas pode ser reduzida para dois cenários principais, dependendo do conjunto de dados disponível:
- Cenário 1: O conjunto de dados possui um número suficiente de exemplos de fraude;
- Cenário 2: O conjunto de dados não possui (ou tem um número desprezível de) exemplos de fraude.
No primeiro cenário, podemos lidar com o problema da detecção de fraude usando o machine learning clássico ou técnicas baseadas em estatísticas. Podemos treinar um modelo do machine learning ou calcular algumas probabilidades para as duas classes (transações legítimas e transações fraudulentas) e aplicar o modelo a novas transações para estimar a legitimidade. Todos os algoritmos de machine learning supervisionados para problemas de classificação funcionam aqui, por exemplo, Random Forest, Regressão Logística, etc.
No segundo cenário, não temos exemplos de transações fraudulentas, portanto, precisamos ser um pouco mais criativos. Como tudo o que temos são exemplos de transações legítimas, precisamos torná-las suficientes. Existem duas opções para isso: podemos tratar a fraude como um desvio ou como uma anomalia e usar uma abordagem consistente. Um exemplo para a abordagem de detecção de discrepâncias é o Isolation Forest. Um exemplo clássico para detecção de anomalia é o autoencoder neural.
Vamos dar uma olhada em como as diferentes técnicas podem ser usadas na prática em um conjunto de dados real. Serão implementados em um conjunto de dados de detecção de fraude do Kaggle. Este conjunto de dados contém 284.807 transações com cartão de crédito, realizadas em setembro de 2013 por titulares de cartões europeus. Cada transação é representada por:
- 28 componentes principais extraídos dos dados originais;
- O horário da primeira transação no conjunto de dados;
- O valor da transação.
As transações têm dois rótulos: 1 para transações fraudulentas e 0 para transações legítimas (normais). Apenas 492 (0,2%) transações do conjunto de dados são fraudulentas, que não são consideradas muitas, mas ainda pode ser o suficiente para fazer algum treinamento supervisionado.
Observe que alguns dados contêm componentes principais ao invés dos recursos originais da transação, por motivos de privacidade.
Cenário 1: Machine learning supervisionado: Random Forest
Vamos começar com o primeiro cenário em que assumimos que um conjunto de dados rotulado está disponível para treinar um algoritmo de machine learning supervisionado em um problema de classificação. Aqui, podemos seguir as etapas clássicas de um projeto de data science: Preparação de dados, treinamento do modelo, avaliação e otimização e, implantação.
Preparação dos dados
A preparação dos dados geralmente envolve:
- Preencher os valores ausentes, se exigido pelo próximo algoritmo de machine learning;
- Seleção das características para melhor desempenho final;
- Transformações de dados adicionais para cumprir com os regulamentos mais recentes sobre privacidade de dados.
No entanto, nesse caso, o conjunto de dados que escolhemos já foi limpo e está pronto para uso, nenhuma preparação de dados adicional será necessária.
Todos os algoritmos de classificação supervisionada precisam de um conjunto de treinamento para treinar o modelo e um conjunto de testes para avaliar a qualidade. Após a leitura, os dados devem ser particionados em dois conjuntos, de treinamento e de teste. As proporções comuns de particionamento variam entre 80-20% e 60-40%. Para o nosso exemplo, adotamos o particionamento de 70-30%, no qual 70% dos dados originais são colocados no conjunto de treinamento e os 30% restantes são reservados como conjunto de testes para a avaliação final do modelo.
Para problemas de classificação como o que temos em mãos, precisamos garantir que ambas as classes, no nosso caso as transações fraudulentas e legítimas, estejam presentes nos conjuntos de treinamento e teste. Como uma classe é muito menos frequente que a outra, a amostragem estratificada é recomendada nestes casos, em vez de uma amostragem aleatória. De fato, enquanto a amostragem aleatória pode perder amostras da classe menos numerosa, a amostragem estratificada garante que ambas as classes sejam representadas no subconjunto final de acordo com a distribuição original.
Treinamento do modelo
Qualquer algoritmo de aprendizado de máquina supervisionado pode funcionar. Para fins de demonstração, escolhemos o Random Forest com 100 árvores, todas treinadas até uma profundidade de dez níveis e com um máximo de três amostras por nó, usando a taxa de ganho de informações como uma medida de qualidade para o critério de divisão.
Avaliação do modelo: tomada de decisão informada
Após o modelo ser treinado, devemos avaliá-lo utilizando o conjunto de testes. As métricas de avaliação clássicas podem ser utilizadas, como sensibilidade e especificidade, ou com o Cohen's Kappa. Todas essas medidas se baseiam nas previsões fornecidas pelo modelo. Na maioria das ferramentas de análise de dados, as previsões de modelo são produzidas com base na classe de maior probabilidade, o que em um problema de classificação binária é equivalente a usar um limite padrão de 0,5 em uma das probabilidades da classe.
No entanto, no caso de uma detecção de fraude, podemos ser mais conservadores em relação a transações fraudulentas. Isso significa que preferimos verificar uma transação legítima e arriscar incomodar o cliente com um alerta potencialmente inútil, em vez de perder a transação. Nesse caso, o limiar de aceitação para a classe fraudulenta é reduzido, ou em outras palavras, o limiar de aceitação para a classe legítima é aumentado. Para este estudo de caso, adotamos um limite de decisão de 0,3 sobre a probabilidade da classe fraudulenta e comparamos os resultados com o que obtivemos com o limite padrão de 0,5.
A Figura 1 a seguir apresenta as matrizes de confusão obtidas usando um limite de decisão de 0,5 (à esquerda) e 0,3 (à direita), levando respectivamente ao Cohen's Kappa de 0,890 e 0,898 em um conjunto de dados menor de amostras e com o mesmo número de transações legítimas e fraudulentas. Como pode ver pelas matrizes, privilegiar a decisão em relação a transações fraudulentas produz transações legítimas adicionais, confundidas com a fraude, como um preço a pagar por transações fraudulentas corretamente identificadas.

Figura 1. A figura mostra a medida de desempenho da Random Forest usando dois limites diferentes: 0,5 à esquerda e 0,3 à direita. Na matriz de confusão, a classe 0 refere-se às transações legítimas e a classe 1 às transações fraudulentas. As matrizes mostram mais seis transações fraudulentas classificadas corretamente usando um limite mais baixo de 0,3.
Otimização de hiperparâmetros
Para concluir o ciclo de treinamento, os parâmetros do modelo podem ser otimizados como em todas as soluções de classificação. Omitimos essa parte do estudo de caso, mas poderia ser facilmente incluída sem maiores problemas. Para uma Random Forest, isso significa encontrar o número ideal de árvores e as profundidades para o melhor desempenho de classificação (D. Goldmann, "Preso nos nove círculos do inferno? Experimente a otimização de parâmetros e uma xícara de chá", KNIME Blog, 2018; Otimização de hiperparâmetros). Além disso, o limite de previsão também pode ser otimizado.
O fluxo de trabalho que usamos para o treinamento é, portanto bem simples, com apenas alguns nós (Figura 2): Leitura, particionamento, treinamento de Random Forest, geração de previsão da Random Forest, aplicação de limiar e pontuação de desempenho. O fluxo de trabalho "Detecção de fraude: treinamento de modelos" está disponível gratuitamente e pode ser baixado no KNIME Hub. Para executar o exemplo, basta baixar e instalar a ferramenta open source KNIME Analytics Platform.

Figura 2. Este fluxo de trabalho lê o conjunto de dados e o particiona em dois conjuntos, sendo um usado no treinamento e o outro no teste. Em seguida, usa o conjunto de treinamento para treinar uma Random Forest, aplica o modelo treinado ao conjunto de testes e avalia o desempenho do modelo para os limites de 0,3 e 0,5.
Implantação
Finalmente, quando o desempenho do modelo é aceitável pelos os padrões impostos, podemos usá-lo na produção com dados do mundo real.
O fluxo de trabalho de implantação (Figura 3) importa o modelo treinado, lê uma nova transação por vez e aplica o modelo à transação de entrada e o limite personalizado à previsão final. Caso uma transação seja classificada como fraudulenta, um e-mail é enviado ao dono do cartão de crédito para confirmar a legitimidade da transação.

Figura 3. O fluxo de trabalho de implantação lê o modelo treinado a cada nova transação. Em seguida, aplica o modelo aos dados de entrada, o limite definido às probabilidades de previsão e envia um email ao proprietário do cartão de crédito, caso uma transação tenha sido classificada como fraudulenta.
Cenário 2: Detecção de Anomalias usando o Autoencoder
Vamos agora para o cenário 2. As transações fraudulentas no conjunto de dados eram tão poucas que poderiam ser reservadas para testes e completamente omitidas na fase de treinamento.
Uma das abordagens que foi proposta decorre de técnicas de detecção de anomalias. Técnicas de detecção de anomalias são frequentemente usadas para detectar qualquer evento excepcional ou inesperado nos dados, seja uma falha mecânica do IoT, um batimento cardíaco arrítmico em um sinal de ECG, ou uma transação fraudulenta em um negócio de cartões de crédito. A parte complexa da detecção de anomalias é a ausência de exemplos de treinamento para a classe anômala.
Uma técnica de detecção de anomalias usada com frequência é o autoencoder neural: uma arquitetura neural que pode ser treinada em apenas uma classe de eventos e usada em uma implantação para nos alertar contra novos eventos inesperados. Vamos descrever um exemplo da implementação das técnicas de detecção de anomalias.
A arquitetura neural do autoencoder
Conforme mostrado na Figura 4, o autoencoder é uma rede neural treinada com retro-propagação de feed-forward com tantas n unidades de entrada quanto n unidades de saída. No meio, possui uma ou mais camadas ocultas com uma camada de gargalo central com h unidades, onde h < n. A idéia aqui é treinar a rede neural para reproduzir o vetor de entrada x para o vetor de saída x'.
O autoencoder é treinado usando apenas exemplos de uma das duas classes, nesse caso, a classe de transações legítimas. Durante a implantação, o autoencoder executará um trabalho razoável na reprodução da entrada x na camada de saída x' quando apresentado com uma transação legítima e um trabalho abaixo do ideal quando apresentado com uma transação fraudulenta (por exemplo uma anomalia). Essa diferença entre x e x' pode ser quantificada por meio de uma medida de distância, por exemplo, utilizando a seguinte equação:

A decisão final sobre uma transação legítima versus uma transação fraudulenta é tomada usando um valor limite δ na distância d(x, x'). Uma transação x é uma candidata a fraude de acordo com a seguinte regra de detecção de anomalias:


Figura 4. Esta figura mostra uma possível estrutura de rede para um autoencoder. Nesse caso, temos cinco unidades de entrada e três camadas ocultas com três, duas e três unidades, respectivamente. A saída reconstruída x' tem novamente cinco unidades como entrada. A distância entre a entrada x, e a saída x' pode ser usada para detectar anomalias, como transações fraudulentas.
O valor limite δ pode ser definido de forma conservadora para disparar um alarme apenas para os casos mais óbvios de fraude ou pode ser definido de forma menos conservadora para ser mais sensível a algo fora do comum. Vamos ver as diferentes fases envolvidas neste processo.
Preparação dos dados
A primeira etapa nesse caso é isolar um subconjunto de transações legítimas para criar o conjunto de treinamento e então treinar a rede. De todas as transações legítimas no conjunto de dados original, 90% delas foram usadas para treinar e avaliar a rede de autoencoder e os 10% restantes, juntamente com as transações fraudulentas, foram usados para construir o conjunto de testes para a avaliação de toda a estratégia.
As etapas usuais de preparação de dados devem ser aplicadas ao conjunto de treinamento, conforme discutimos anteriormente. No entanto, como também vimos antes, esse conjunto de dados já foi limpo e está pronto para ser utilizado. Não são necessárias etapas adicionais de preparação de dados, o único passo que precisamos dar é o obrigatório da rede neural: a normalização dos vetores de entrada entre [0,1].
Construindo e treinando o autoencoder neural
A rede do autoencoder é definida como uma arquitetura 30-14-7-7-30, usando as funções tanh e ReLU para ativação e o regularizador de atividades L1 = 0,0001, conforme sugerido na postagem do blog "Detecção de fraude de cartão de crédito usando autoencoder no Keras - TensorFlow for Hackers (Parte VII)", de Venelin Valkov. O parâmetro de regularização de atividade L1 é uma restrição de dispersão, o que torna a rede menos propensa a superestimar os dados de treinamento.
A rede é treinada até que os valores de perda final estejam dentro da faixa [0.070, 0.071], de acordo com o erro quadrático médio da função de perda (MSE):

onde N é o tamanho do lote e n é o número de unidades na camada de saída e de entrada.
O número de ciclos de treinamento é definido como 50, o tamanho do lote N também é definido com o mesmo número e Adam, uma versão otimizada do algoritmo de retropropagação, é escolhido como o algoritmo de treinamento. Após este processo, a rede é salva para implantação como um arquivo Keras.
Avaliação do modelo: Tomada de decisão informada
O valor da função de perda, no entanto, não conta toda a história. Apenas nos diz o quão bem a rede é capaz de reproduzir dados de entrada "normais" na camada de saída. Para ter uma visão completa do desempenho dessa abordagem na detecção de transações fraudulentas, precisamos aplicar a regra de detecção de anomalias mencionada anteriormente utilizando os dados de teste, incluindo as poucas fraudes.
Para fazer isso, precisamos definir o limite δ para a regra de alerta de fraude. Um bom ponto de partida para o limite vem do valor final da função de perda no final da fase de aprendizado. Usamos δ = 0.009, mas como mencionado anteriormente, este é um parâmetro que pode ser adaptado dependendo de quão conservador queremos que a rede seja.
A Figura 5 mostra o desempenho da rede e da regra baseada em distância no conjunto de testes feito com 10% das transações legítimas e todas as transações fraudulentas.

Figura 5. Esta imagem fornece uma visão geral do desempenho do modelo autoencoder, incluindo a matriz e o Cohen's Kappa. Novamente, 0 representa a classe de transações legítimas e 1 a classe de transações fraudulentas.
O fluxo de trabalho final, construindo a rede neural do autoencoder, particionando os dados no conjunto de treinamento e teste, normalizando os dados antes de alimentá-los na rede, treinando a rede, aplicando a rede aos dados de teste, calculando a distância d(x, x'), aplicando o limite δ e finalmente pontuando os resultados, é mostrado na Figura 6 e está disponível para download no KNIME Hub no Autoencoder do Keras para treinamento em detecção de fraudes.

Figura 6. Esse fluxo de trabalho lê o conjunto de dados credit card.csv e cria um conjunto de treinamento, usando apenas 90% de todas as transações legítimas, e um conjunto de testes usando os 10% restantes de transações legítimas e todas as transações fraudulentas. A rede do autoencoder é definida na parte superior esquerda do fluxo de trabalho. Após a normalização dos dados, o autoencoder é treinado e o desempenho é avaliado.
Implantação
Agora chegamos à fase de implantação. Na aplicação de implementação, o autoencoder treinado é lido e aplicado aos novos dados de entrada normalizados, a distância entre o vetor de entrada e o vetor de saída é calculada e o limite é aplicado. Se a distância estiver abaixo do limite, a transação recebida será classificada como legítima, caso contrário, será fraudulenta.
Observe que tanto a estratégia de rede como o limite foram implementados em uma aplicação REST, aceitando dados de entrada na requisição REST e produzindo as previsões na resposta REST.
O fluxo de trabalho que realiza esta implementação é mostrado na Figura 7 e pode ser baixado do KNIME Hub no Autoencoder Keras para implantação de detecção de fraude.
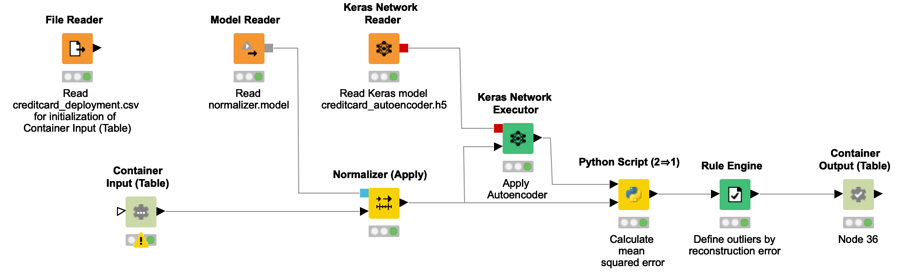
Figura 7. A execução desse fluxo de trabalho pode ser acionada via REST a partir de qualquer aplicação, enviando uma nova transação na estrutura de requisição REST. O fluxo de trabalho lê e aplica o modelo aos dados recebidos e envia de volta a previsão correspondente, 0 para legítimo ou 1 para transação fraudulenta.
Detecção de discrepâncias: Isolation Forest
Outro grupo de estratégias para detecção de fraude, na ausência de exemplos de fraude suficientes, baseia-se em técnicas para detecção externa. Entre todas as diversas técnicas disponíveis de detecção de uma anomalia, propomos a técnica de Isolation Forest (M. Widmann e M. Heine, "Quatro técnicas para detecção de discrepâncias", KNIME Blog, 2019).
A idéia básica do algoritmo Isolation Forest é de que um valor discrepante possa ser isolado com menos divisões aleatórias do que uma amostra pertencente a uma classe regular, pois os valores discrepantes são menos frequentes que as observações regulares e têm valores fora das estatísticas do conjunto de dados.
Seguindo essa ideia, o algoritmo Isolation Forest seleciona aleatoriamente um recurso e seleciona um valor no intervalo desse recurso aleatoriamente como o valor de uma divisão. O uso dessa etapa de particionamento recursivamente gera uma árvore. O número de divisões aleatórias necessárias (o número de isolamento) para encapsular uma amostra é a profundidade da árvore. O número de isolamento (geralmente também chamado de comprimento médio), calculado sobre uma Random Forest, é uma medida de normalidade e a função de decisão para identificar valores extremos.
O particionamento aleatório produz profundidades de árvore notavelmente mais curtas para anomalias e profundidades de árvore mais longas para outras amostras de dados. Portanto, quando uma Random Forest produz coletivamente comprimentos de caminho mais curtos para um ponto de dados específico, muito provavelmente que o dado seja uma anomalia.
Preparação dos dados
Novamente, as etapas de preparação dos dados são as mesmas mencionadas anteriormente: preencher os valores ausentes, seleção de recursos, e transformações adicionais de dados para cumprir com os regulamentos mais recentes sobre privacidade dos dados. Como este conjunto de dados já foi limpo, então está pronto para ser utilizado. Não são necessárias etapas adicionais de preparação. Os conjuntos de treinamento e teste são criados da mesma maneira que o exemplo do autoencoder.
Treinamento e aplicação do Isolation Forest
Assim, um Isolation Forest com 100 árvores e uma profundidade máxima de oito unidades é treinada, e o número médio de isolamento para cada transação entre as árvores é calculado.
Avaliação do modelo: tomando uma decisão não formada
Lembre-se, o número médio de isolamento para os valores discrepantes é menor do que para outros pontos de dados. Adotamos um limiar de decisão δ = 6. Portanto, uma transação é definida como um candidato a fraude se o número médio de isolamento estiver abaixo desse limite. Como nos outros dois exemplos, esse limite é um parâmetro que pode ser otimizado, dependendo da sensibilidade que queremos que o modelo seja.
Os desempenhos dessa abordagem no conjunto de testes são mostrados na Figura 8. O fluxo de trabalho final, disponível no KNIME Hub é mostrado na Figura 9.

Figura 8. Medidas de desempenho para o Isolation Forest no mesmo conjunto de testes da solução de autoencoder, incluindo a matriz e o Cohen's Kappa. Novamente, 0 representa a classe de transações legítimas e 1 a classe de transações fraudulentas.

Figura 9. O fluxo de trabalho lê o conjunto de dados credit card.csv, cria os conjuntos de treinamento e teste e os transforma no Quadro H2O. Em seguida, treina um Isolation Forest e aplica o modelo ao conjunto de testes para encontrar valores discrepantes com base no número de isolamento de cada transação.
Implantação
A realização da implementação lê o modelo do Isolation Forest e aplica aos novos dados recebidos. Com base no limite definido durante o treinamento e aplicado ao valor do número de isolamento, o ponto de dados recebido é identificado como uma transação candidata à fraude ou uma transação legítima.
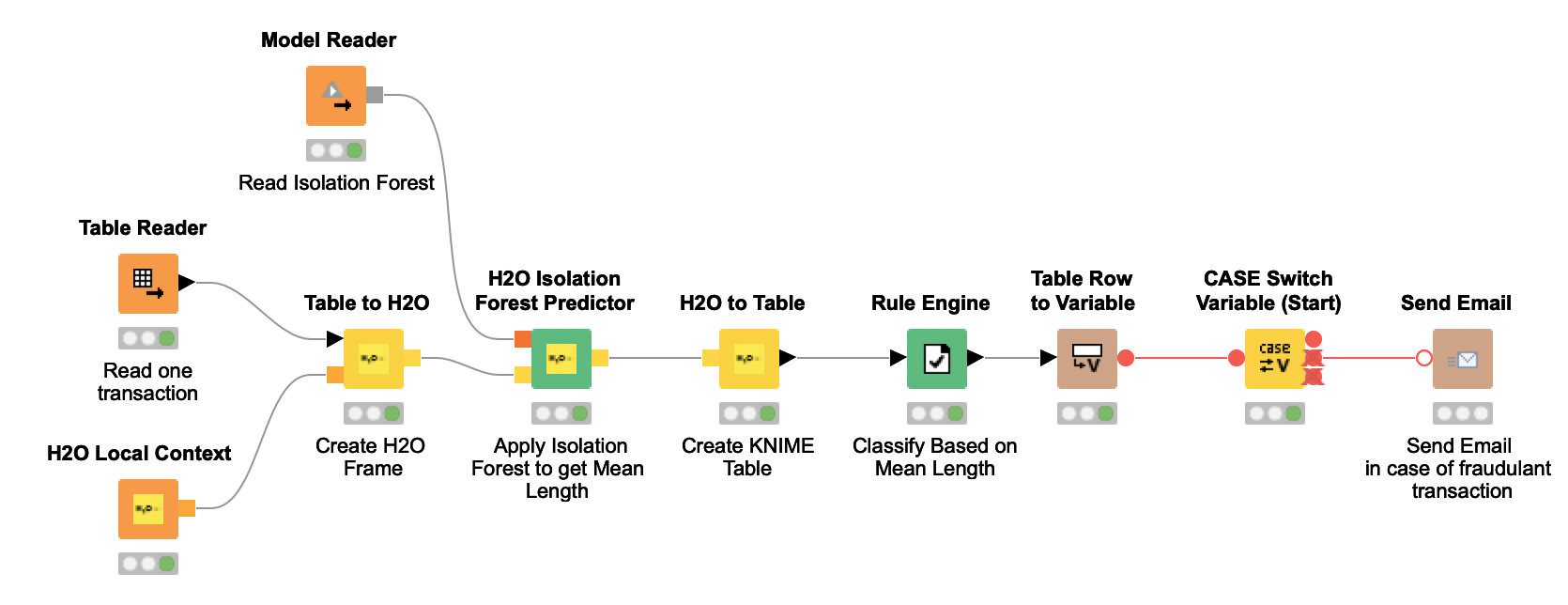
Figura 10. O fluxo de trabalho de implantação lê uma nova transação e aplica o Isolation Forest treinado na nova transação. O número do isolamento é calculado para cada transação de entrada e decide se uma transação é ou não fraudulenta. No caso de transações fraudulentas, o fluxo de trabalho envia um email ao proprietário do cartão de crédito.
Resumo
Conforme descrito no início deste artigo, a detecção de fraudes é uma ampla área de investigação no campo do data science. Retratamos dois cenários possíveis, dependendo do conjunto de dados disponível: um conjunto de dados com pontos de dados para ambas as classes de transações legítimas e fraudulentas e um conjunto de dados sem exemplos ou apenas um número desprezível de exemplos para a classe de fraude.
Para o primeiro cenário, sugerimos uma abordagem clássica baseada em um algoritmo de machine learning supervisionado, seguindo todas as etapas comuns em um projeto de data science, conforme descrito no processo CRISP-DM. Esta é a maneira recomendada de prosseguir. Neste estudo de caso, implementamos um exemplo baseado em um classificador de Random Forest.
Às vezes, devido à natureza do problema, nenhum exemplo para a classe de transações fraudulentas está disponível. Nesses casos, abordagens menos precisas que ainda são possíveis tornam-se atraentes. Para este segundo cenário, descrevemos duas abordagens diferentes: o autoencoder neural para técnicas de detecção de anomalias e o Isolation Forest para técnicas de detecção de discrepâncias. Como em nosso exemplo, muitas vezes os dois não são tão precisos quanto a Random Forest, mas em alguns casos, não temos outra abordagem possível a ser utilizada.
As três abordagens propostas aqui certamente não são as únicas encontradas na literatura. No entanto, acreditamos que são representativos dos três grupos de soluções comumente usados para o problema de detecção de fraude.
Observe que as duas últimas abordagens foram discutidas nos casos em que as transações fraudulentas rotuladas não estão disponíveis. Essas são abordagens de emergência, a serem usadas quando a abordagem comum de classificação não puder ser aplicada por falta de dados rotulados na classe de fraude.
Recomenda-se o uso de um algoritmo de classificação supervisionado sempre que possível. No entanto, quando não há dados de fraude disponíveis, uma das duas últimas abordagens pode ser útil. De fato, embora propensos a produzir falsos positivos, são em alguns casos, as únicas maneiras possíveis de lidar com o problema da detecção de fraudes.
Para mais informações sobre o KNIME, visite www.knime.com e o blog do KNIME.
Sobre as autoras
 Kathrin Melcher é cientista de dados do KNIME. É mestre em matemática pela Universidade de Konstanz, Alemanha. Gosta de ensinar e aplicar seu conhecimento em data science, machine learning e algoritmos. Siga Kathrin no LinkedIn
Kathrin Melcher é cientista de dados do KNIME. É mestre em matemática pela Universidade de Konstanz, Alemanha. Gosta de ensinar e aplicar seu conhecimento em data science, machine learning e algoritmos. Siga Kathrin no LinkedIn
 Rosaria Silipo, Ph.D. e principal cientista de dados do KNIME. É autora de mais de 50 publicações técnicas, incluindo o seu livro mais recente "Praticando ciência de dados: uma coleção de estudos de caso". Possui doutorado em bioengenharia e passou mais de 25 anos trabalhando em projetos de data science para empresas em uma ampla gama de áreas, incluindo IoT, inteligência de clientes, setor financeiro e segurança cibernética. Siga Rosaria no Twitter e LinkedIn.
Rosaria Silipo, Ph.D. e principal cientista de dados do KNIME. É autora de mais de 50 publicações técnicas, incluindo o seu livro mais recente "Praticando ciência de dados: uma coleção de estudos de caso". Possui doutorado em bioengenharia e passou mais de 25 anos trabalhando em projetos de data science para empresas em uma ampla gama de áreas, incluindo IoT, inteligência de clientes, setor financeiro e segurança cibernética. Siga Rosaria no Twitter e LinkedIn.