Pontos Principais
- Quando bem feito, Model Driven Software Development pode camuflar parcialmente alguma complexidade, mas será necessário tratar a saída do código fonte como artefatos de build e tornar-se o dono dos modelos. A manutenção dos modelos geradores de código é um tipo de meta-programação que a maioria dos desenvolvedores não estão acostumados a fazer.
- A aplicação dos doze fatores pode realmente alcançar baixa complexidade, mas somente quando integrado com um armazenamento de dados maduro e estável (ou seja, tedioso).
- Você pode diminuir a complexidade na orquestração de microsserviços ao construir com algum limite, uma inteligência cruzada nos conectores, mas é preciso ter cuidado, porque muita inteligência cria o efeito oposto.
- Você pode escrever aplicações menores ao usar um framework pesado, mas precisa ser cuidadoso com o fato de que a eficiência pode ser prejudicada, que esses tipos de serviços são mais difíceis de ajustar para o desempenho e que pode levar mais tempo para depurar certos tipos de problemas.
- Com a programação reativa, acabamos substituindo a complexidade de back-end pela complexidade do frontend.
Uma das coisas mais importantes que os arquitetos de software fazem é gerenciar a complexidade de seus sistemas a fim de mitigar a interrupção de uma entrega enquanto mantém velocidade na criação de funcionalidades. Os sistemas podem ser simplificados, mas apenas por algum tempo. O software moderno deve atender a muitas demandas sofisticadas para ser competitivo. Quando não podemos reduzir a complexidade, tentamos escondê-la ou mudá-la.
Arquitetos de software tendem a gerenciar essa complexidade com as seguintes estratégias consagradas pelo tempo:
- Eles podem diminuir o tamanho das aplicações reutilizando frameworks genéricos ou usando geradores de código programáticos;
- Eles facilitam a escalabilidade de seus sistemas, mantendo abas fechadas em aplicações statefulness;
- Eles projetam sistemas que se degradam de maneira "graciosa" sob carga crescente ou interrupção parcial de energia;
- Finalmente, eles normalizam as cargas de trabalho movendo-se para sistemas eventualmente consistentes.
Vamos entrar em mais detalhes sobre essas diferentes estratégias e o contexto histórico em que cada estratégia foi formada, a fim de entender melhor as vantagens e desvantagens de cada abordagem.
É apenas um modelo
O MDSD, ou desenvolvimento de software orientado por modelo, aumenta a velocidade do recurso, porque os desenvolvedores economizam tempo escrevendo menos código repetitivo. Em vez disso, um modelo é especificado e um gerador combina o modelo com os modelos do código repetitivo para gerar o código que os desenvolvedores costumavam escrever à mão.
Minha primeira exposição ao MDSD foi nos dias de CASE (engenharia de software assistida por computador). Ele ressurgiu quando a UML (linguagem de modelagem unificada) estava no auge. O problema com o MDSD naquela época era que ele estava sendo lançado para gerar todo o código, o que significa que o tipo de modelo necessário para capturar todos os requisitos possíveis era tão complexos que era mais fácil escrever o código.
O MDSD está ressurgindo devido a uma tecnologia chamada Swagger (novas versões da especificação de modelagem agora são criadas pela Iniciativa OpenAPI), onde você especifica um modelo apenas para como suas APIs devem parecer. O modelo e um conjunto de modelos são inseridos em um gerador, que gera o código repetitivo que emerge das APIs. Existem modelos separados para o código que produz e consome a API que está sendo modelada, e os modelos iniciais estão disponíveis on-line para praticamente qualquer pilha de tecnologia relevante.
Por exemplo, examine os modelos Swagger para Spring Boot, que geram os controladores REST, requisições "Jackson annotated" e as respostas POJOs, e vários códigos do aplicativo repetitivos. Cabe aos desenvolvedores adicionar a lógica e os detalhes de implementação (por exemplo, acesso ao banco de dados) necessários para satisfazer os requisitos de cada API. Para evitar que os engenheiros tenham que modificar os arquivos gerados pelo Swagger, e usem a injeção de herança ou de dependência.
Como o MDSD pode obscurecer a complexidade do seu código da aplicação? É complicado, mas pode ser feito. O gerador gera o código que implementa os recursos da API, portanto, os desenvolvedores não precisam se preocupar com a codificação. No entanto, se você usar o gerador como um assistente de código único e confirmar a saída para o repositório de código-fonte controlado por versão (por exemplo, git), tudo o que você fez foi economizar algum tempo de codificação inicial. Você realmente não escondeu nada, já que os desenvolvedores terão que estudar e manter o código gerado.
Para realmente obscurecer a complexidade desse código, você precisa submeter o modelo ao seu repositório de código-fonte controlado por versão, mas não ao código-fonte gerado. Você precisa gerar essa fonte de saída do modelo toda vez que construir o código. Você precisará adicionar essa etapa do gerador a todos os seus pipelines de construção. Os usuários do Maven vão querer configurar o swagger-codegen-maven-plugin em seu arquivo pom. Esse plugin é um módulo do projeto swagger-codegen.
E se você tiver que fazer alterações no código-fonte gerado? É por isso que você terá que assumir a propriedade dos modelos e também submetê-los ao seu repositório de código-fonte controlado por versão. Esses são "mustache template", que se parecem com o código a ser gerado com parâmetros de substituição delimitados por chave de opção e lógica de ramo de decisão neles. A programação de modelos é uma forma de meta-programação bastante avançada.
No final, o melhor que você pode esperar com o MDSD é que ele pode obscurecer a complexidade para os desenvolvedores juniores, mas às custas de ter seus desenvolvedores seniores dando suporte a esses modelos.
| Model-Driven Software Development | |
| Prós | Contras |
|
|
Na origem dos sistemas de computador
Em 2011, o pessoal da Heroku publicou uma coleção de práticas recomendadas para escrever softwares modernos, nativos em nuvem e orientados a serviços. Eles chamaram de "aplicação de doze fatores". Para entender melhor por que esses doze fatores realmente reduzem a complexidade, revisamos brevemente o histórico de como os sistemas de computador evoluíram de simples configurações de uma única máquina a clusters complexos de máquinas virtuais conectadas em uma rede definida por software.
Por um longo tempo, os sistemas foram projetados para serem executados em um único computador. Se você quisesse que um sistema lidasse com mais solicitações, você teria que escalar sua aplicação instalando-o em um computador maior. Os sistemas evoluíram para aplicações de duas camadas, onde centenas de usuários executavam um programa cliente especializado em seus desktops que se conectava a um programa de banco de dados executado em um único servidor.
O próximo passo na evolução da computação foram os sistemas de três camadas, nos quais os programas clientes se conectavam a um servidor de aplicações que acessava o servidor de banco de dados. As aplicações Web substituíram as aplicações cliente-servidor porque era mais fácil implantar a parte do cliente (supondo que todos os computadores tivessem um navegador da Web moderno instalado) e você poderia acomodar mais usuários conectados ao sistema. O aumento de escala (substituir um computador por um computador maior) tornou-se menos atraente do que o dimensionamento (expandindo de um computador para vários computadores). Para lidar com a carga adicional do usuário, esse único servidor de aplicações foi dimensionado para um cluster de computadores em execução atrás de um balanceador de carga. Servidores de banco de dados poderiam ser redimensionados por técnicas conhecidas como fragmentação (para gravações) e replicação (para leituras). Naquela época, todos esses servidores eram implantados nas instalações da empresa que os utilizavam ou em um data center alugado.
Por cerca de trinta anos, a opção mais viável para o software de banco de dados foi bancos de dados relacionais, também conhecidos como bancos de dados SQL, porque o código de uma aplicação se comunica com eles por meio de comandos escritos na linguagem de mesmo nome. Existem muitos bancos de dados relacionais para escolher. MySQL, MariaDB e PostgreSQL são populares bancos de dados de código aberto. Oracle e MS SQL Server são bancos de dados proprietários e também muito populares.
Uma proliferação de outras opções tornou-se disponível na última década. Existe agora uma categoria conhecida como bancos de dados NoSQL, que inclui bancos de dados com grandes colunas, como o Cassandra, bancos de dados chave-valor como o Aerospike, bancos de dados baseados em documentos semelhantes ao MongoDB, bancos de dados gráficos como Neo4j e índices invertidos no estilo Elasticsearch. Ainda mais recentemente, os bancos de dados distribuídos e multimodelos ganharam alguma popularidade. Com bancos de dados de vários modelos, você pode chamar APIs SQL e NoSQL em uma única instalação de banco de dados. Os bancos de dados distribuídos lidam com fragmentação e replicação sem qualquer complexidade adicional no código da aplicação. YugaByte e Cosmos DB são multi-modais e distribuídos.
Com o advento da nuvem, as empresas não precisavam mais empregar engenheiros que saibam como montar e cabear racks de computadores ou assinar contratos de arrendamento de cinco anos com fabricantes de computadores e gerenciar provedores de serviços de hosting. Para realizar essas economias em escala, os computadores foram virtualizados e se tornaram mais efêmeros. O software teve que ser redesenhado para acomodar mais facilmente todas essas mudanças assim como, a forma como eles são implantados em produção.
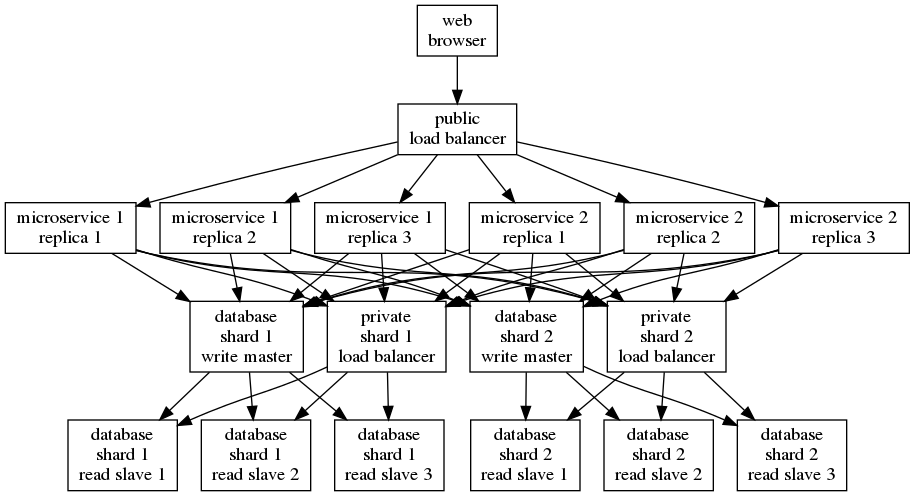
Implantação típica em que dois microsserviços e um banco de dados são redimensionados.
Aplicações que seguem adequadamente esses doze fatores lidam facilmente com essa proliferação de hardware com complexidade mínima. Vamos nos concentrar nos fatores 6 (processos), 8 (concorrência) e 9 (descartabilidade).
Você poderá dimensionar sua aplicação mais facilmente se a aplicação for projetada para ser executada em muitos processos stateless. Caso contrário, tudo o que você pode fazer facilmente é escalar. Isso é o tudo o que o fator 6 representa. Não há problema em armazenar dados em cache em um cluster externo para acelerar a latência média ou para proteger os bancos de dados subjacentes de ficarem sobrecarregados, mas o cache nunca deve conter dados que ainda não estejam no (s) banco (s) de dados. Você pode perder o cache a qualquer momento sem perder nenhum dado real.
O fator 8 é sobre concorrência. Esses processos devem ser agrupados em clusters, de modo que cada cluster de processos manipule o mesmo tipo de solicitações. Seu software será muito mais simples se esses processos não compartilharem nenhum outro estado além de usar banco(s) de dados. Se esses processos compartilharem o estado interno, eles precisarão se conhecer, o que tornará mais difícil e mais complicado dimensionar adicionando mais processos ao cluster.
A sua aplicação será mais responsiva a alterações de carga e robusto à desestabilização se cada processo puder ser inicializado rapidamente e terminar com facilidade. Este é o fator 9, descartabilidade. Com o escalonamento dinâmico, você pode adicionar mais processos de forma rápida e automática para lidar com o aumento de carga, mas isso funciona somente se cada processo não precisar de muito tempo para ser inicializado antes de estar pronto para aceitar solicitações. Às vezes, um sistema desestabilizará e a maneira mais rápida de resolver a interrupção é reiniciar todos os processos, mas isso só funcionará se cada processo puder ser encerrado rapidamente sem perder nenhum dado.
Você evitará muitos erros e fragilidade se arquitetar seus sistemas de forma que o fluxo de solicitações de entrada seja tratado por muitos processos em execução simultaneamente. Esses processos podem, mas não precisam ser, "multi-threaded". Esses processos devem ser capazes de inicializar rapidamente e desligar graciosamente. Mais importante ainda, esses processos devem ser stateless e não compartilhar nada.
Obviamente, não há muita demanda por aplicações que não conseguem se lembrar de nada, então para onde vai o estado? A resposta está no banco de dados, mas as soluções de banco de dados também são softwares. Por que é correto que os bancos de dados sejam stateful, quando não há problema caso as aplicações sejam também? Já mencionamos que as aplicações precisam ser capazes de fornecer uma velocidade de recursos bastante rápida. O mesmo não é verdade para o software de banco de dados. É preciso muito tempo, pensamento e esforço de engenharia para fazer stateful bem feito com uma carga alta. Uma vez que você chegar lá, você não quer fazer grandes mudanças, porque o software stateful é muito complexo e fácil de quebrar.
Como mencionado anteriormente, há uma grande proliferação de tecnologias de banco de dados, muitas das quais são novas e relativamente não testadas. Você pode obter algum grau de utilidade de uma aplicação stateless depois de apenas alguns meses de engenharia. Alguns ou a maioria desses engenheiros podem ser recém-formados com pouca experiência profissional. Uma aplicação stateful é completamente diferente. Eu não apostaria em nenhuma tecnologia de banco de dados que não tivesse pelo menos duas décadas de esforço de engenharia. (Isso é décadas de engenharia, não décadas de calendário.) Esses engenheiros têm de ser profissionais experientes que são muito inteligentes e têm muita experiência em computação distribuída. Se você usar um mecanismo de banco de dados não testado ou imaturo, acabará introduzindo complexidade adicional em sua aplicação para contornar os erros e limitações. Depois que os bugs no banco de dados forem corrigidos, você terá que reprojetar a sua aplicação para remover a complexidade agora desnecessária.
| Inovando sua Stack tecnológica | |
| Prós | Contras |
|
|
É uma "Série de Tubos" depois de tudo
À medida que os sistemas evoluíram de uma única aplicação para clusters de aplicações e bancos de dados interconectados, um conjunto de conhecimentos foi catalogado para aconselhar sobre as formas mais eficazes pelas quais essas aplicações podem interagir uns com os outros. No início dos anos 2000, foi publicado um livro sobre padrões de integração empresarial (EIP) que capturava mais formalmente esse corpo de conhecimento.
Naquela época, um estilo de interação de serviços conhecido como arquitetura orientada a serviços se tornou popular. Em SOA, as aplicações se comunicavam por meio de um barramento de serviço corporativo (ESB) que também era programado para manipular as mensagens e encaminhá-las com base nas regras de configuração que representavam as práticas de EIP.
Os mecanismos de workflow são tecnologias similares, baseados em Redes de Petri, mais centrada nos negócios. Foi vendido com base na premissa de que não engenheiros poderiam escrever as regras, mas nunca cumpriram verdadeiramente essa promessa.
Essas abordagens introduziram muita complexidade desnecessária e pouco apreciada que as fez cair em desuso. A configuração cresceu para um complexo emaranhado de regras interconectadas que se tornaram muito resistentes a mudanças ao longo do tempo. E por que isso? É o mesmo problema que fazer com que o MDSD modele todos os requisitos. Linguagens de programação podem exigir mais conhecimento de engenharia do que linguagens de modelagem, mas também são mais expressivas. É muito mais fácil escrever ou entender um pequeno trecho de código escrito anteriormente para lidar com um requisito de EIP do que criar uma especificação de modelo de BPMN grande e complicada. Tanto o Camel (um projeto Apache) quanto o Mulesoft (adquirido pela Salesforce em 2018) são ESBs que tentam simplificar suas respectivas tecnologias. Espero que eles tenham sucesso.
A reação à ESB/SOA com fluxo de trabalho ficou conhecida como arquitetura MSA ou microsserviço. Em 2014, James Lewis e Martin Fowler resumiram as diferenças entre a MSA e a SOA. Com SOA, você tinha endpoints idiotas e pipes inteligentes. Com o MSA, você tinha endpoints inteligentes e pipes burros. A complexidade foi reduzida, mas talvez em demasia. Tais sistemas eram frágeis e não resilientes (isto é, facilmente desestabilizáveis) durante os tempos de falha parcial ou desempenho degradado. Também houve muita duplicidade nos microsserviços separados que cada um tinha para implementar as mesmas preocupações transversais, como a segurança. Isso é verdade (embora em menor grau), mesmo que cada implementação simplesmente incorpore a mesma biblioteca compartilhada.
O que se seguiu foi a introdução de gateways de API e "service meshes", ambos versões aprimoradas de balanceadores de carga da camada 7. O termo "camada 7" é uma referência ao modelo OSI ou "Open Systems Interconnection" que foi introduzido nos anos 80.
Quando as chamadas da Internet ou da intranet são destinadas a microsserviços no back-end, elas passam por um gateway de API que lida com recursos como autenticação, limitação de taxa e registro de solicitações, removendo esses requisitos de cada microsserviço individual.
Chamadas de qualquer microsserviço para qualquer outro microsserviço passam por "service mesh" que lida com preocupações como anteparo e quebra de circuito. Quando as solicitações para um tempo limite de serviço são muito frequentes, o "service mesh" falha imediatamente as chamadas futuras (por um tempo) em vez de tentar fazer as chamadas reais. Isso impede que o serviço não responsivo, fazendo com que os serviços dependentes também parem de responder, devido a todos os seus "threads" aguardarem no serviço original que não responde. Esse comportamento é semelhante a uma antepara em um navio impedindo que uma inundação se espalhe além de um compartimento. Com a quebra de circuito, a malha de serviço imediatamente falha chamadas (por um tempo) para um serviço que tem falhado a maioria de suas chamadas anteriores no passado recente. A justificativa para essa estratégia é que o serviço com falha ficou sobrecarregado e a prevenção de chamadas para esse serviço lhe dará a chance de se recuperar.
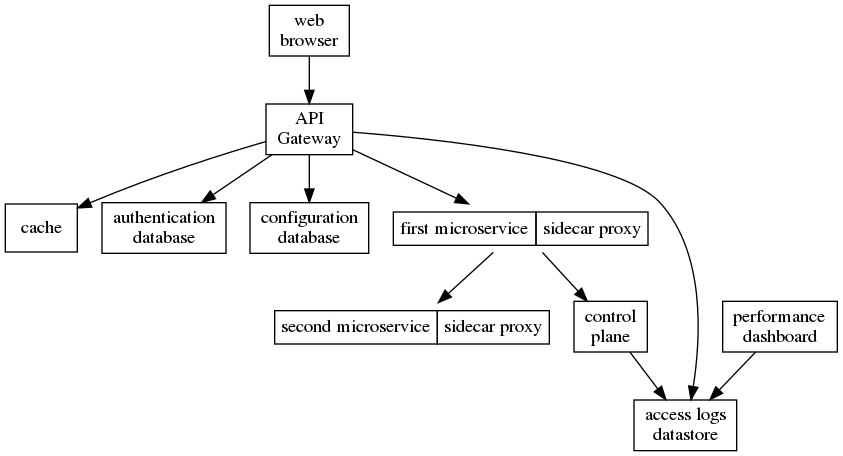
Implantando um gateway de API e um service mesh.
Gateways de API e service mesh tornam os microsserviços mais resilientes sem introduzir qualquer complexidade adicional no próprio código de microsserviço. No entanto, eles aumentam os custos operacionais devido à responsabilidade adicional de manter a integridade do gateway da API e / ou do service mesh.
| MSA vs SOA | |
| Prós | Contras |
|
|
A marcha dos frameworks
Outra maneira de reduzir a quantidade de código que os desenvolvedores precisam gravar é usar um "framework" de aplicação. Um "framework" é apenas uma biblioteca de rotinas de uso geral que implementam a funcionalidade comum a todos as aplicações. Partes do framework carregam primeiro e acabam chamando seu código mais tarde.
Como mencionei anteriormente, os bancos de dados relacionais foram originalmente desenvolvidos em meados dos anos 70 e foram tão úteis que permaneceram populares em todas as tendências tecnológicas descritas anteriormente. Eles ainda são populares hoje em dia, mas usá-los no mundo das aplicações Web apresenta muita complexidade. As conexões com bancos de dados relacionais são stateful e de longa duração, mas as solicitações típicas da Web são stateless e de curta duração. O resultado final é que os serviços multi encadeados lidam com essa complexidade usando uma técnica conhecida como pool de conexões. Aplicações "single-threaded" são menos eficientes dessa maneira; portanto, eles precisam depender mais de fragmentação e replicação.
Programação orientada a objeto tornou-se bastante popular durante a era cliente-servidor e manteve sua popularidade desde então. Os dados relacionais não se encaixam na estrutura orientada a objetos com muita facilidade, então os frameworks de mapeamento objeto-relacional foram desenvolvidos na tentativa de obscurecer esse tipo de complexidade. Os frameworks ORM populares incluem Hibernate, SQLAlchemy, LoopBack e Entity Framework.
Nos primórdios do desenvolvimento de aplicações Web, tudo foi construído no que mais tarde ficou conhecido como o monolito. A interface gráfica do usuário ou a GUI (basicamente HTML, CSS e JavaScript renderizados pelo navegador) foi gerada no lado do servidor. Padrões como o MVC (model view controller) foram usados para coordenar a renderização da GUI com acesso a dados, regras de negócios, etc. Na verdade, existem muitas variações no MVC, mas, para o propósito deste artigo, estou agrupando todas na mesma categoria como MVC. O MVC ainda está por aí, e os populares frameworks MVC modernos incluem Play, Meteor, Django e ASP.NET.
Com o tempo, esses tipos de aplicações tornaram-se grandes e complicados; tão grande que seu comportamento era difícil de entender ou prever. Fazer alterações em uma aplicação era arriscado e liberar novas versões era prejudicial porque era difícil testar e verificar a exatidão desses sistemas excessivamente complexos. Muito tempo de engenharia foi gasto rapidamente corrigindo o código de buggy que foi implantado sem a devida habilitação. Quando você é forçado a consertar algo rapidamente, você não tem tempo para encontrar a melhor solução, fazendo com que o código de baixa qualidade entre. A intenção é substituir esse código de baixa qualidade por código de boa qualidade mais tarde.
A resposta foi dividir o monolito em múltiplos componentes ou microsserviços que poderiam ser liberados separadamente. O código da GUI foi movido para o que agora é chamado de SPA (aplicativos de página única), bem como para aplicativos móveis nativos. O acesso a dados e as regras de negócios foram mantidos no lado do servidor e divididos em vários serviços. Estruturas de microsserviços populares incluem o Flask e o Express. O Spring Boot e o Dropwizard são os mais populares contêineres servlet baseados em Jersey para desenvolvedores Java.
As estruturas de microsserviços eram originalmente simples, fáceis de aprender e exibiam um comportamento que era fácil de entender e prever. Aplicações construídas sobre essas estruturas leves se tornaram grandes ao longo do tempo devido aos fatores de complexidade mencionados acima. Quanto maior a aplicação se torna, mais se assemelha a um monólito. Quando eles não estavam dividindo grandes microsserviços em pequenos, os arquitetos começaram a procurar maneiras de reduzir o tamanho da aplicação ocultando a complexidade relacionada na estrutura. Usar software opinativo, padrões de design baseados em anotação e substituir o código pela configuração reduziram o número de linhas de código nas aplicações, mas tornaram as estruturas mais pesadas.
Aplicações que usam uma estrutura pesada tendem a ter menos linhas de código e desfrutam de uma velocidade de recurso mais rápida, mas há desvantagens para essa forma de complexidade obscura. Por sua própria natureza, os frameworks são mais genéricos que as aplicações, o que significa que é preciso muito mais código para fazer o mesmo trabalho. Embora você tenha menos código em uma aplicação personalizada, o executável real, que inclui o código de estrutura relevante, é muito maior. Isso significa que levará mais tempo para a aplicação ser iniciada à medida que todo esse código extra for carregado em memória. Todo esse código extra invisível também significa que os rastreamentos de pilha (que são gravados no log da aplicação sempre que uma exceção inesperada é lançada) serão muito mais longos. Um rastreamento de pilha maior leva mais tempo para um engenheiro ler e entender quando depurar.
Na melhor das hipóteses, o ajuste de desempenho pode ser um pouco de arte negra. Pode ser preciso muita tentativa e erro para alcançar a combinação certa de tamanhos de conjuntos de conexões, durações de expiração de cache e valores de tempo limite de conexão. Isso se torna ainda mais assustador quando você não vê o código que está tentando ajustar. Essas estruturas são de código aberto, então você pode estudar o código, mas a maioria dos desenvolvedores não.
| Frameworks leves vs pesados | |
| Prós | Contras |
|
|
Consistência Eventual
Em vez de processar cada solicitação de API de maneira síncrona imediatamente, os sistemas reativos passam mensagens de forma assíncrona para seus subsistemas internos para, eventualmente, processar cada solicitação da API.
É difícil dizer quando a programação reativa foi introduzida pela primeira vez. O Manifesto Reativo foi publicado em julho de 2013, mas havia muitos precursores para isso. O pubsub, ou padrão de publicação-assinatura, foi introduzido pela primeira vez em meados dos anos 80. Processamento complexo de eventos, ou CEP, experimentou brevemente alguma popularidade nos anos 90. O primeiro artigo que vi sobre SEDA, ou arquitetura orientada a eventos, foi publicado perto do final de 2001. "Event sourcing" é uma variação recente do tema da programação reativa. Sistemas reativos podem ser codificados no estilo pubsub ou como fluxos de mensagens em linguagens de script de domínio que se assemelham a programação funcional.
Quando um sistema de programação reativa é distribuído em vários computadores, geralmente há (mas nem sempre) um intermediário de mensagem envolvido. Alguns dos "brokers" mais populares são Kafka, RabbitMQ e ActiveMQ. Recentemente, o pessoal do Kafka lançou uma biblioteca do lado do cliente chamada Kafka Streams.

Implantação típica para um sistema distribuído totalmente reativo.
ReactiveX é uma estrutura reativa muito popular com bibliotecas para muitas linguagens de programação diferentes. Para programadores Java, há Spring Integration ou Spring Cloud Data Flow, Vert.x e Akka.
Veja como os arquitetos usam a programação reativa para obscurecer a complexidade. As chamadas para microsserviços se tornam assíncronas, o que significa que o que foi solicitado à API não precisa ser feito quando as chamadas retornam. Isso também é conhecido como consistência eventual. Isso torna esses microsserviços mais resistentes a interrupções parciais ou ao desempenho degradado do banco de dados sem introduzir muita complexidade adicional. Você não precisa se preocupar com o tempo limite do autor da chamada e o reenvio enquanto a transação original ainda estiver em execução. Se algum recurso não estiver disponível, aguarde até que fique disponível novamente. Admito que pode ser um desafio para os desenvolvedores juniores depurar programas reativos (especialmente se codificados no estilo pubsub), mas isso é principalmente porque eles não estão familiarizados com esse paradigma.
Então, para onde foi a complexidade? Há muita complexidade nos "message brokers" modernos, mas você provavelmente só poderá usar um desses e não terá que escrever o seu próprio. Como qualquer tecnologia, eles têm suas próprias advertências, mas têm limitações muito razoáveis.
Para o desenvolvimento de aplicações, a complexidade foi movida para o frontend. A consistência eventual pode ser maravilhosa para os sistemas de backend, mas é terrível para os humanos. Talvez você não se importe quando suas fotos de férias alcancem todos os seus amigos em sua rede social, mas se você for um cliente corporativo negociando um pedido de vários estágios interconectados, convém saber exatamente quando cada parte de seu pedido é submetido, validado, aprovado, programado e, eventualmente concluído.
Para que a GUI acomode essa necessidade psicológica muito humana, será necessário notificar o usuário quando o que foi solicitado do back-end for concluído. Como a chamada da API não é síncrona, o frontend terá que descobrir outra maneira. A pesquisa da API para atualizações de status não é bem dimensionada. Isso significa que o navegador Web ou o dispositivo móvel precisará usar uma conexão stateful e de longa duração pela qual possa receber atualizações do back-end sem qualquer aviso. Antigamente, você poderia estender os servidores XMPP para fazer isso. Para navegadores modernos, há um bom suporte para websockets e eventos enviados pelo servidor. Spring WebFlux, socket.io e SignalR são três bibliotecas populares que permitem que os serviços do lado do servidor se comuniquem com o javascript do lado do cliente dessa maneira.
Os navegadores da Web impõem limites a essas conexões, portanto, a aplicação cliente precisará compartilhar a mesma conexão para receber todas as notificações. Como a maioria dos balanceadores de carga fecha conexões inativas, a aplicação deve contabilizar isso enviando ocasionalmente mensagens "keep alive". Dispositivos móveis são notórios por falhas de conexão intermitentes, exigindo lógica de reconexão no software cliente. Além disso, deve haver algum mecanismo pelo qual a aplicação cliente possa associar cada notificação (pode haver mais de um) à chamada da API original. Ainda precisa haver algum mecanismo para determinar o status de chamadas de API anteriores para quando o usuário retornar a aplicação depois de estar ausente.
| Sistemas Reativos e Consistência Eventual | |
| Prós | Contras |
|
|
Conclusão
Desde os primeiros dias dos primeiros mainframes até os dias atuais com a nuvem, os sistemas cresceram em complexidade e os arquitetos de software descobriram novas maneiras de gerenciar essa complexidade. Quando possível, reduzir a complexidade sem sacrificar a capacidade é o melhor curso de ação. Twelve-Factor Apps têm ótimos conselhos sobre como fazer isso. Com EIP, sistemas reativos e consistência eventual, você pode pensar que está reduzindo a complexidade quando, na verdade, está apenas empurrando-o para outra parte do sistema. Às vezes você só precisa esconder a complexidade, e há muitos geradores, estruturas e conectores baseados em modelos para ajudá-lo a fazer isso, mas há vantagens e desvantagens nessa abordagem. Como aprendemos com o Twelve-Factor Apps e com sistemas reativos, nada aumenta a complexidade, como statefulness, portanto, seja muito cauteloso e conservador ao adicionar ou aumentar statefulness em seus aplicativos. No entanto, eles reduzem, ocultam ou redistribuem, os arquitetos de software continuarão gerenciando a complexidade para continuar entregando software de qualidade mais rapidamente em um mundo com demandas cada vez maiores por mais funcionalidade, capacidade e eficiência.
Sobre o Autor
 Glenn Engstrand é arquiteto de software na Adobe, Inc .. Seu foco é trabalhar com engenheiros para fornecer arquiteturas de aplicações compatíveis com o Twelve Factor, do lado do servidor. Engstrand foi palestrante na conferência interna de desenvolvedores da Adobe Cloud em 2018 e 2017, e na conferência Lucene Revolution de 2012 em Boston. Ele é especialista em dividir aplicações monolíticas em microsserviços e em profunda integração com a infraestrutura de comunicação em tempo real.
Glenn Engstrand é arquiteto de software na Adobe, Inc .. Seu foco é trabalhar com engenheiros para fornecer arquiteturas de aplicações compatíveis com o Twelve Factor, do lado do servidor. Engstrand foi palestrante na conferência interna de desenvolvedores da Adobe Cloud em 2018 e 2017, e na conferência Lucene Revolution de 2012 em Boston. Ele é especialista em dividir aplicações monolíticas em microsserviços e em profunda integração com a infraestrutura de comunicação em tempo real.