Key takeaways
|
CQRS is the acronym that refers to a software architecture pattern and the concept that every software engineering specialist interested in Domain Driven Design will eventually come across. But what’s the idea behind it? Why in some situations can CQRS be a better alternative to a commonly practiced N-tier software architecture? How do these two patterns compare to each other? And more importantly, the thing that really matters in this case is, “what’s in it for business?” Let’s try to figure out how the CQRS application architecture can add value and pay off in big ways.
CQRS in the spotlight: What is the Bottom Line?
So what’s the crux of a CQRS-based application architecture? Let’s start by defining the concept.
Command Query Responsibility Segregation (CQRS) is an application architecture pattern that divides the application into two parts: the querying part (View model) and the commanding part (Write model). Each of them is responsible for processing a particular set of operations – read-type and write-type, respectively. The CQRS concept was first introduced and is actively promoted by Greg Young. It represents a natural extension of the CQS (Command–Query Separation) principle coined by Bertrand Meyers, who offered to separate methods into commands and queries. CQRS applies the same principle but to an entire system.
Owing to this architecture, two components of the business logic layer operate independently from each other. Therefore, the Read Model will handle user queries - less demanding from the point of view of processing power, whereas the Write Model will represent a long path of validation, queueing, messaging, and business rules processing that user commands will take.
The CQRS pattern is widely acclaimed by advocates of Domain Driven Design. The approach emphasizes solving business problems in the first place during the implementation of an application. It centers on thorough elaboration of a business domain and the context within which it will function. The possibility to focus on the business first rather than on the technical issues and work out all the nuances pertinent to a specific domain is achieved through the use of the Ubiquitous language – a single language understood by an implementation team, business analysts, domain experts and other parties involved. The language helps to share the effort among all team members – business and technical – who define and agree on the use of common business objects to describe the solution’s domain model and a certain context within such a model. These business objects are then utilized within the code itself.
Since a CQRS-based architecture allows separating the logic of two different types of tasks, it creates favorable conditions for writing code through the use of such explicit objects and amplifies the effect of the business-centered DDD-approach. A tech team focuses more on business rules and processes rather than on infrastructure or code conflicts inflicted by a different type of architecture. Thanks to that, CQRS and the Domain Driven Design approach often go together.
How Do CQRS and N-tier Architectures Stack Up against Each Other?
… or When Do You Have to Give a Closer Look at CQRS?
One of the most common architectures used on the web is a classic multitier architecture. In a simple version of it, an application is divided into three tiers: a user interface, business logic and a database layer. With this type of architecture, both queries (requests to read a system state/requests for some data to be displayed to them) and commands (requests to change a system state/write new data or make changes to it) are handled within the same business logic layer.
When is it Good to Go?
One will unlikely want to go hiking a long and tiresome path when all they actually need is the shortest and safest way to get from A to B. Similarly, if a web solution comes down to a relatively static brand web presence with little to no interactive input from users (let’s say a simple contact form), one will definitely not want to end up with an overly complex and costly system. However, as more business rules and interaction points are added to the application logic, the solution may not seem so trivial anymore.
For example, let’s get closer look at how it may work with a typical online store solution.
What happens when a user picks up a product they like and is ready to buy it (a.k.a what happens when we want to write a buy command into our eCommerce system); when the user presses the buy button, first the availability of the requested item is checked. If the system response confirms the availability of the amount needed, the user is invited to fill out the order form and provide shipping address, billing information, payment and other details to complete the purchase. Then they click the pay button, and the system runs all kind of validation procedures (shipping address validation, sales tax validation, billing address validation, credit card information validation, balance validation, etc). When the process is successfully complete, the user gets a confirmation message with their order details and further instructions, and appropriate changes are made to the system state (warehouse product availability update, a new buy order is registered, shipping details are sent to the warehouse team, etc).
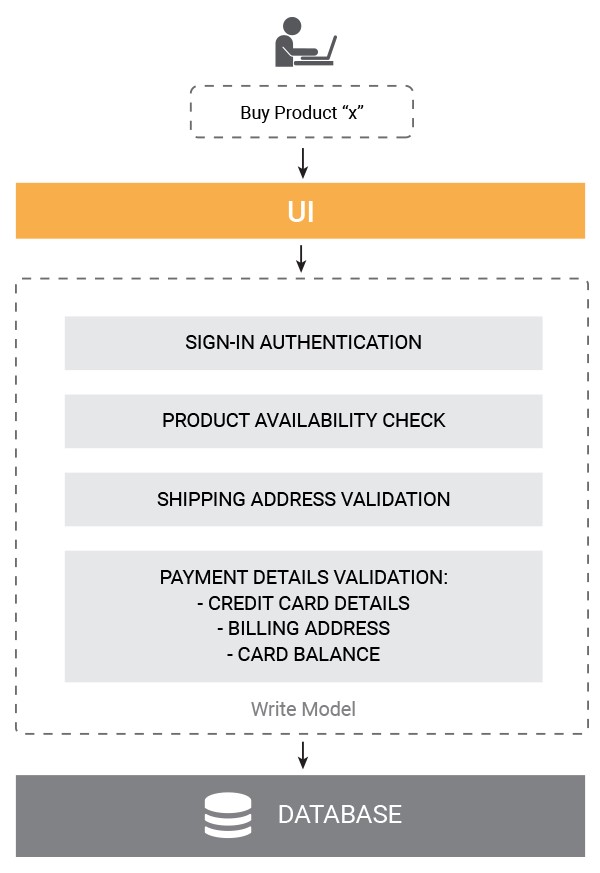
Now let’s see how else users can interact with the online store. What read requests can a user send to our eCommerce system? Visitors of our online store when exploring it can click on individual product items to see detailed description of their characteristics and take a closer look at the potential buys. In this case, visitors will send read requests for individual product pages to be displayed to them. Users can also search our store for particular items they are interested in purchasing or finding out more information about. For example, if the store specializes in selling mobile phones, some users can search for certain mobile device models when navigating our eCommerce solution. For such requests our system should return to the UI a search results page with the information matching the user query. Finally, some visitors will be likely to request catalogs of items grouped according to certain parameters like the device make and others, or search our store using filters matching their criteria (screen resolution, memory capacity, size, look and feel, etc.). In all these cases we’ll need to process incoming queries, search our solution database and generate a relevant UI view of the information requested by our online store visitors.
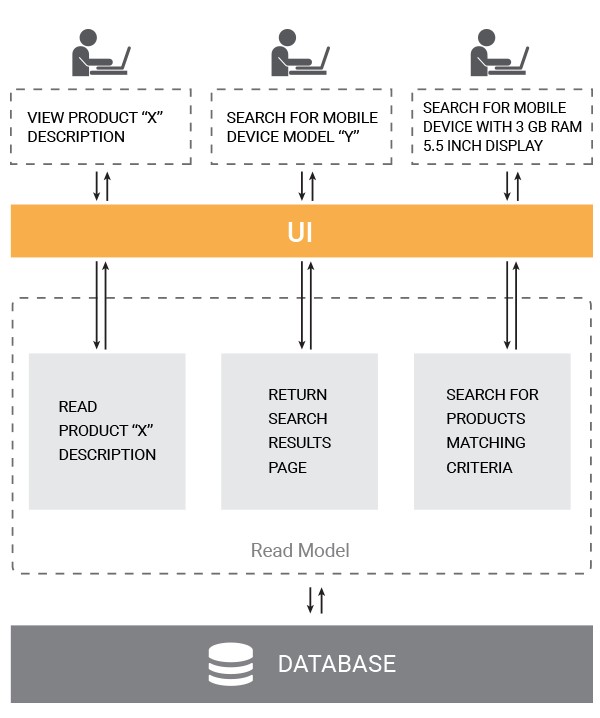
In a solution with an N-tier structure, an action of buying a product will follow the same path in the logic layer as user queries to have various items displayed on the UI. However, the buy command will entail product availability checks and various types of validation, whereas online store queries will trigger such processes as meta data search, filtering the information in the data store and compilation of relevant UI views.
As we can see, in a common N-tier architecture intrinsically different actions will get through the same application tier.
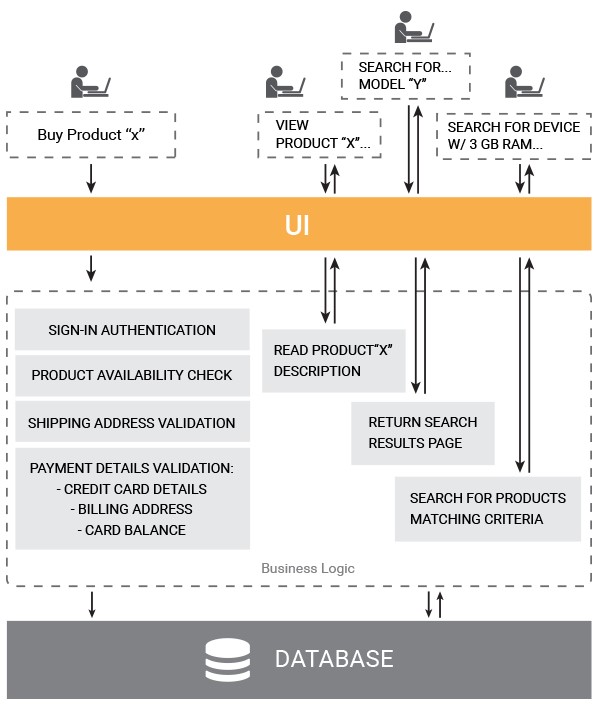
“But what’s wrong with that?” you’d ask.
This type of architecture works perfectly well for a company content with its current position within the industry. When the number of application users almost doesn’t change over time, when the amount of information processed remains relatively at the same level, when the application doesn’t experience heavy load periods or some atypical spikes of traffic, and when it operates within its defined capacity limits, the multitier application will hardly pose any problems. But how often do we have this situation in real life?
In real life some time after the launch of a solution – if the application gains traction – its performance will be put to the test. With the constantly growing number of users, more system resources will be required to maintain the same level of availability and failover standards.
At this point, a business owner will start thinking about boosting the performance of their existing system.
However, running both queries and commands through the same layer of business logic like in an N-tier application may put unnecessary strain on the system from the very beginning, especially when the number of requests is unbalanced and shifted towards a higher quantity of just one type of requests (usually simpler reads). Available resources are used up inefficiently in this case because a long path is chosen over a more reasonable shortcut.
Secondly, the N-tier architecture represents a more complicated approach to future advancements in a system. Whenever the workload increases disproportionally due to one type of operations (let’s say the number of queries grows), there is no way to scale the system in a targeted fashion. With the multitier option, a development team will have a hard time fine-tuning just a particular part of business logic responsible for processing a certain type of operations. Instead, the capacity of the entire application tier will have to be boosted to ensure that the performance is on par with user expectations. Scaling the entire system in this fashion can result in some operations taking a long path through the system, instead of the shortcut from point A to B. And that is again unproductive allocation of system resources.
That is exactly the case when CQRS may have advantage over the traditional N-tier architecture.
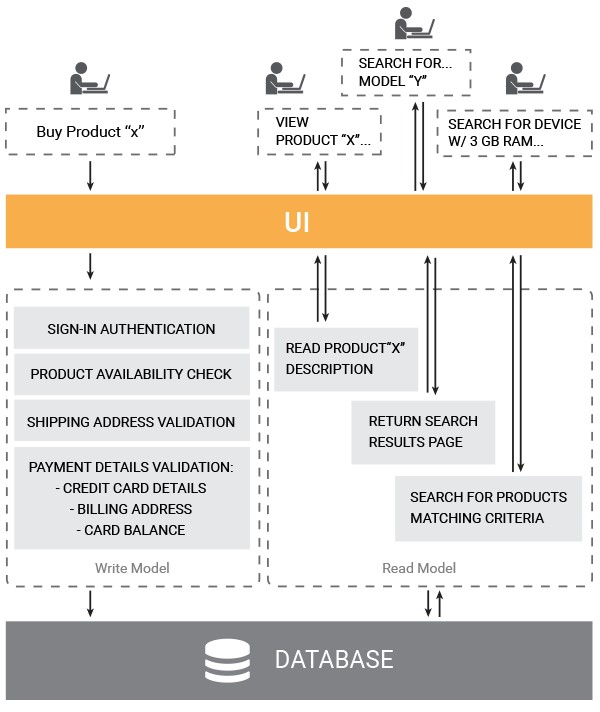
What makes CQRS a value-added architecture pattern?
All doubts about trading off the familiar and tried-and-true architecture for something seemingly more confusing and complicated are very reasonable. However, when setting to create an advanced web solution with complex collaborative contexts and quite a number of command types in the Write Model as well as with plans to provide quality online service to multiple concurrent users, try to weigh out carefully the bottlenecks of the N-tier application architecture described above – performance, scalability, efficiency – and consider the following benefits of a CQRS-based alternative:
- Business-driven development and communication, automated testing of code
Owing to dividing commanding and querying parts of an application, code syntax becomes simpler. There is less of a hodge-podge of two functionally different sides of software. The code clearly conveys the intent of specific actions within a certain business domain. The implementation of commands and queries expresses the corresponding business processes. Now the development team can switch from what seems to be tech gobbledygook for a client to a general business language as both technical and business teams can agree to use a single language – Ubiquitous language – to describe the business domain of the solution. The code itself becomes more legible for non-tech people and everyone engaged in the project can understand each other quite well. And since non-tech team members are now able to read the code, they can also be tasked with writing test case patterns to be used later to parse source code and automate a test case generation process. - Component-wise optimization, scalability and more efficient resource utilization
With a CQRS-based architecture, two components of the application tier do not intersect apart from communication at the database level. Consequently, as mentioned before, each of them can be optimized to perform as efficiently as possible a set of tasks that it has been designed for. The Read Model can be enhanced to ensure minimum response times and promptly deliver to a UI the information requested by a user by serving denormalized views from a Read database. In its turn, the Write Model can be optimized for reinforcing security and stressing the development of the business domain itself. Thanks to the segregation principle, the solution can also be scaled either way independently according to changing requirements of a business environment or increasing technical standards. Scalability issues are prioritized, and the most urgent points are addressed in short order without wasting system resources and being in over one’s head trying to ramp up the capacity of the entire business logic at once. - Sustainability and performance for high-load scenarios
When apps have quite complex business logic and experience a heavy load on just one part of the application tier, the CQRS pattern may prove to be a good technical solution. It will stave off the burden of running futile tasks in places where they shouldn’t run, or reduce “background code noise” in complex algorithmic areas as it gobbles up system performance. For instance, users are more lenient to longer response times with data input operations than with read requests. Each millisecond added to a query response time may result in thousands of dollars in lost opportunities. Taking into account the 3-second benchmark for a latency threshold, application responsiveness and its availability in the Read Model are critical. CQRS enables maximizing performance where it’s critical. - Flexible staffing options and less sensitivity to staff turnover
To isolate the Read and Write models of a software solution and make them rather autonomous means that the work on them can be separated painlessly, and go in parallel without the necessity to use common conventions for each part and harmonize these models. The Read Model development tasks can be assigned to junior-level specialists since such code can hardly cause severe errors. These activities can be even outsourced to an external team if you don’t have in-house capacity to cover everything through your own efforts. And you won’t be troubled by communication issues between your in-house specialists, developing the Write Model of the application, and the team occupied with the Read Model. On the other hand, the code itself is rather straightforward, which makes it a written knowledge base. A new team member can quickly grasp business rules by reading the code, which means that support of an existing solution in the future even with a completely new team will be much easier. - Open-ended tech stack options
CQRS provides a chance to avoid a tedious process of a rigorous technology stack selection. When an application serves targeted, semantically different areas independently, and consistency of these two areas with each other is not a prerequisite, the technologies for each of these areas can be, consequently, selected on an independent basis. There is no need to factor in extra interdependencies and search for a universal “one-size-fits-all” technology stack to meet the requirements of both the Read and the Write Models at the same time. Let’s take a transactional system with baked-in reporting tools. For the implementation of such a solution, a development team can pick up one set of technologies for the Write Model of the transaction processing part and another set for the Read Model of the reporting functionality. In this case the former will be fit for the purpose of writing transactions into the system, whereas the data structure and querying mechanisms of the latter will be optimized to better search the system and quickly serve views with the requested reports. - Lower total cost of ownership of a final application
Thanks to the flexible nature of this pattern and its segregated approach to processing operations within the application tier, CQRS is the solution that pays off in the long run. The benefits of a CQRS-based architecture may seem vague at the kick-off stage as it looks like the solution will require a more detailed elaboration of an application architecture and then will involve more actual coding. But the truth is that just like with any other well-established development practice that gathers a seasoned community of supporters as it evolves, CQRS also has an army of advocates and contributors. One can find plenty of re-usable assets and artifacts to build upon that will help a tech team propel development efforts. There is a useful hoard of CQRS frameworks and documentation available online that can be taken advantage of. Having invested into the CQRS implementation, a company gets more flexibility in the future and saves on maintenance, support and scalability later on.
Any Reasons for Final “No, No, No” Reply to the CQRS Implementation?
Is it all rainbows and unicorns then? Is CQRS a silver bullet for any software development endeavor? Certainly not! While this pattern can be particularly fit for some tech-driven business solutions, it will be totally unadvisable in other situations. So, when is the CQRS pattern not the best option? When applied to an entire software system from top to bottom.
Any attempts to design an advanced application without a modular structure and apply the CQRS pattern to an entire system will have all the chances to result in piles of twisted mazelike code, and rather an eccentric structure. First, a solution architecture is divided into smaller units (bounded contexts), and only after that, some or all of them separately are optimized using CQRS.
Bounded context is the term that was originally coined for the use with Domain Driven Design. Simply put, bounded contexts are created within a certain business domain and correspond to logically consistent parts of a domain. In a software system, these are smaller components that are pertinent to a certain area of responsibilities and usually serve the needs of a particular department (or of a business unit within this department with well-defined responsibility limits). The responsibilities of each context do not overlap. For example, if you have a workflow management system used by the entire organization, there will most likely be an IT context, Accounting context, Sales context, Customer Support context, etc. These contexts will have their clear boundaries, but will share some of the concepts like Clients for Sales and Accounting contexts. Therefore, CQRS is a wise choice when used within complex systems and applied to certain modules that correspond to such bounded contexts within a business domain.
Summary
All of the above listed benefits and limitations of the CQRS pattern lead to a conclusion that after assessing a CQRS-based implementation with due consideration and seeing it from a few-step-ahead perspective, it may turn out to have a lower total cost of ownership despite higher time, resources and budget input at the very beginning. Do give it a closer look – the game CAN BE WORTH the candle.
About the Author
Andrei Kaminski is a .NET developer on Softeq’s enterprise web development team and a certified Microsoft professional focusing on finding solutions to complex business problems through elegant application architecture and with the help of the best of what technology world can offer. Kaminski has years of hands-on practice developing corporate web applications, including BPM, operational intelligence and business process automation solutions. CQRS bundled with Event sourcing is the #1 application implementation option on the list of his professional interests.