Microsoft Research a récemment développé un nouveau modèle de détection d'attributs d'objet pour le codage d'images, qu'ils ont nommé VinVL (Visual features in Vision-Language).
Pour imiter les capacités humaines à comprendre les images qu'ils voient et à interpréter les sons qu'ils entendent, les chercheurs en intelligence artificielle (IA) tentent de permettre à un ordinateur d'avoir les mêmes compétences. Ces compétences peuvent être rendues possibles en fournissant aux ordinateurs un langage visuel pour comprendre efficacement le monde qui les entoure. Par exemple, les systèmes de langage visuel (VL) permettent de rechercher les images pertinentes pour une requête textuelle (ou vice versa) et de décrire le contenu d'une image en utilisant un langage naturel. Ces systèmes se composent de deux modules :
- Un module de codage d'image pour générer des cartes de caractéristiques d'une image d'entrée et
- Un module de fusion Vision-Langage mappant l'image codée et le texte en vecteurs dans le même espace sémantique afin que leur similitude sémantique puisse être calculée en utilisant la distance de leurs vecteurs.
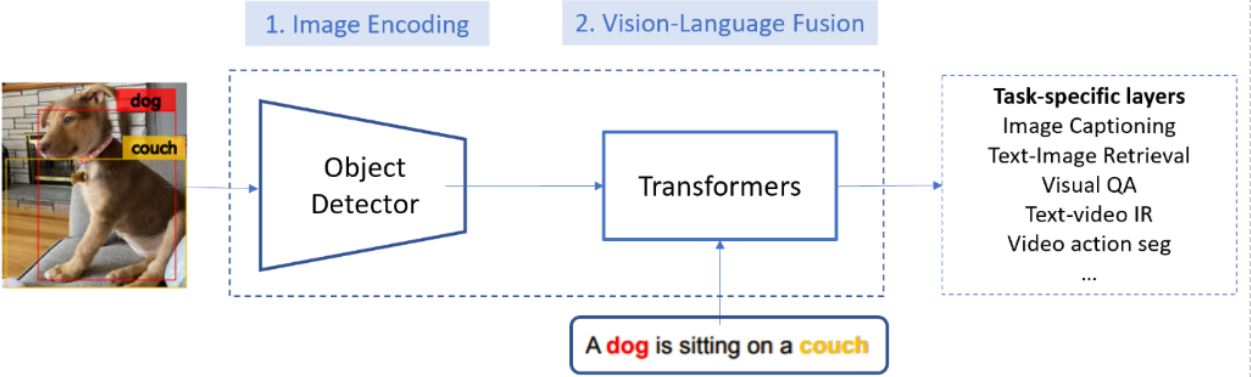
Les chercheurs de Microsoft ont travaillé sur l'amélioration du module d'encodage d'image en développant VinVL. En combinant des modules de fusion VL tels que OSCAR et VIVO avec VinVL, le système Microsoft VL établit un nouvel état de l'art sur les sept principaux benchmarks VL. Selon un article de blog de Microsoft Research , le système VL a atteint la première place dans les classements de VL les plus compétitifs, y compris Visual Question Answering (VQA), , et Novel Object Captioning (nocaps).De plus, le système Microsoft VL surpasse considérablement les performances humaines dans le classement des nocaps en termes de CIDEr (92,5 contre 85,3).Microsoft COCO Image Captioning
Microsoft a entraîné son modèle de détection d'attributs d'objet pour les tâches VL en utilisant un grand ensemble de données de détection d'objets contenant 2,49 millions d'images pour 1848 classes d'objets et 524 classes d'attributs et en fusionnant quatre ensembles de données de détection d'objets publics (COCO, Open Images, Objects365 et VG). Ils ont d'abord pré-entraîné un modèle de détection d'objet sur l'ensemble de données combiné - puis affiné le modèle avec une branche d'attribut supplémentaire sur VG, le rendant capable de détecter à la fois les objets et les attributs. En conséquence, le modèle peut détecter 1594 classes d'objets et 524 attributs visuels. De plus, selon le billet de blog, lors d'expériences menées par les chercheurs, le modèle peut détecter et encoder presque toutes les régions sémantiquement significatives dans une image d'entrée.
Dans le billet de blog, les auteurs déclarent :
Malgré les résultats prometteurs que nous avons obtenus, tels que le dépassement des performances humaines sur les repères de sous-titrage d'images, notre modèle n'atteint en aucun cas le niveau d'intelligence humaine de compréhension du langage visuel. Les directions intéressantes des travaux futurs incluent: (1) intensifier d'avantage le pré-apprentissage de la détection d'attributs d'objet en tirant parti de données massives de classification / marquage d'images, et (2) étendre les méthodes d'apprentissage de la représentation du langage visuel intermodal à la construction de modèles de langage fondés sur la perception qui peut ancrer les concepts visuels dans le langage naturel, et vice versa comme le font les humains.
Enfin, dans son blog de recherche, la société a annoncé qu'elle rendrait public le modèle VinVL et le code source. Plus de détails sont disponibles dans la publication de recherche et le code source dans un référentiel GitHub. De plus, Microsoft intégrera VinVL dans son offre de services cognitifs sur Azure.