Pontos Principais
- Crie um mapa mental da interação entre o usuário e um bot.
- Crie um workflow e torne-o conversacional e personalizado.
- O entendimento da linguagem natural (NLU) permite que os usuários conversem naturalmente.
- Os usuários podem se revezar para transmitir uma mensagem ou executar uma tarefa.
- Crie e projete um bot uma única vez, e implante-o em muitas plataformas.
O uso de alto-falantes inteligentes e dispositivos de conversação tem aumentado nos últimos dois anos. Agora, mais de 66 milhões de adultos nos Estados Unidos têm um alto-falante inteligente - ou seja, quase um quarto do país está conversando com dispositivos. Apesar desta ampla inclusão, estamos apenas começando a aproveitar todo o potencial desses dispositivos.
Na Passage AI, construimos uma plataforma que permitiu às empresas criarem aplicativos e habilidades de conversação inteligentes.
Este post é um pincelamento e uma introdução sobre o que acontece nos bastidores da tecnologia de IA para conversação.
O desenvolvimento de uma habilidade de nível empresarial para um dispositivo de conversação envolve três componentes:
- Fluxo de interação. O fluxo de interação envolve a definição e construção da interação que os usuários terão para atingir um objetivo, solucionar problemas ou responder a uma pergunta.
- Entendimento da linguagem natural (NLU). Isso faz o bot entender e responder em linguagem natural e inclui coisas como classificação de intenção, preenchimento de espaços, pesquisa semântica, resposta às perguntas, compreensão de sentimentos e geração de respostas.
- Implantação. Após definir, criar e adicionar NLU à interface, agora precisamos implantá-lo em vários canais. Isso inclui interfaces de voz como Google Home, Microsoft Cortana e Amazon Echo, canais de mensagens como Facebook Messenger, Android Business Messaging e Slack e até mesmo um cliente de bate-papo pop-up que pode ser integrado a algum site.
Fluxo de Interação
Um fluxo de interação é um mapa mental da interação entre o usuário e um bot (interface de conversação). Para criar um fluxo de interação, considera-se útil projetar o fluxo de interação antes de construí-lo. Isso nos força a pensar além do caminho feliz - o fluxo que queremos que o usuário tome. Segue um exemplo de fluxo de interação em que projetamos não apenas o caminho feliz, mas também fluxos mais complicados.
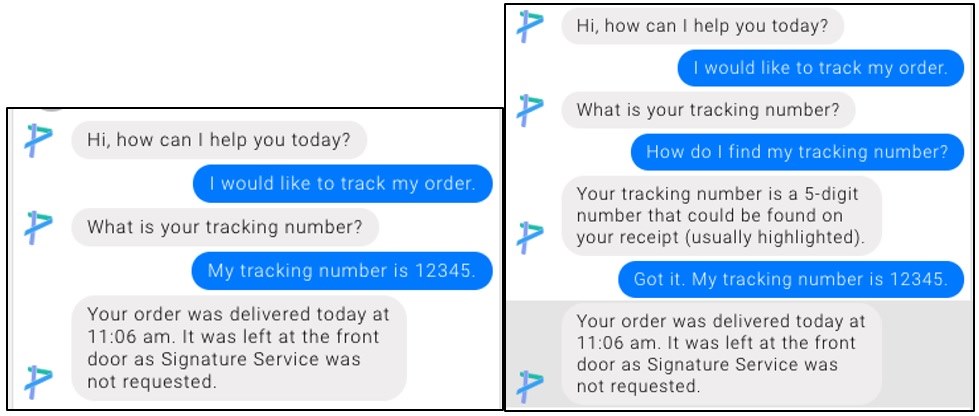
Figura 1: Fluxo de interação do caminho feliz à esquerda e um fluxo mais complicado à direita.
Aqui estão as três principais lições que aprendemos ao projetar fluxos de conversação.
Torne a conversação agradável. Um robô de conversação inteligente não deve parecer um robô. Ao invés de dizer as mesmas mensagens, o bot pode ser configurado para escolher algumas respostas aleatoriamente em uma lista. Outra maneira é dar personalidade à sua interface de conversação. As pessoas estão jogando conversa fora ou conversando com essa interface e, por exemplo, para começar, em vez de apenas dizer "Olá. Como posso ajudá-lo?", Torne-a mais agradável e diga algo como "Olá Tom. Espero que você esteja tendo um ótimo final de semana. O que posso fazer por você hoje? "

Figura 2: Torne a conversação agradável
Conheça o contexto. A resposta que o bot precisa gerar depende não apenas da mensagem anterior do usuário, mas também do contexto. O contexto inclui muitas coisas, como as conversas anteriores entre o bot e o usuário, a modalidade da plataforma (baseada em voz ou texto), o conhecimento ou a experiência do usuário em relação ao produto (pela primeira vez [usuário ingênuo] ou repetitivo [super usuário]) e o estágio de todo o fluxo de trabalho em que o usuário se encontra.

Figura 3: Resposta do bot gerada usando o contexto.
Lidar graciosamente em situações de erros. Nenhuma interface de conversação terá conhecimento completo do mundo e, portanto cometerá alguns erros. Aqui estão algumas dicas para minimizar ou eliminá-los:
- Procure uma confirmação sobre o que o usuário disse até um determinado momento.
- Peça esclarecimentos se o bot precisar de mais informações.
- Graciosamente informe ao usuário que o bot não entendeu a mensagem.
Componentes do workflow de uma conversação
Depois de definir a interação, a próxima etapa é criar um fluxo de trabalho de conversação usando abstrações como intenções, variáveis, webhooks para chamar uma API, árvores de decisão para solucionar problemas e base de conhecimento para responder perguntas.
Intenções são componentes básicos de qualquer interface de conversação, que captura o significado das mensagens do usuário. As intenções podem incluir palavras-chave, variáveis e webhooks para executar uma ação. As palavras-chave representam as várias frases que um usuário pode dizer para se referir a uma intenção. As várias palavras-chave de uma intenção, juntamente com mensagens reais do usuário (rotuladas) para os dados de treinamento para classificação de intenção (consulte a seção NLU para obter mais detalhes). No caso do atendimento ao cliente, podemos definir intenções para rastrear pedidos e conversar com o agente de atendimento ao cliente.
Variáveis definem a entrada que precisamos obter do usuário para executar essa intenção. Por exemplo, para rastrear um pedido de compras, precisamos obter o ID do pedido do usuário. Depois de identificar a intenção e obter as variáveis necessárias, precisamos executar uma ação. Nesse caso, podemos fazer um webhook para fazer uma chamada de API para obter o status do pedido.
Árvores de decisão. Muitos dos casos de uso exigem solução de problemas, exigem certas decisões e respondem a como os usuários estão fornecendo suas informações. As árvores de decisão são uma ótima maneira de resolver esse tipo de problema. Ter uma maneira de definir uma árvore de decisão e um fluxo de controle é um elemento essencial para definir um fluxo de trabalho.
Base de conhecimento: muitos dos agentes de conversação, no caso de atendimento ao cliente, estão respondendo às perguntas do usuário. A base de conhecimento é uma maneira de inserir perguntas frequentes (FAQs) e encontrar a resposta certa para a pergunta do usuário.
Processamento de Linguagem Natural (PLN)
Nesta seção, discutiremos sobre vários blocos de construção de IA para conversação, como classificação de intenção, preenchimento de espaços, rastreamento de estado de diálogo, pesquisa semântica e compreensão de leitura de máquina. Antes de nos aprofundarmos nesses blocos de construção, vamos obter um entendimento básico de deep learning e incorporação.
Deep learning. No aprendizado de máquina tradicional, é gasto muito tempo na construção manual de funcionalidades, tais como, essa uma palavra é final ou não, se a palavra pertence a um país ou a um recurso de localização. Um modelo ou uma função aprendida por máquina combina esses recursos para prever uma resposta. Alguns exemplos de técnicas tradicionais de machine learning são a regressão logística e árvores de decisão com aumento de gradiente. Por outro lado, em deep learning, não há necessidade de recursos manuais. A entrada bruta é representada como um vetor e o modelo aprende as várias interações entre os elementos deste vetor para ajustar os pesos e prever a resposta.
O deep learning foi aplicado com êxito para várias tarefas de processamento de linguagem natural (PNL), como classificação de texto, extração de informações, tradução de idiomas, etc. Duas técnicas importantes em aplicações de deep learning para PNL são: Redes Neurais Recorrentes e Incorporadas, como uma LSTM ou Long-Short Term Neural Network (Rede de Memória de Longo e Curto Prazo).
Incorporação. O primeiro passo em qualquer aplicação de deep learning para NLP é a incorporação, que é converter sentenças em vetores. Existem quatro tipos de incorporações:
- incorporação de palavras sem contexto,
- incorporação de palavras com contexto,
- incorporação de frases e
- incorporação de subpalavras.
As técnicas mais populares em incorporação de palavras não contextuais são a GloVe e Word2Vec. O Word2Vec foi a primeira incorporação popular de palavras introduzida pelo Google em 2013. O conceito principal por trás disso é mapear palavras semelhantes a vetores semelhantes em um espaço de alta dimensão, de modo que a semelhança entre os vetores (medida por produto pontual ou similaridade de cosseno) seja alta.
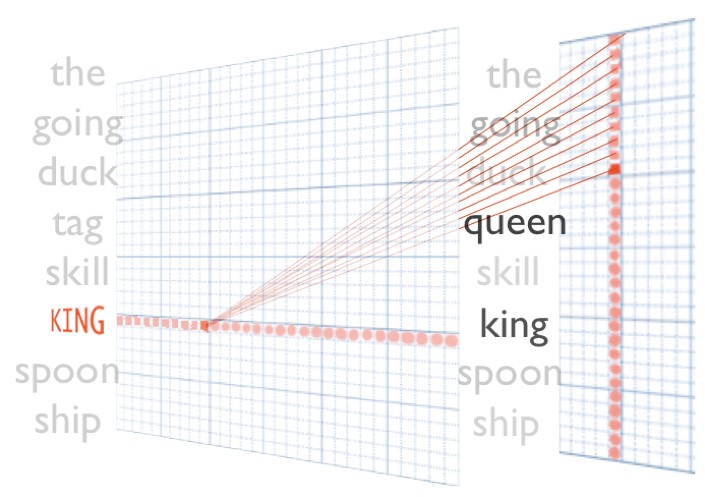
Figura 4: Durante o desenvolvimento do Word2Vec, os pesquisadores do Google observaram um bom efeito colateral disso: é possível aplicar analogias como o vetor de "King" menos o vetor de "Man", mais o vetor de "Woman" está muito próximo da representação vetorial da "Queen".
Em um nível muito alto, para treinar um modelo do Word2Vec, pegamos um coleção muito grande (como a Wikipedia) e o convertemos em uma lista de pares de palavras. Por exemplo, "Eu desejo rastrear meu pedido" pode ser convertido para [(eu, desejo), (desejo, rastrear), (desejo, Eu), (rastrear, desejo), (meu, pedido), (pedido, meu) e assim por diante] usando um tamanho de janela igual a 1. Em seguida, alimentamos uma palavra na rede neural convertendo-a em um vetor. A entrada é então projetada em um espaço de menor dimensão (que forma nossas incorporações) e, em seguida, projetada de volta ao tamanho do vocabulário e usamos um softmax para prever a palavra de destino. Palavras como "rastrear" e "encontrar" têm previsões semelhantes na maioria das vezes e, portanto são projetadas em incorporações semelhantes. Como resultado, a semelhança de cosseno de "rastrear" e "encontrar" seria alta.

Figura 5: Arquitetura de treinamento para Word2Vec - Figura da post do blog de Chris McCormick.
Embora o Word2Vec tenha tido muito sucesso, ele não é contextual, ou seja, a mesma palavra usada em contextos diferentes teria a mesma representação vetorial. Mais recentemente, vetores de palavras contextualizados como ElMo e BERT tornaram-se populares. Ambos vêm de uma família de problemas de PLN conhecidos como modelagem de linguagem, que aprendem a probabilidade de ocorrência de uma palavra com base nas palavras ao seu redor. A palavra "play" em inglês pode significar uma palavra para praticar um esporte, ou também pode significar uma peça teatral, dependendo do contexto. O grande sucesso do BERT pode ser atribuído aos modelos de linguagem bidirecional - enquanto a maioria das incorporações trabalha em uma concatenação superficial de modelos de linguagem unidirecionais (tanto nas direções para frente quanto para trás), o BERT usa um modelo de linguagem bidirecional em que certas palavras de uma frase são mascaradas e o modelo de linguagem tenta predizê-los. Isso permite manter a arquitetura constante ou simples para as tarefas posteriores.
Outra técnica de incorporação introduzida recentemente é a incorporação de frases, onde a frase inteira é incorporada em um vetor. A incorporação de palavras é muito poderosa, mas às vezes é difícil obter uma representação vetorial de uma frase de várias palavras na frase. Técnicas simples, como média, máxima ou soma de vetores de palavras, são uma aproximação, mas não funcionam bem na prática. Uma técnica popular aqui é conhecida como vetores para ignorar pensamentos, que pega a técnica word2vec e a aplica a sentenças. Incorpora-se então frases semelhantes a vetores semelhantes em um espaço de alta dimensão.
Long-Short Term Memory Network (LSTM). A segunda técnica importante em aplicações de deep learning para PLN é a Rede Neural Recorrente (RNN - Recurrent Neural Network). A Long-Short Term Memory Network (LSTM) é uma variante do RNN que foi aplicada com êxito a várias tarefas supervisionadas de PLN, como classificação de texto. Os LSTM são um tipo especial de Rede Neural Recorrente, capaz de aprender através de dependências de longo prazo entre as palavras e evitar problemas como o gradiente de fuga. Conseguem esta façanha usando um mecanismo conhecido como gating - uma maneira de deixar as informações passarem opcionalmente. Os LSTMs têm 3 portões (gates) - o portão de entrada (input gate), o portão de saída (output gate) e o portão do esquecimento (forget gate).
O portão de esquecimento decide o quanto de informação deve fluir do estado anterior da célula. O portão de entrada decide o quanto de informação deve fluir da entrada atual e do estado oculto anterior e o portão de saída decide o quanto de informação deve fluir para o estado oculto atual.

Figura 6: Diagrama de células LSTM
Dada uma frase, o objetivo da classificação do texto é descobrir se ela pertence a alguma das classes desejadas. Uma abordagem padrão para resolver a classificação de texto é obter uma representação de sentença do texto (vetor de tamanho fixo) e usar essas informações para escolher a classe. Embora existam muitas maneiras de obter o vetor de tamanho fixo de uma frase, uma abordagem padrão é alimentar a incorporação de palavras da mensagem em um LSTM bidirecional (Bi-LSTM) e usar a camada final como representação da frase.

Figura 7: Desenrolando uma camada LSTM.
Embora a detecção de intenção seja um problema de classificação de texto, o preenchimento de espaços e a extração de informações pertencem a uma classe de problemas conhecida como rotulagem de sequência. Nessa classe de problemas, cada palavra ou token em uma frase recebe um rótulo e o objetivo é prever o rótulo certo para cada palavra. Como acima, podemos passar uma frase por um Bi-LSTM e prever o rótulo de cada palavra.
Um problema comum no domínio do atendimento ao cliente é criar uma interface de conversação em torno de uma base de conhecimento, como perguntas frequentes (FAQs). Nesse problema, recebe-se vários pares de perguntas e respostas e o objetivo é combinar uma mensagem do usuário com a resposta certa. Uma maneira de abordar esse problema é como um problema tradicional de Recuperação de informações (RI) - a mensagem do usuário atua como 'consulta' e as perguntas frequentes atuam como corpus. Um índice invertido com lista de lançamentos é criado no corpus para recuperação rápida e técnicas de pontuação tradicionais como TF-IDF são usadas para pontuação. Embora isso nos ajude a recuperar a resposta mais relevante, às vezes pode demorar demais para ser consumido por uma interface de conversação.
Em Compreensão de leitura automática ou Resposta de Perguntas, você recebe um pedaço de texto ou contexto e uma consulta, o objetivo é identificar a parte do texto que responde à pergunta. A combinação de LSTM e modelo de atenção é usada para encontrar a resposta no contexto ou parte do texto. Em um alto nível, você alimenta o contexto ou a passagem de texto através das camadas LSTM através da inclusão de palavras e caracteres, além de também enviar uma consulta ou pergunta, então é calculado uma rede de pares de palavras que relacionam as consultas com o contexto e também os contextos com as consultas, e novamente aplica-se redes LSTM bidirecionais para obter o início e o fim de certa resposta em um pedaço de um texto. Esta é uma área de pesquisa muito ativa e nos últimos dois anos houve muito progresso na compreensão de machine reading (leitura automática de texto por máquinas).
A compreensão de diálogo ou o rastreamento de estado de diálogo é uma área de pesquisa ativa. Muitas vezes, os usuários não fornecem todas as informações necessárias para realizar uma tarefa de uma única vez. O bot precisa conversar com o usuário e direcioná-lo para realizar a determinada tarefa (para rastrear um pedido, por exemplo). O fato de manter o "estado" do diálogo e extrair informações em diferentes conjuntos de mensagens é essencial para a compreensão do diálogo. Isto permite ao usuário ir e voltar, alterar o valor de determinadas variáveis e concluir a tarefa sem maiores problemas.
Implantação
O número de plataformas de conversação tem aumentado - Google Assistant, Amazon Echo, Facebook Messenger, Apple iMessage, Slack, Twilio, Samsung Bixby e até uma URA tradicional. À medida que o número de plataformas cresce, torna-se um pesadelo para um desenvolvedor criar bots individuais para essas várias plataformas. O desafio na construção de um middleware que se integra a todas estas plataformas é entender as diferenças e semelhanças entre suas interfaces, além de também acompanhar suas constantes mudanças.
Duas outras coisas a serem lembradas no âmbito da "implantação" são a versão e o teste de bot. As plataformas de desenvolvimento de aplicativos como a Apple Store e o Google Play Store mantêm versões diferentes do aplicativo. Da mesma forma, uma plataforma de desenvolvimento de bot precisa manter diferentes versões do bot. O controle de versão permite reverter facilmente suas alterações e também ter um histórico das alterações implementadas. O teste de bot não é trivial, pois a resposta do bot não depende apenas da mensagem do usuário, mas também do contexto. Além do teste de ponta a ponta, também é possível testar os subcomponentes como um NLU individualmente para facilitar a depuração e a iteração mais rápida.
Conclusão
Este artigo fornece uma visão geral dos blocos de construção de uma interface de conversação inteligente. A IA de conversação é uma área emergente e algumas práticas recomendadas seguem evoluindo. Prevemos um futuro em que alguém possa conversar com todos os dispositivos, instruir um carro a controlar várias funções, um agente virtual planejar e reservar uma próxima viagem e, quando ligar para o serviço de atendimento ao cliente de um provedor de serviços de Internet, um assistente virtual responda imediatamente e com precisão às suas perguntas.
Referências
- Word2Vec Explicado
- O BERT ilustrado
- Compreendendo os LSTM
- Relatório do Gartner sobre boas práticas para estratégia de interface de conversação
Sobre os Autores
 Kaushik Rangadurai é um dos primeiros engenheiros da Passage AI trabalhando principalmente no diálogo e entendimento de linguagem natural. Tem mais de 8 anos de experiência na criação de produtos orientados por IA em empresas como LinkedIn e Google. Antes disso, obteve seu mestrado em Ciência da Computação no Instituto de Tecnologia da Geórgia em Atlanta, especializando-se em aprendizado de máquina.
Kaushik Rangadurai é um dos primeiros engenheiros da Passage AI trabalhando principalmente no diálogo e entendimento de linguagem natural. Tem mais de 8 anos de experiência na criação de produtos orientados por IA em empresas como LinkedIn e Google. Antes disso, obteve seu mestrado em Ciência da Computação no Instituto de Tecnologia da Geórgia em Atlanta, especializando-se em aprendizado de máquina.
 Mitul Tiwari é CTO e Co-fundador da empresa Passage AI. Sua experiência reside na criação de produtos orientados a dados usando IA, machine learning e tecnologias de big data. Anteriormente foi chefe de criação de funcionalidades do LinkedIn como as Pessoas que Você Talvez Conheça (People you may know) e a Relevância no Crescimento (Growth Relevance), onde liderou inovações técnicas em sistemas de recomendação social em larga escala. Antes disso, ele trabalhou no Kosmix (agora Walmart Labs) em documentos Web-scale e categorização de consultas. Obteve seu PhD em Ciência da Computação pela Universidade do Texas em Austin e sua graduação no Indian Institute of Technology at Bombay. Também é co-autor de mais de vinte publicações nas principais conferências como KDD, WWW, RecSys, VLDB, SIGIR, CIKM e SPAA.
Mitul Tiwari é CTO e Co-fundador da empresa Passage AI. Sua experiência reside na criação de produtos orientados a dados usando IA, machine learning e tecnologias de big data. Anteriormente foi chefe de criação de funcionalidades do LinkedIn como as Pessoas que Você Talvez Conheça (People you may know) e a Relevância no Crescimento (Growth Relevance), onde liderou inovações técnicas em sistemas de recomendação social em larga escala. Antes disso, ele trabalhou no Kosmix (agora Walmart Labs) em documentos Web-scale e categorização de consultas. Obteve seu PhD em Ciência da Computação pela Universidade do Texas em Austin e sua graduação no Indian Institute of Technology at Bombay. Também é co-autor de mais de vinte publicações nas principais conferências como KDD, WWW, RecSys, VLDB, SIGIR, CIKM e SPAA.