Introduction
Many approaches to object oriented modeling tend not to scale well when the applications grow in size and complexity. Context Mapping is a general purpose technique, part of the Domain Driven Design (DDD) toolkit, helps the architects and developers manage the many types of complexity they face in software development projects. Different from other well known DDD patterns, context mapping applies to any kind of software development scenario and provides a high level view that might help the developers to take strategic decisions, like whether to go for a full scale DDD implementation or not in their specific project environment.
In this article we'll explore the many sides of bounded contexts and how to use them in building a context map to support key decisions in a software development project.
Many models at play
Domain Driven Design puts a great emphasis in maintaining the conceptual integrity of the model of your application. This is achieved by a combination of several factors:
- an agile process that emphasizes frequent feedback from users and domain experts,
- the availability of real domain experts and a creative collaboration with them,
- a single and shared version of the model (in the application and test code) precisely defined in terms of the Ubiquitous Language, and
- an open and transparent environment that promotes learning and exploration.
This is crucial for creating a safe harbor where high quality design can thrive and deliver its benefits. In such a place, typical DDD elements such as Entities, Value Objects and Aggregates deliver an emerging order to a complex domain model. Even so, the traditional DDD approach could not be applied blindly to an indefinitely large domain model without compromising the conceptual integrity of the model.
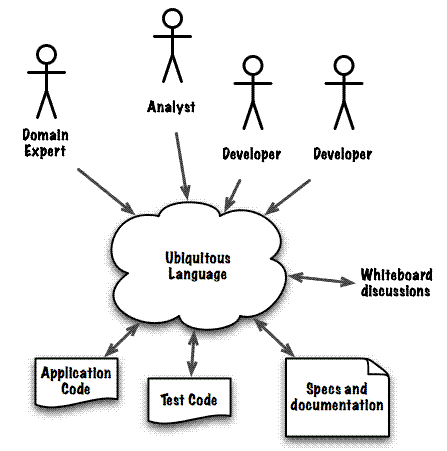
As shown in Figure 1, the key role of Ubiquitous Language in DDD is to act like an integrity check for our model. Using the same term, with a very precisely and unambiguously defined meaning, spanning from discussions with the domain expert to the code level, assures that everybody in the team shares the same vision about the domain and the software.

Figure 1. The Ubiquitous Language should be the only language used to express a model. Everybody in the team should be able to agree on every specific term without ambiguities and no translation should be needed
Code is the primary form of expression of the model. Although other artifacts might be necessary along the way to capture requirements or portions of the design, the only one that'll be constantly in sync with the application behavior is code itself. This modeling nirvana is a somewhat fragile ecosystem: it can be achieved, given the conditions described before, but it can't be extended indefinitely. The maximum extent a model can be stretched without compromising its conceptual integrity is called a context.
Enter Bounded Contexts
In Domain Driven Design, a Context is defined as:
"The setting in which a word or a statement appears that determines its meaning"
which might sound rather vague at first read. It doesn't say much about expected size, shape or other characteristics of a context. We'll eventually discover that this definition is rather precise, describing exactly what a context is, but to get a glimpse of that we probably need a few concrete examples.
Example 1: Same term, different meaning
Let's start with a simple example where the ambiguity might happen at the terminology level. Some words have different meaning depending on the context they’re used in.
Let's suppose we're working on a web-based Personal Finance Management Application (PFM) . We'll probably use this application to manage the banking accounts, stocks, and savings, to track the budget and expenses, and so on.
In our application, the domain term Account might refer to different concepts. Talking about banking, an account is some kind of a logical "container for money"; we'll then expect the corresponding class to have attributes such as balance, account number, and so on. But, in the context of web applications, the term account has a very different meaning, related to authentication and user credentials. The corresponding model, as shown in Figure 2, will then be something completely different.

Figure 2. A somewhat trivial case of ambiguity: the term Account might mean something very different according to the context it's used in
This is probably the simplest case of ambiguity we can run into when modeling our applications: same term, with two different context dependent meanings. This issue is often resolved by partitioning the name space by adding some prefix to the class name (be it the name itself or part of the package). But on a conceptual level, we must be aware that we have two different contexts in play, sometimes they're different enough to prevent developers from doing mistakes, but sometimes the difference might be subtle.
Unfortunately, working at a class name level might not always be a viable solution: in the domain of Banking, the term Banking Account might already exist, with a different meaning, or the domain expert would insist that Account is the right term. Resist the temptation to invent a specific trade-off term, or to introduce a translation offset from domain expert terms to code. You're facing two separate contexts here.
Drawing our first context map
When ambiguity gets in the way, we need a tool to make the development team aware of the existence of two different contexts within the application. Ambiguity is the super-villain of our Ubiquitous Language, and we need to get rid of it. The best way for doing that is to expose the domain structure in terms of bounded contexts in a context map. Figure 3 shows a simple context map.

Figure 3. A simple context map with two domain contexts in play
In the Domain Driven Design book, the Context Map is designated as the primary tool used to make context boundaries explicit. The basic idea is to draw context boundaries on the whiteboard, optionally filling them up with relevant domain terms of classes. This is not a precise well-defined UML diagram: it's a working tool that allows us to map a fuzzy situation, so a somewhat fuzzy look is necessary.
Example 2: Same concept, different use
A more puzzling distinction might arise when the underlying concept is the same, but used in different ways, eventually leading to different models. The model for our Banking Account might be a BankingAccount class like the one shown in Figure 4 below.

Figure 4. A really simplified version of BankingAccount class
Some PFM apps allow us also to manage payments, usually keeping a Payee Registry. In this scenario, a payee might be associated with one or more Banking Accounts, but in this case we won't know anything of the internals of payee banking account, nor can we issue any operation on those accounts. Does it make sense to model the Payee account with the BankingAccount class we've just defined?

Figure 5. Payee and BankingAccount classes
Well... it does sound reasonable: after all it's the same concept, in the real world our account and the payee's one might even be in the same physical bank. Still, it doesn't feel completely right: we are not supposed to issue any operation on the payee Banking Account, or to track anything on that. Even worse: doing so would probably be a conceptual mistake within our application.
So what should we do? We just ran into two different contexts within the same application (again): this time we could end up modeling the same domain concept in two different ways, because we have two clear and distinct uses, each one calling for a distinct model. The BankingAccount might still be a class that allows us to perform (or track) specific operation (such as deposit or withdraw) while a separate class PayeeAccount could possibly have some data in common with BankingAccount (such as the accountNumber), but a simpler model and a definitely different behavior (we shouldn't be able to access the payees' balance, for example). Figure 6 shows that despite having a clear meaning and only one underlying concept for the term, we are using it in different ways in our application.

Figure 6. Banking and Payee Account classes
This might sound obvious to some, but it's not. When working on a class diagram, or a UML modeling tool you might really easily start modeling a Payee that has a bankingAccount attribute and think "I've already a class for that". The pavlovian attempt to get rid of code duplication might do more harm than good, sometimes.
A simple context map applied to the example used before might look as shown in Figure 7 below. Note that as long as our knowledge of the environment increases, that will reflect on the map. In this case we split the PFM application context into Banking and Expense Tracking.

Figure 7. A very simple Context Map: drawing contours around portions of domain model shows the areas where conceptual integrity is preserved
In this case the two contexts have some logical overlapping area: the concept of banking account is used in different ways in different portions of the application, meaning that we'll have different models in play. However, the two models are probably going to interact closely. Besides preserving conceptual integrity of the model within the context boundaries, the context map helps us focus on what's happening between the different contexts. In this case, assuming that the same team is working on both contexts, we need everybody in the team to be aware of the two different contexts, eventually sharing a translation map, for the terms and concepts that appear in both models.
Example 3: External systems
Let's consider again the PFM application. Many of these apps allow some type of data exchange with the financial institutions on-line services. In some cases, banks are providing real time access to home banking services, in some other cases they simply allow users to download bank statements in a common standard format (such as Money or Quicken format). However, from a context mapping perspective, the interactivity and the direction of the communication (one way or bi-directional) is not relevant. The one thing that does matter is that, once again, we'll have different models in play. Figure 8 shows the interaction of PFM Banking application with the On-line Banking Services application.

Figure 8. Interaction with an external application naturally calls for a separate bounded context in our Context Map
Even if the two models have been designed to represent the same data (at least to a given extent) they're different, they will be subject to different evolutionary forces over time, and they serve distinct purposes. Thus, separate bounded contexts are needed. Example 1 might also fall into this category, if user profiling is modeled using available third party libraries.
Managing multiple contexts
When our application spans multiple contexts, we need to manage also what happens in-between. The relationship between different bounded contexts often could provide very important insight about our project.
One of the most important things to know is the direction of the relationship between two contexts. DDD uses the terms upstream or downstream: an upstream context will influence the downstream counterpart while the opposite might not be true. This might apply to code (libraries depending on one another) but also on less technical factors such as schedule or responsiveness to external requests. In our example we have an external system that clearly won't change according to our requests, while our PFM Banking app will have to be updated quickly, in case the on-line banking services change their APIs for any reason. So our PFM context will be downstream, while On-Line Banking Services is clearly upstream. Figure 9 illustrates this relationship between the two domain contexts.

Figure 9. The upstream-downstream relationship between separate contexts
We can accept to update the way we communicate with the external system, on external demand, but we probably need some kind of protection against changes coming from the upstream context, and to preserve conceptual integrity of our Banking context. DDD describes several organizational patterns that help us describe and/or manage the way different contexts interact. The most suitable pattern here is called Anti-Corruption Layer (ACL), and calls for an explicit translation to happen at the code level between the two contexts, or better: on the external boundary of the banking context. This might not only be a technology translation, such as a Java to XML translation, but also a place where to manage all the subtle differences between the models on both ends. Drawing our ACL on the Context Map would produce something like the diagram shown in Figure 10 below.

Figure 10. Anti-Corruption Layer on the boundary of PFM Application, preventing the on-line banking services to leak into our bounded context
Not only external systems naturally call for a separate context. An existing legacy component, often has a model that cannot be easily evolved. Despite being maintained within our organization, even this model is subject to different forces and has been the result of a use which is different from our current one. If we have to interact with a legacy system, chances are high that this will be in a different bounded context.
What about the other relationships on the context map? Can we classify them according to the relational DDD patterns? Since we assumed that development was going on within a single team, the patterns are slightly less interesting here. However, if Banking and Expense tracking were to be maintained by different teams, they're likely to be in a partnership relation: they're both developed towards a common goal (and upstream-downstream doesn't make much sense since they're on the same level). If Web User Profiling is achieved with an external module, we're probably going to use it "as-is", meaning that we're downstream and Conformist, towards Web User Profiling.

Figure 11. Context map, after we sketched the relation patterns
Example 4: Scaling up the organization
So far, we considered a simple scenario with only one development team. This allowed us to ignore the cost of communication, assuming (maybe optimistically) that every developer in the team is aware of "what's going on with the model". A more complex scenario might include some of the following influencing factors:
- domain complexity (requiring many different domain experts)
- organization complexity
- longer projects (time)
- very big project (person days)
- many external, separate or legacy systems involved
- large team size or multiple development teams
- distributed or offshore teams
- human factor
Each one of these factors affects the way communication happens within the development teams and the organization in general, eventually shaping the resulting software.
A single team, especially in an Agile co-located environment, has many efficient ways to share information among team members: face-to-face conversations, joint design sessions, pair programming, meetings, information radiators and so on. Unfortunately, these techniques do not scale up so well when team size or number grows, making it hard to share conceptual integrity of the model across the borders of a single development team.
After all, agreeing on a model is a quite sophisticated form of communication, involving a common understanding of the problem and a similar view on the possible solution. In scenarios where communication is not that easy, doing becomes a lot cheaper than agreeing. A classical outcome of this communication bottleneck is the offspring of different classes in different places of the same code base, doing basically the same thing.
Let's suppose now our PFM application grew larger, and another team (Team B) has been assigned to work with us (we're obviously Team A) on a new trading module of the same application. Team B might be in a different room, building, city, company or country and is fully dedicated to the trading area. In the example below, Team A shares some of the code with Team B, even if they tend to work on separate portions of the code base. Eventually, team B writes some class (A in Figure 12 below) that implements functionalities needed by team B, that were already available in class A.

Figure 12. In a scenario where different teams are accessing the same code base, they might have different views on portions of the model. Physical distribution on the team will affect the quality of the information shared between the teams
That's code duplication, the root of all evil! In a single, well defined, bounded context, this is definitely true. But for some reason this does happen in almost every non trivial project. This is normally a sign that there are probably not-so-well-separated contexts in play, on the same area of the project. Sometimes, this would make two separated contexts a more efficient way to structure our domain model, than forcing two different teams to continuously integrate their vision.
So, how to we draw this on our map? A Context Map reflects our current level of understanding of the whole system, and will be updated as long as we learn something more, or the environment changes. Currently, we don't know exactly what's going on, and this is "our current level of understanding".

Figure 13. Our not-so-well separated Trading context, that would require further exploration or a sensible design decision
The caution sign in the diagram means that there’s something not right there: the two contexts partially overlap and their relationship is not clear. This is probably one of the first areas to resolve, trying to set up an agreed and sustainable relationship within the context, like Customer-Supplier, Continuous Integration or Shared Kernel. But that’s tomorrow’s job. A context map is a tool for today, and today the problem is still open, so we leave the caution sign in the diagram.
Don't be fooled by the colors and shadows: I tried to make the context map look good for printing. A real context map may look messy, at least as messy as your project is. But this caution sign here is telling us that there is a critical area where the contexts have not been clearly separated, and the whole stuff might easily turn into a Big Ball of Mud (the most resilient of the DDD organizational patterns), unless we do something about it.
An unconventional point of view
Context mapping forces us to include also non-software aspects into the whole picture, eventually spotting hot areas that a traditional architectural analysis would consider "out of scope".
For example, the way communication flows within an organization, largely affects the resulting software. In general, if on a small scale use is the primary factor that defines context boundaries, on a larger scale communication speed and project organization become the key factors. Tools like wikis, e-mail or instant messaging give us the fake idea of a team that's continuously in-sync with everybody's knowledge. But we all know this is just a dream: on a typical large scale project we're not part of a borg-like collective intelligence, some folks barely know what's going on outside their team.
Defining context boundaries in a large organization is a challenging but rewarding job. Many times, teams are not aware of the different contexts in play; violations of model's conceptual integrity happen because few or nobody see the whole picture. Drawing the context map is an investigation activity where many pieces of information might not be correct at first try, borders are initially blurred and several steps are required to get a clear snapshot of the overall picture.

{kind=link}
/filters:no_upscale()/articles/ddd-contextmapping/en/resources/ddd-contextmapping-figure2.jpg){kind=link}
/filters:no_upscale()/articles/ddd-contextmapping/en/resources/ddd-contextmapping-figure3.jpg){kind=link}
/filters:no_upscale()/articles/ddd-contextmapping/en/resources/ddd-contextmapping-figure4.jpg){kind=link}
/filters:no_upscale()/articles/ddd-contextmapping/en/resources/ddd-contextmapping-figure5.jpg){kind=link}
/filters:no_upscale()/articles/ddd-contextmapping/en/resources/ddd-contextmapping-figure6.jpg){kind=link}
/filters:no_upscale()/articles/ddd-contextmapping/en/resources/ddd-contextmapping-figure7.jpg){kind=link}
/filters:no_upscale()/articles/ddd-contextmapping/en/resources/ddd-contextmapping-figure8.jpg){kind=link}
/filters:no_upscale()/articles/ddd-contextmapping/en/resources/ddd-contextmapping-figure9.jpg){kind=link}
/filters:no_upscale()/articles/ddd-contextmapping/en/resources/ddd-contextmapping-figure10.jpg){kind=link}
/filters:no_upscale()/articles/ddd-contextmapping/en/resources/ddd-contextmapping-figure11.jpg){kind=link}
/filters:no_upscale()/articles/ddd-contextmapping/en/resources/ddd-contextmapping-figure12.jpg){kind=link}
/filters:no_upscale()/articles/ddd-contextmapping/en/resources/ddd-contextmapping-figure13.jpg){kind=link}
/filters:no_upscale()/articles/ddd-contextmapping/en/resources/ddd-contextmapping-figure14.jpg){kind=link}
Figure 14. Our last version of the map. Don't expect it to be "final", there's always something more to learn
There might be more contexts in play, for example trading is likely to be connected to some on-line stock pricing service, but that's a Trading problem! A context map is relevant about our surroundings, and we (Team A) are working on the Banking and Expense tracking areas of our application: we are interested only in contexts that we are directly connected to and that can affect our software.
As long as we gather more information, the map will become clearer. As mentioned before, simply acknowledging that there are different models in play within our application and that model integrity can be preserved only inside a well defined bounded context, provides a lot of value to our domain modeling perspective. Many models lose integrity as they grow, context mapping helps a lot in this sense.
About Strategic DDD Patterns
There's a subtle difference in the way we use patterns here: although the definition is the same - a proven solution to a recurring problem - these do seldom represent a solution we can choose. More often than not, organization structure will impose patterns and our only hope is to recognize them before embarking in a no-win situation. Sometimes we'll have the chance to choose the best option, or to change the existing situation, but we must be aware that changes at the organization level might require more time than our project scope will allow or simply they are beyond our possibilities.
If you're in doubt where to start from, start from the development teams. A team is probably the largest organizational unit that can efficiently share a vision on a model. Once recognized, multiple contexts might be managed by the same team, boiling down to a mostly architectural choice.
Every pattern has a different cost allocation: even if they solve similar problems (connecting contexts) they can't be easily swapped. For example Anti-Corruption Layer has a footprint on the code level (an extra layer) and very little footprint on the organization. While a Partnership, or a Customer-Supplier would probably require less code, and a single code base, but won't work without an efficient communication channel and a well defined process. Trying to set up a partnership without a collaborative environment, is clearly a dead end strategy.
Conclusions
It turns out that the original definition for a Context - "The setting in which a word or a statement appears that determines its meaning" - is quite precise, and scales up from design level to architectural and organizational level without losing precision or effectiveness. Despite some legitimate "desire of uniformity", models cannot be stretched indefinitely. Bounded Contexts provide well defined safe harbors, allowing models to grow in complexity without sacrificing conceptual integrity.
As a side effect, when applied on large scale projects, a Context Map shows also implicit boundaries that exist within organizations, providing a vivid, non photoshopped, snapshot of the stage upon which our project will strive. A good context map would give you a picture of the odds against you. You might actually know if the organization is - consciously or not - working against your project's success, even before the project starts.
As a consultant, I've found Context Mapping incredibly helpful to grasp quickly the key details of my customers' project landscape, and as a strategic decision support tool (that's what maps are for, anyway). A context map provides a holistic overview of the system that UML or architecture diagrams completely miss, helping us to focus on choices that are really viable in your scenario without wasting money in "large scale wishful thinking".
About the Author
Alberto Brandolini is an Information Technology consultant and trainer, with an all-round approach to software development. Founder and owner of Avanscoperta - a consulting and software development company based in Italy - he is also a promoter of the Italian communities about Domain Driven Design and Grails. You may follow Alberto’s thoughts on his English blog, Ziobrando’s Lair or on twitter.