Pontos Principais
- Como detectar anomalias em streaming de dados usando Prometheus, Apache Kafka e Apache Cassandra.
- Os componentes do Prometheus incluem o servidor Prometheus, o modelo de métricas de dados, a GUI de gráficos integrados e o suporte nativo do Grafana.
- Usando o Prometheus, é possível monitorar métricas de aplicações, como taxa de transferência (TPS) e tempos de resposta do Kafka load generator (produzido pelo Kafka), do consumidor Kafka e do cliente Cassandra.
- O Node exporter pode ser usado para monitorar o hardware do host e as métricas do kernel.
- Os recursos gráficos integrados do Prometheus são limitados e a adição do Grafana oferece expansão desses recursos.
Anomalia Machina - uma aplicação que une o Apache Kafka e o Apache Cassandra para detectar anomalias de dados de streaming - é um projeto experimental que está em desenvolvimento para uso em toda a plataforma de tecnologias gerenciadas de código aberto. O projeto exige a execução da aplicação (por exemplo, um gerador de carga e um pipeline detector) em várias instâncias do EC2. Mas antes disso, é necessário obter uma maneira de coletar e visualizar indicadores e métricas específicas de aplicações a partir de instâncias distribuídas, a fim de executar a aplicação implantada pelo Kubernetes. Neste artigo, será detalhado como o Prometheus, uma ferramenta de monitoramento de código aberto, pode auxiliar na realização dessa tarefa.
Entendendo o sistema de monitoramento e alerta do Prometheus
Desenvolvido originalmente pela SoundCloud, tornou-se código aberto e foi aceito como segundo projeto na Cloud Computing Foundation (CNCF) em 2016, o Prometheus é uma ferramenta cada vez mais popular que fornece monitoramento e alertas em aplicações e servidores.
A arquitetura do Prometheus é representada a seguir:

Componentes
Os principais componentes do Prometheus incluem o servidor Prometheus (que lida com descoberta de serviços, recuperação e armazenamento de métricas de aplicações monitoradas, análise de dados de séries temporais usando a linguagem de consulta PromQL), um modelo de métricas de dados, um simples built-in GUI e suporte nativo ao Grafana. Componentes opcionais adicionais incluem um gerenciador de alertas (no qual os alertas podem ser definidos na linguagem de consulta) e um gateway de envio útil para monitorar aplicações de curta duração.
Geralmente, as ferramentas de monitoramento de aplicações capturam indicadores e métricas por meio de um desses três métodos:
- Instrumentação: adicionando código personalizado ao código-fonte da aplicação monitorada.
- Agentes: Adicionando código especial de propósito geral ao ambiente de aplicações para capturar automaticamente as métricas padrão.
- Espionagem: usando interceptores ou taps de rede para monitorar chamadas ou fluxo de dados entre sistemas.
O Prometheus dá suporte ao uso de uma combinação de instrumentação e agentes (chamados de "exportadores"). Para instrumentação é necessário acesso ao código-fonte da aplicação e com isso possibilita-se a captura de métricas personalizadas. O Prometheus também é agnóstico em linguagem de programação e possui bibliotecas de cliente oficiais que são compatíveis e estão disponíveis para Go, Java / Scala, Python e Ruby. Muitas bibliotecas não oficiais também estão disponíveis (LISP, etc.) sendo possível ainda desenvolver suas próprias bibliotecas.
Muitos exportadores de terceiros estão disponíveis para permitir a instrumentação automática de um software específico, incluindo bancos de dados populares, hardware, sistemas de mensagens, armazenamento, HTTP, APIs na nuvem, criação de log, sistemas de monitoramento, dentre outros. O exportador JMX pode exportar métricas e indicadores para aplicações baseados na JVM, como Kafka e Cassandra. Ao mesmo tempo, alguns sistemas de software expõem métricas no formato do Prometheus, tornando, portanto, os exportadores desnecessários.
O node exporter está disponível para monitorar o hardware do host e as métricas do kernel. O cliente Java do Prometheus apresenta coletores para coleta de objetos em memória não utilizados (garbage collector), conjuntos de memória, JMX, carregamento de classe e contagens de thread, que podem ser incluídos um de cada vez ou registrados de uma só vez usando:
DefaultExports.initialize();
O que o Prometheus se propõe a fazer (e o que não se propõe)
O Prometheus é ótimo para monitorar métricas e indicadores,e só. Não é uma ferramenta eficaz de Gerenciamento de Desempenho de Aplicações, porque se concentra exclusivamente em métricas do lado do servidor. A ferramenta não oferece rastreamento de chamada distribuída, descobrimento e visualização de topologia de serviço, análise de desempenho ou monitoramento da experiência do usuário final (embora exista uma extensão no github que pode enviar métricas do navegador do usuário ao Prometheus). O fluxo da informações no Prometheus é unidirecional, portanto, não pode ser usado para controle ativo. Por fim, o Prometheus é executado como um único servidor por padrão, mas pode ser dimensionado usando uma federação de servidores.
Modelagem de dados no Prometheus

Fig 420,000 years of Antarctic ice core time-series data
O Prometheus armazena métricas na forma de dados de séries temporais , de modo que as métricas incluem streams de valores do tipo timestamp com milissegundos (float de 64 bits). Cada métrica possui um nome (uma string) e usa uma convenção de nomenclatura que inclui o nome do que está sendo monitorado, o tipo lógico e as unidades de medida. Cada métrica também tem um conjunto de pares chave/valor (as dimensões rotuladas). Por exemplo, uma métrica denominada http_requests_total poderia incluir rótulos para "método" ("GET", "PUT") e para "handler" (por exemplo: "/login", "/search"). O Prometheus também adiciona alguns rótulos às métricas automaticamente, incluindo:
- job: o nome do job configurado ao qual o target pertence.
- Instância: A parte <host>: <porta> da URL extraída do destino.
Como as unidades não são explícitas, as conversões de uma unidade para outra só podem ser feitas manualmente no idioma da consulta (e devem ser executadas com muito cuidado).
Tipos de métricas
O Prometheus oferece os quatro tipos de métricas:
- Contador: Um contador é útil para valores incrementais(os valores podem ser redefinidos para zero no momento da reinicialização).
- Medidor: Um medidor pode ser usado para contagens e valores que que podem aumentar e diminuir.
- Histograma: Um histograma mostra observações, como tempo de solicitação ou tamanhos de resposta. Ele conta essas observações em intervalos possíveis que podem ser configurados, além de oferecer a soma de todos os valores observados.
- Resumo: Assim como um histograma, um resumo de amostras de observações oferece uma contagem total e a soma dos valores observados, ao mesmo tempo em que calcula quantos que são configuráveis em uma janela de tempo variável.
Colocando Prometheus para Trabalhar na Monitoração da Anomalia Machina
Para entender o que recentemente se pretendeu monitorar com o experimento Anomalia Machina, veja o diagrama de arquitetura funcional a seguir:
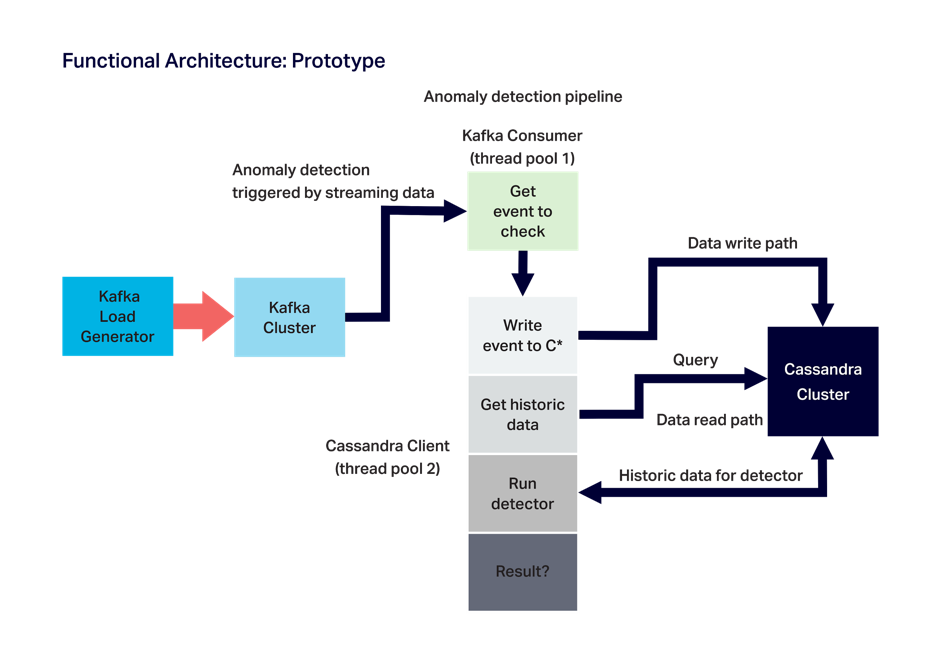
Usando o Prometheus, foram monitoradas as métricas de aplicações "genéricas", incluindo a taxa de transferência (TPS) e os tempos de resposta do Kafka load generator (produzidos pelo Kafka), do consumidor Kafka e do cliente Cassandra (que detecta anomalias). Além disso, havia-se a necessidade de monitorar algumas métricas específicas da aplicação, incluindo o número de linhas retornadas para cada leitura do Cassandra e o número de anomalias detectadas. Também era necessário monitorar as métricas de hardware, como a CPU, para cada uma das instâncias do AWS EC2 nas quais o aplicativo é executado, além de centralizar o monitoramento adicionando métricas do Kafka e do Cassandra também.
Para conseguir isso, começamos criando um pipeline de teste simples com três métodos (produtor, consumidor e detector). Em seguida, usamos uma métrica de contador chamada "prometheusTest_requests_total", que mede quantas vezes cada estágio do pipeline é executado com êxito e um rótulo chamado "stage" para diferenciar as diferentes contagens do cenário (usando "total" para a contagem total de pipeline). Em seguida, usamos um segundo contador chamado "prometheusTest_anomalies_total" para contar as anomalias detectadas e usamos um medidor chamado "prometheusTest_duration_seconds" para registrar a duração de cada estágio em segundos (usando um rótulo de "stage" para distinguir os estágios e um rótulo "total" para a duração total do pipeline).
Os métodos têm instrumentos que incrementam as métricas contadas a cada vez que um estágio é executado com sucesso ou uma anomalia é detectada (usando o método inc() ) e definem o valor de tempo da métrica do medidor para cada estágio (usando o método setToTime()).
A seguir um código de exemplo:
import java.io.IOException;
import io.prometheus.client.Counter;
import io.prometheus.client.Gauge;
import io.prometheus.client.exporter.HTTPServer;
import io.prometheus.client.hotspot.DefaultExports;
// https://github.com/prometheus/client_java
// Demonstração de como planejamos usar o cliente Java Prometheus para o instrumento Anomalia Machina.
// Observe que o aplicativo Anomalia Machina terá o consumidor do Kafka Producer e do Kafka e o restante do pipeline sendo executado em vários processos / instâncias separadas.
// Assim, as métricas de cada uma delas terão diferentes combinações de host / porta.
public class PrometheusBlog {
static String appName = "prometheusTest";
// os contadores só podem apenas aumentar seu valor (até o reinício do processo)
// Utilizamos um único contador para todos os estágios do pipeline, os estágios são diferenciados pelos rótulos
static final Counter pipelineCounter = Counter.build()
.name(appName + "_requests_total").help("Count of executions of pipeline stages")
.labelNames("stage")
.register();
// seria possível usar o PipelineCounter para contar anomalias encontradas usando outro rótulo
// mas para evitar confusão melhor utilizamos outro contador.
static final Counter anomalyCounter = Counter.build()
.name(appName + "_anomalies_total").help("Count of anomalies detected")
.register();
// O medidor pode subir e descer e é usado para medir o valor atual de alguma variável.
// O objeto pipelineGauge medirá a duração em segundos de cada estágio usando o rótulo “stage”.
static final Gauge pipelineGauge = Gauge.build()
.name(appName + "_duration_seconds").help("Gauge of stage durations in seconds")
.labelNames("stage")
.register();
public static void main(String[] args) {
// Permite que as métricas padrão da JVM sejam exportadas
DefaultExports.initialize();
// As métricas são puxadas pelo Prometheus, crie um servidor HTTP como o terminal
// Observe se há vários processos em execução no mesmo servidor e caso seja necessário, alterar o número da porta.
// Adicione todos os IPs e números de porta ao arquivo de configuração do Prometheus
HTTPServer server = null;
try {
server = new HTTPServer(1234);
} catch (IOException e) {
e.printStackTrace();
}
// 1000 execuções do pipeline completo com atrasos de tempo aleatórios e taxa crescente
int max = 1000;
for (int i=0; i < max; i++)
{
// tempo total para pipeline completo e variável anomalyCounter incrementada
pipelineGauge.labels("total").setToTime(() -> {
producer();
consumer();
if (detector())
anomalyCounter.inc();
});
// contador total do pipeline
pipelineCounter.labels("total").inc();
System.out.println("i=" + i);
// aumentar a taxa de execução
try {
Thread.sleep(max-i);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
server.stop();
}
// para cada um dos 3 estágios do pipeline, aumentamos o contador e definimos o tempo de duração do medidor
public static void producer() {
class Local {};
String name = Local.class.getEnclosingMethod().getName();
pipelineGauge.labels(name).setToTime(() -> {
try {
Thread.sleep(1 + (long)(Math.random()*20));
} catch (InterruptedException e) {
e.printStackTrace();
}
});
pipelineCounter.labels(name).inc();
}
public static void consumer() {
class Local {};
String name = Local.class.getEnclosingMethod().getName();
pipelineGauge.labels(name).setToTime(() -> {
try {
Thread.sleep(1 + (long)(Math.random()*10));
} catch (InterruptedException e) {
e.printStackTrace();
}
});
pipelineCounter.labels(name).inc();
}
// o método detector retorna verdadeiro se anomalia detectada caso contrário false
public static boolean detector() {
class Local {};
String name = Local.class.getEnclosingMethod().getName();
pipelineGauge.labels(name).setToTime(() -> {
try {
Thread.sleep(1 + (long)(Math.random()*200));
} catch (InterruptedException e) {
e.printStackTrace();
}
});
pipelineCounter.labels(name).inc();
return (Math.random() > 0.95);
}
}
Com o código de exemplo preparado, é importante entender como executar o Prometheus e como ele obtém os valores métricos do código. Em contraste com as soluções de gerenciamento de desempenho de aplicações corporativas que possuem métricas que são aplicadas a elas, o Prometheus recebe métricas por meio de código instrumentado de polling. Isso requer simplesmente que um servidor HTTP seja executado no código da aplicação: o código anterior cria um servidor HTTP na porta 1234 permitindo ao Prometheus rastrear as métricas.
Para fazer o download e executar o Prometheus, siga o guia documentado em "getting started"
Em seguida, é necessário resolver as dependências do Maven:
<!-- O Cliente -->
<dependency>
<groupId>io.prometheus</groupId>
<artifactId>simpleclient</artifactId>
<version>LATEST</version>
</dependency>
<!-- Métricas Hotspot JVM-->
<dependency>
<groupId>io.prometheus</groupId>
<artifactId>simpleclient_hotspot</artifactId>
<version>LATEST</version>
</dependency>
<!-- Exposição do servidor HTTP-->
<dependency>
<groupId>io.prometheus</groupId>
<artifactId>simpleclient_httpserver</artifactId>
<version>LATEST</version>
</dependency>
<!-- Exposição do Pushgateway-->
<dependency>
<groupId>io.prometheus</groupId>
<artifactId>simpleclient_pushgateway</artifactId>
<version>LATEST</version>
</dependency>
E finalmente, é necessário indicar ao Prometheus a origem do scraping. Para implantações simples ou testes, é adequado adicionar essas informações ao arquivo de configuração (por padrão o arquivo é o “prometheus.yml”), conforme exemplo a seguir:
global:
scrape_interval: 15s # Por padrão, intervalo de polling é de 15 segundos.
# scrape_configs tem jobs e targets para cada polling.
scrape_configs:
# job 1 é para testar a instrumentação prometheus de vários processos de aplicativos.
# O nome do job é adicionado como um rótulo job= <job_name> a qualquer série temporal extraída desta configuração.
- job_name: 'testprometheus'
# Substituir o padrão global de polling alvos deste job para 5 segundos.
scrape_interval: 5s
# Aqui colocar vários alvos, por ex. para geradores de carga e detectores Kafka
static_configs:
- targets: ['localhost:1234', 'localhost:1235']
# job 2 fornece métricas do sistema operacional (por exemplo, CPU, memória, etc.).
- job_name: 'node'
# Substituir o padrão global de polling alvos deste job para 5 segundos.
scrape_interval: 5s
static_configs:
- targets: ['localhost:9100']
O arquivo de configuração também inclui um job chamado "node", usando a porta 9100. Esse trabalho fornece métricas do nó - usá-lo requer o download e execução do Prometheus node exporter no mesmo servidor da aplicação. Há prós e contras para a pesquisa de métricas: a pesquisa muitas vezes pode sobrecarregar as aplicações, enquanto não pesquisar com freqüência suficiente pode gerar atrasos preocupantes entre o momento em que os eventos acontecem e quando eles são de fato percebidos e detectados.
Ao mesmo tempo, esse sistema é robusto e bastante desacoplado, já que as aplicações podem ser executados sem o Prometheus, e o Prometheus simplesmente continuará tentando fazer uma pesquisa das aplicações indisponíveis até que elas estejam disponíveis. Também é possível pesquisar uma única aplicação com vários servidores Prometheus. Mas se, por algum motivo, não for possível pesquisar as métricas da aplicação, ou se ela for altamente transitória, o Prometheus poderá usar um push gateway como uma alternativa.
Resultados iniciais do uso do Prometheus
O Prometheus não inclui dashboards por padrão, portanto, inicialmente, usamos expressões em nosso experimento. Na interface do Prometheus, é possível encontrar um menu a partir do qual podemos selecionar as métricas (também é possível acessar essa opção a partir do navegador em http://localhost:9090/metrics). Podemos inserir as métricas na caixa de expressão e executá-las. Infelizmente é possível se deparar com uma mensagem de erro e talvez seja necessário resolver algum problema nesse estágio (essa é uma experiência comum).
Quando as expressões de trabalho estiverem no lugar, será possível visualizar os resultados em uma tabela ou em um gráfico, se disponível para esse tipo de resultado. Por padrão, as expressões retrocedem apenas cinco minutos para encontrar os dados e, se os dados não estiverem disponíveis, um erro será exibido. Com o objetivo de testar o Prometheus, é possível aproveitar que o mesmo se auto monitora para explorar a solução sem precisar que uma aplicação instrumentada de fato e na prática esteja disponível.
Gráficos de dados
Como uma métrica do contador simplesmente incrementa em valor, a representação gráfica do um contador será uma linha como o mostra a figura a seguir:

Para obter um gráfico das taxas com base em uma métrica do contador, utilize a função irate ou a função rate.

No exemplo a seguir, o gráfico exibe as durações dos estágios do pipeline e não exige uma função da taxa uma vez que é um medidor em vez de um contador:

Embora os recursos gráficos integrados do Prometheus sejam limitados, por exemplo, não é possível representar graficamente mais de uma métrica no mesmo gráfico, é possível ampliar esses recursos com o Grafana. O Grafana oferece suporte embutido ao Prometheus, e é obrigatório para o uso de gráficos com mais opções. Os sites do Prometheus e do Grafana oferecem documentação útil sobre como usar essas ferramentas em conjunto.
Para usar o Grafana, instale-o e navegue em seu navegador com a URL http://localhost:3000/. Crie uma fonte de dados do Prometheus e adicione um gráfico usando uma expressão como de costume. Por exemplo, o gráfico a seguir é capaz de exibir as métricas de duração e taxa:

Uma dica: se nada for visível no gráfico, provavelmente você não está visualizando o intervalo de tempo correto. Para solucionar rapidamente use um "intervalo pequeno" - os "últimos 5 minutos" deve ser suficiente. Você também pode usar regras para pré-compilar as taxas, a fim de acelerar a agregação.
Também é possível fazer o gráfico das métricas dos nós, como a utilização da CPU (esse blog fornece um guia de como implementar a solução). Por exemplo, é possível calcular a utilização da CPU como uma porcentagem com essa expressão:
100 - (avg by (instance)
(irate(node_cpu_seconds_total{job="node",mode="idle"}[5m])) * 100)
Por fim, aqueles que usam o Cassandra em conjunto com essas ferramentas também podem encontrar valor ao usar o Cassandra Exporter for Prometheus da Instaclustr, que é ideal para integrar as métricas do Cassandra de um cluster autogerenciado ao monitoramento de aplicações, aproveitando o Prometheus. A ferramenta é bem documentada e fornece um ponto de partida útil para o desenvolvimento de uma compreensão mais profunda do Prometheus.
Tendo compilado o conhecimento sobre como usar o Prometheus para monitorar um exemplo de aplicação, é possível monitorar o código real da aplicação Machine Anomalia e colocá-la em produção com confiança.
Sobre o Autor
 Paul Brebner é evangelista chefe de tecnologia na Instaclustr, que fornece uma plataforma de serviços gerenciados de tecnologias de software livre, como o Apache Cassandra, o Apache Spark, o Elasticsearch e o Apache Kafka.
Paul Brebner é evangelista chefe de tecnologia na Instaclustr, que fornece uma plataforma de serviços gerenciados de tecnologias de software livre, como o Apache Cassandra, o Apache Spark, o Elasticsearch e o Apache Kafka.