O Jakarta EE continua onde o Java EE 8 parou, mantendo o foco em aplicações empresariais modernas que trazem novos desafios como microservices, modularidade e bancos de dados NoSQL. Este post abordará a versão mais recente da especificação e as ações que deverão ser tomadas para tornar a comunidade do Jakarta EE na nuvem, ainda maior.
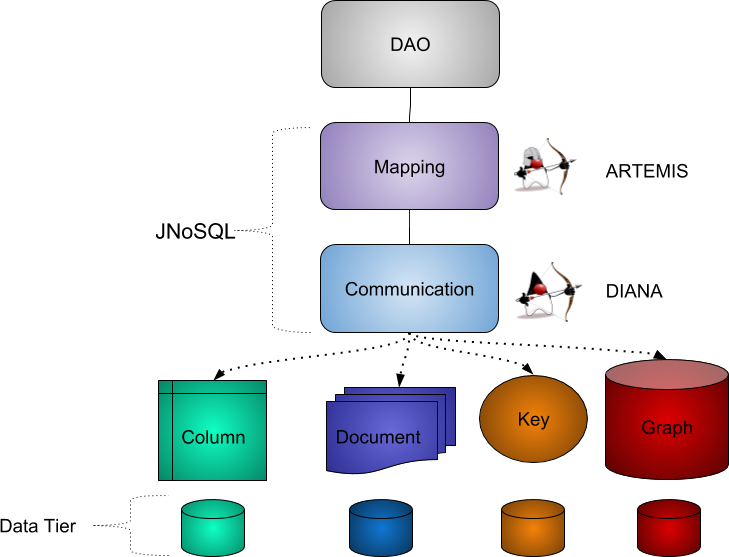
O que é o Jakarta NoSQL?
O foco nos clientes internos é uma das coisas que qualquer desenvolvedor Java precisa considerar ao escolher bancos de dados do tipo NoSQL. Se houver necessidade de uma troca, por qualquer fator, deve-se levar em consideração o tempo gasto para esta mudança, a curva de aprendizado de uma nova API a ser utilizada com esse banco de dados, o código que será perdido, a camada de persistência que precisa ser substituída, etc. O Jakarta NoSQL evita a maioria desses problemas por meio das APIs de comunicação. A ferramenta também possui modelos de classes que aplicam o 'método do modelo' às operações do banco de dados. E a interface Repository permite que os desenvolvedores Java criem e estendam interfaces, com a implementação fornecida automaticamente pelo Jakarta NoSQL, as consultas de método de suporte criadas pelos desenvolvedores serão automaticamente implementadas.
Para deixar claro, vamos criar um exemplo. A imagem abaixo mostra quatro bancos de dados diferentes:
- ArangoDB;
- MongoDB;
- Couchbase;
- OrientDB.
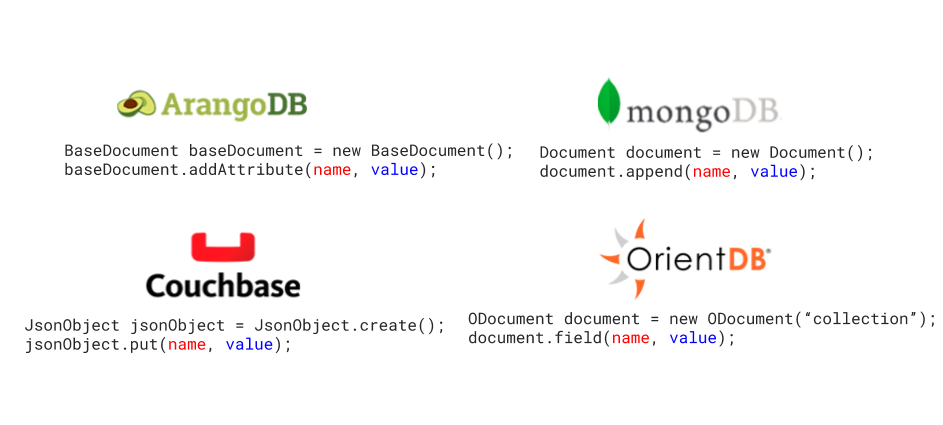
O que esses bancos de dados têm em comum?
odos são bancos de dados de documentos NoSQL e estão tentando criar um documento, uma tupla com um nome e algumas informações. Apesar de todos estarem fazendo a mesma coisa, cada um tem o seu modo de criar, por exemplo, a própria classe, nome de método e assim por diante, são diferentes. Portanto, se desejarmos mover nosso código de banco de dados para outro modelo, precisaremos aprender uma nova API e atualizar todo o código do banco de dados para o destino do novo código da API do banco de dados.
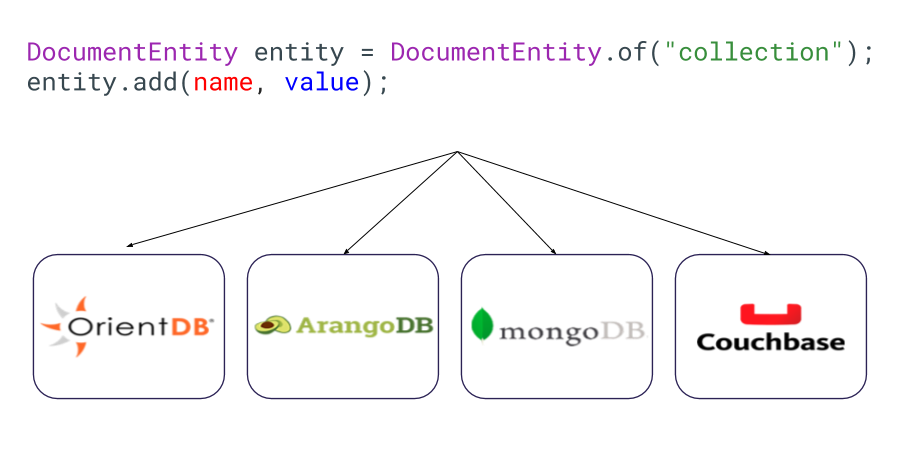
Por meio da especificação de comunicação, podemos mudar facilmente usando esses bancos de dados, apenas utilizando os drivers que se parecem muito com o JDBC. Assim, podemos ficar mais confortáveis aprendendo um novo banco de dados NoSQL pela perspectiva da arquitetura de software, assim podemos pular para outro NoSQL de maneira mais fácil e rápida.
Me mostre o código a API
Para demonstrar como o Jakarta NoSQL funciona, precisamos criar uma pequena API REST, que será executada na nuvem usando o Platform.sh. A API irá manipular os heroes (vamos utilizar o conceito de heróis nos nomes das classes neste exemplo) e todas as informações serão armazenadas no MongoDB. Como primeiro passo, precisamos definir as dependências necessárias do Jakarta NoSQL:
- Jakarta Context Dependency Injection 2.0;
- Jakarta JSON Binding;
- Jakarta Bean Validation 2.0 (opcional);
- Eclipse MicroProfile Configuration (opcional).
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.soujava</groupId>
<artifactId>heroes</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>war</packaging>
<name>heroes-demo</name>
<url>https://soujava.org.br/</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<failOnMissingWebXml>false</failOnMissingWebXml>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<version.microprofile>2.2</version.microprofile>
<version.payara.micro>5.193.1</version.payara.micro>
<payara.version>1.0.5</payara.version>
<platform.sh.version>2.2.3</platform.sh.version>
<jakarta.nosql.version>1.0.0-b1</jakarta.nosql.version>
</properties>
<dependencies>
<dependency>
<groupId>jakarta.platform</groupId>
<artifactId>jakarta.jakartaee-web-api</artifactId>
<version>8.0.0</version>
</dependency>
<dependency>
<groupId>org.eclipse.microprofile.config</groupId>
<artifactId>microprofile-config-api</artifactId>
<version>1.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.eclipse.jnosql.artemis</groupId>
<artifactId>artemis-document</artifactId>
<version>${jakarta.nosql.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jnosql.diana</groupId>
<artifactId>mongodb-driver</artifactId>
<version>${jakarta.nosql.version}</version>
</dependency>
</dependencies>
<build>
<finalName>heroes</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-war-plugin</artifactId>
<version>3.2.2</version>
<configuration>
<failOnMissingWebXml>false</failOnMissingWebXml>
<packagingExcludes>pom.xml</packagingExcludes>
</configuration>
</plugin>
<plugin>
<groupId>fish.payara.maven.plugins</groupId>
<artifactId>payara-micro-maven-plugin</artifactId>
<version>${payara.version}</version>
<configuration>
<payaraVersion>${version.payara.micro}</payaraVersion>
<autoDeployEmptyContextRoot>true</autoDeployEmptyContextRoot>
</configuration>
</plugin>
</plugins>
</build>
</project>
Um aspecto maravilhoso do uso do Platform.sh é que não precisamos nos preocupar com a instalação da infraestrutura que inclui o próprio servidor MongoDB. Ele irá criar vários containers que incluem a aplicação e o banco de dados. Falaremos mais sobre o Platform.sh e o relacionamento com nativo com a nuvem em breve.
O primeiro passo é a criação da entidade Hero é possível perceber que o pacote da especificação é o jakarta.nosql.mapping.
import jakarta.nosql.mapping.Column;
import jakarta.nosql.mapping.Entity;
import jakarta.nosql.mapping.Id;
import javax.json.bind.annotation.JsonbVisibility;
import java.io.Serializable;
import java.util.Objects;
import java.util.Set;
@Entity
@JsonbVisibility(FieldPropertyVisibilityStrategy.class)
public class Hero implements Serializable {
@Id
private String name;
@Column
private Integer age;
@Column
private Set<String> powers;
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (!(o instanceof Hero)) {
return false;
}
Hero hero = (Hero) o;
return Objects.equals(name, hero.name);
}
@Override
public int hashCode() {
return Objects.hashCode(name);
}
@Override
public String toString() {
return "Hero{" +
"name='" + name + '\'' +
", age=" + age +
", powers=" + powers +
'}';
}
}
import javax.json.bind.config.PropertyVisibilityStrategy;
import java.lang.reflect.Field;
import java.lang.reflect.Method;
public class FieldPropertyVisibilityStrategy implements PropertyVisibilityStrategy {
@Override
public boolean isVisible(Field field) {
return true;
}
@Override
public boolean isVisible(Method method) {
return true;
}
}
O próximo passo é criar uma conexão com o banco de dados NoSQL, para tal, vamos criar uma instância do DocumentCollectionManager. Pense no EntityManager como um banco de dados de documentos. Sabemos que as informações codificadas não estão seguras, muito menos são sinônimos de boas práticas. É por isso que os doze fatores menciona isso na terceira seção. Além disso, a aplicação não precisa saber a origem das informações. Para seguir as boas práticas dos doze fatores e apoiar o princípio cloud-native, o Jakarta NoSQL tem suporte para a Configuração do MicroProfile do Eclipse.
import jakarta.nosql.document.DocumentCollectionManager;
import org.eclipse.microprofile.config.inject.ConfigProperty;
import javax.enterprise.context.ApplicationScoped;
import javax.enterprise.inject.Disposes;
import javax.enterprise.inject.Produces;
import javax.inject.Inject;
@ApplicationScoped
class DocumentManagerProducer {
@Inject
@ConfigProperty(name = "document")
private DocumentCollectionManager manager;
@Produces
public DocumentCollectionManager getManager() {
return manager;
}
public void destroy(@Disposes DocumentCollectionManager manager) {
manager.close();
}
}
Feito isso, criamos uma classe de conexão que disponibiliza uma instância do DocumentCollectionManager para o CDI, graças ao método Produces.
A configuração do banco de dados está pronta para ser executada localmente. Para esta aplicação, além do CRUD, vamos criar mais outras consultas:
- Encontre todos os Heroes;
- Encontre Heroes com acima uma certa idade;
- Encontre Heroes com abaixo uma certa idade;
- Encontre Heroes pelo nome, o id;
- Encontre Heroes pelo poder.
Temos diversas maneiras de criar essa consulta no Jakarta NoSQL. Vamos apresentar a primeira delas com o DocumentTemplate. As classes de modelo executam operações no banco de dados NoSQL na camada Mapper, portanto, existe uma classe de modelo para cada tipo de NoSQL que o Jakarta NoSQL suporta: O DocumentTemplate para documento, o KeyValueTemplate para banco de dados de valores-chave e assim por diante.
Mesmo com o Document Template, temos dois caminhos para consultar as informações nos bancos de dados NoSQL. O primeiro é usando programação. A API possui uma maneira fluente de criar uma instância do DocumentQuery.
package jakarta.nosql.demo.hero;
import jakarta.nosql.document.DocumentDeleteQuery;
import jakarta.nosql.document.DocumentQuery;
import jakarta.nosql.mapping.document.DocumentTemplate;
import com.google.common.collect.Sets;
import javax.enterprise.context.ApplicationScoped;
import javax.inject.Inject;
import java.util.Optional;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import static jakarta.nosql.document.DocumentDeleteQuery.delete;
import static jakarta.nosql.document.DocumentQuery.select;
import static java.util.Arrays.asList;
@ApplicationScoped
public class FluentAPIService {
@Inject
private DocumentTemplate template;
public void execute() {
Hero iron = new Hero("Iron man", 32, Sets.newHashSet("Rich"));
Hero thor = new Hero("Thor", 5000, Sets.newHashSet("Force", "Thunder", "Strength"));
Hero captainAmerica = new Hero("Captain America", 80, Sets.newHashSet("agility",
"Strength", "speed", "endurance"));
Hero spider = new Hero("Spider", 18, Sets.newHashSet("Spider", "Strength"));
DocumentDeleteQuery deleteQuery = delete().from("Hero")
.where("_id").in(Stream.of(iron, thor, captainAmerica, spider)
.map(Hero::getName).collect(Collectors.toList())).build();
template.delete(deleteQuery);
template.insert(asList(iron, thor, captainAmerica, spider));
//Encontre pelo Id
Optional<Hero> hero = template.find(Hero.class, iron.getName());
System.out.println(hero);
//Encontre os mais novos
DocumentQuery youngQuery = select().from("Hero")
.where("age").lt(20).build();
//Encontre os mais velhos
DocumentQuery seniorQuery = select().from("Hero")
.where("age").gt(20).build();
//Encontre pelo poder
DocumentQuery queryPower = select().from("Hero")
.where("powers").in(Collections.singletonList("Strength"))
.build();
Stream<Hero> youngStream = template.select(youngQuery);
Stream<Hero> seniorStream = template.select(seniorQuery);
Stream<Hero> strengthStream = template.select(queryPower);
String yongHeroes = youngStream.map(Hero::getName).collect(Collectors.joining(","));
String seniorsHeroes = seniorStream.map(Hero::getName).collect(Collectors.joining(","));
String strengthHeroes = strengthStream.map(Hero::getName).collect(Collectors.joining(","));
System.out.println("Young result: " + yongHeroes);
System.out.println("Seniors result: " + seniorsHeroes);
System.out.println("Strength result: " + strengthHeroes);
}
}
Quando falamos sobre a consulta "encontre todos os Heroes", criaremos uma classe específica porque, quando falamos em retornar todas as informações em um banco de dados, precisamos evitar os problemas de desempenho. Partindo do princípio que o banco de dados pode ter mais de um milhão de pontos de informações, não faz sentido trazer tudo ao mesmo tempo, ao menos não nos casos mais comuns.
import jakarta.nosql.document.DocumentDeleteQuery;
import jakarta.nosql.document.DocumentQuery;
import jakarta.nosql.mapping.document.DocumentTemplate;
import com.google.common.collect.Sets;
import javax.enterprise.context.ApplicationScoped;
import javax.inject.Inject;
import java.util.Arrays;
import java.util.Optional;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import static jakarta.nosql.document.DocumentDeleteQuery.delete;
import static jakarta.nosql.document.DocumentQuery.select;
import static java.util.Arrays.asList;
@ApplicationScoped
public class FluentAPIFindAllService {
@Inject
private DocumentTemplate template;
public void execute() {
Hero iron = new Hero("Iron man", 32, Sets.newHashSet("Rich"));
Hero thor = new Hero("Thor", 5000, Sets.newHashSet("Force", "Thunder"));
Hero captainAmerica = new Hero("Captain America", 80, Sets.newHashSet("agility",
"strength", "speed", "endurance"));
Hero spider = new Hero("Spider", 18, Sets.newHashSet("Spider"));
DocumentDeleteQuery deleteQuery = delete().from("Hero")
.where("_id").in(Stream.of(iron, thor, captainAmerica, spider)
.map(Hero::getName).collect(Collectors.toList())).build();
template.delete(deleteQuery);
template.insert(Arrays.asList(iron, thor, captainAmerica, spider));
DocumentQuery query = select()
.from("Hero")
.build();
Stream<Hero> heroes = template.select(query);
Stream<Hero> peek = heroes.peek(System.out::println);
System.out.println("The peek is not happen yet");
System.out.println("The Heroes names: " + peek.map(Hero::getName)
.collect(Collectors.joining(", ")));
DocumentQuery querySkipLimit = select()
.from("Hero")
.skip(0)
.limit(1)
.build();
Stream<Hero> heroesSkip = template.select(querySkipLimit);
System.out.println("The Heroes names: " + heroesSkip.map(Hero::getName)
.collect(Collectors.joining(", ")));
}
}
Além disso, a API possui um recurso de paginação que pode ser utilizado para tal fim e funciona com grandes conjuntos de dados.
import jakarta.nosql.document.DocumentDeleteQuery;
import jakarta.nosql.document.DocumentQuery;
import jakarta.nosql.mapping.Page;
import jakarta.nosql.mapping.Pagination;
import jakarta.nosql.mapping.document.DocumentQueryPagination;
import jakarta.nosql.mapping.document.DocumentTemplate;
import com.google.common.collect.Sets;
import javax.enterprise.context.ApplicationScoped;
import javax.inject.Inject;
import java.util.Arrays;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import static jakarta.nosql.document.DocumentDeleteQuery.delete;
import static jakarta.nosql.document.DocumentQuery.select;
@ApplicationScoped
public class FluentAPIPaginationService {
@Inject
private DocumentTemplate template;
public void execute() {
Hero iron = new Hero("Iron man", 32, Sets.newHashSet("Rich"));
Hero thor = new Hero("Thor", 5000, Sets.newHashSet("Force", "Thunder"));
Hero captainAmerica = new Hero("Captain America", 80, Sets.newHashSet("agility",
"strength", "speed", "endurance"));
Hero spider = new Hero("Spider", 18, Sets.newHashSet("Spider"));
DocumentDeleteQuery deleteQuery = delete().from("Hero")
.where("_id").in(Stream.of(iron, thor, captainAmerica, spider)
.map(Hero::getName).collect(Collectors.toList())).build();
template.delete(deleteQuery);
template.insert(Arrays.asList(iron, thor, captainAmerica, spider));
DocumentQuery query = select()
.from("Hero")
.orderBy("_id")
.asc()
.build();
DocumentQueryPagination pagination =
DocumentQueryPagination.of(query, Pagination.page(1).size(1));
Page<Hero> page1 = template.select(pagination);
System.out.println("Page 1: " + page1.getContent().collect(Collectors.toList()));
Page<Hero> page2 = page1.next();
System.out.println("Page 2: " + page2.getContent().collect(Collectors.toList()));
Page<Hero> page3 = page1.next();
System.out.println("Page 3: " + page3.getContent().collect(Collectors.toList()));
}
}
Uma API fluente é muito boa e segura para escrever e ler consultas para um banco de dados NoSQL, mas e quanto à consulta por texto? Embora uma API fluente seja mais segura, às vezes é extensa e exagerada. Sabe de uma coisa? O Jakarta NoSQL tem suporte para consultas por texto que inclui PrepareStatement onde, o desenvolvedor Java, pode definir o parâmetro dinamicamente.
import jakarta.nosql.mapping.PreparedStatement;
import jakarta.nosql.mapping.document.DocumentTemplate;
import com.google.common.collect.Sets;
import javax.enterprise.context.ApplicationScoped;
import javax.inject.Inject;
import java.util.Arrays;
import java.util.stream.Collectors;
import java.util.stream.Stream;
@ApplicationScoped
public class TextService {
@Inject
private DocumentTemplate template;
public void execute() {
Hero iron = new Hero("Iron man", 32, Sets.newHashSet("Rich"));
Hero thor = new Hero("Thor", 5000, Sets.newHashSet("Force", "Thunder"));
Hero captainAmerica = new Hero("Captain America", 80, Sets.newHashSet("agility",
"strength", "speed", "endurance"));
Hero spider = new Hero("Spider", 18, Sets.newHashSet("Spider"));
template.query("delete from Hero where _id in ('Iron man', 'Thor', 'Captain America', 'Spider')");
template.insert(Arrays.asList(iron, thor, captainAmerica, spider));
//Encontre o mais novo
PreparedStatement prepare = template.prepare("select * from Hero where age < @age");
prepare.bind("age", 20);
Stream<Hero> youngStream = prepare.getResult();
Stream<Hero> seniorStream = template.query("select * from Hero where age > 20");
Stream<Hero> powersStream = template.query("select * from Hero where powers in ('Strength')");
Stream<Hero> allStream = template.query("select * from Hero");
Stream<Hero> skipLimitStream = template.query("select * from Hero skip 0 limit 1 order by _id asc");
String yongHeroes = youngStream.map(Hero::getName).collect(Collectors.joining(","));
String seniorsHeroes = seniorStream.map(Hero::getName).collect(Collectors.joining(","));
String allHeroes = allStream.map(Hero::getName).collect(Collectors.joining(","));
String skipLimitHeroes = skipLimitStream.map(Hero::getName).collect(Collectors.joining(","));
String powersHeroes = powersStream.map(Hero::getName).collect(Collectors.joining(","));
System.out.println("Young result: " + yongHeroes);
System.out.println("Seniors result: " + seniorsHeroes);
System.out.println("Powers Strength result: " + powersHeroes);
System.out.println("All heroes result: " + allHeroes);
System.out.println("All heroes skip result: " + skipLimitHeroes);
}
}
O que achou? Muito complexo? Não se preocupe, podemos simplificá-lo com um Repositório. Uma abstração de repositório pode reduzir significativamente a quantidade de código necessário para implementar as camadas de acesso aos dados feitos por várias persistências de armazenamento.
import jakarta.nosql.mapping.Page;
import jakarta.nosql.mapping.Pagination;
import jakarta.nosql.mapping.Repository;
import java.util.stream.Stream;
public interface HeroRepository extends Repository<Hero, String> {
Stream<Hero> findAll();
Page<Hero> findAll(Pagination pagination);
Stream<Hero> findByPowersIn(String powers);
Stream<Hero> findByAgeGreaterThan(Integer age);
Stream<Hero> findByAgeLessThan(Integer age);
}
import jakarta.nosql.mapping.Page;
import jakarta.nosql.mapping.Pagination;
import com.google.common.collect.Sets;
import javax.enterprise.context.ApplicationScoped;
import javax.inject.Inject;
import java.util.Optional;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import static java.util.Arrays.asList;
@ApplicationScoped
public class RepositoryService {
@Inject
private HeroRepository repository;
public void execute() {
Hero iron = new Hero("Iron man", 32, Sets.newHashSet("Rich"));
Hero thor = new Hero("Thor", 5000, Sets.newHashSet("Force", "Thunder", "Strength"));
Hero captainAmerica = new Hero("Captain America", 80, Sets.newHashSet("agility",
"Strength", "speed", "endurance"));
Hero spider = new Hero("Spider", 18, Sets.newHashSet("Spider", "Strength"));
repository.save(asList(iron, thor, captainAmerica, spider));
//Encontre pelo Id
Optional<Hero> hero = repository.findById(iron.getName());
System.out.println(hero);
Stream<Hero> youngStream = repository.findByAgeLessThan(20);
Stream<Hero> seniorStream = repository.findByAgeGreaterThan(20);
Stream<Hero> strengthStream = repository.findByPowersIn("Strength");
Stream<Hero> allStream = repository.findAll();
String yongHeroes = youngStream.map(Hero::getName).collect(Collectors.joining(","));
String seniorsHeroes = seniorStream.map(Hero::getName).collect(Collectors.joining(","));
String strengthHeroes = strengthStream.map(Hero::getName).collect(Collectors.joining(","));
String allHeroes = allStream.map(Hero::getName).collect(Collectors.joining(","));
System.out.println("Young result: " + yongHeroes);
System.out.println("Seniors result: " + seniorsHeroes);
System.out.println("Strength result: " + strengthHeroes);
System.out.println("All heroes result: " + allHeroes);
//Paginação
Pagination pagination = Pagination.page(1).size(1);
Page<Hero> page1 = repository.findAll(pagination);
System.out.println("Page 1: " + page1.getContent().collect(Collectors.toList()));
Page<Hero> page2 = page1.next();
System.out.println("Page 2: " + page2.getContent().collect(Collectors.toList()));
Page<Hero> page3 = page1.next();
System.out.println("Page 3: " + page3.getContent().collect(Collectors.toList()));
}
}
Concluímos a primeira parte, apresentando o conceito por trás do Jakarta e do NoSQL e a API de documento com o MongoDB. Na parte dois, falaremos sobre a parte cloud-native e sobre como podemos alterar facilmente a aplicação para a nuvem usando o Platform.sh. Se está curioso e não se importa de ter um spoiler, pode dar uma olhada no código de exemplo no repositório.
Sobre o autor
 Otávio Santana é engenheiro de software na Platform.sh, com grande experiência em desenvolvimento open source, com diversas contribuições ao JBoss Weld, Hibernate, Apache Commons e outros projetos. Focado em desenvolvimento poliglota e aplicações de alto desempenho, Otávio trabalhou em grandes projetos nas áreas de finanças, governo, mídias sociais e e-commerce. Membro do comitê executivo do JCP e de vários Expert Groups de JSRs, é também Java Champion e recebeu os prêmios JCP Outstanding Award e Duke's Choice Award.
Otávio Santana é engenheiro de software na Platform.sh, com grande experiência em desenvolvimento open source, com diversas contribuições ao JBoss Weld, Hibernate, Apache Commons e outros projetos. Focado em desenvolvimento poliglota e aplicações de alto desempenho, Otávio trabalhou em grandes projetos nas áreas de finanças, governo, mídias sociais e e-commerce. Membro do comitê executivo do JCP e de vários Expert Groups de JSRs, é também Java Champion e recebeu os prêmios JCP Outstanding Award e Duke's Choice Award.