Key Takeaways
- Advances in state-of-the-art AI systems require annotated data in vast quantities.
- It becomes imperative that, along with algorithms, there should be a way of utilizing the data available at various entities without compromising the security aspects.
- Collaborative learning can be the answer to data security and data-sharing issues, where we can share learnings without sharing data.
- Institutional Incremental Learning can facilitate collaborative machine learning while prompting flexibility.
- Building a state-of-the-art AI system with current tools and techniques is possible using collaborative learning while addressing data security and safety concerns
Introduction: Importance of Collaborative Learning and Data Sharing
In recent years, there has been remarkable development in Artificial Intelligence. Availability of computing power and graphical processing units has made it possible for it to reach out to the masses.
Building an AI system has always been a challenging task. While organizations today are looking to adopt AI, they often need to decide whether investing in an AI initiative is the right thing to do.
This usually leads to a situation where we desire to build an experimental AI system around the needs of the organization and we can evaluate it before undergoing higher investment. Here, a system should be “implementation” centric. We can achieve this by utilizing available tools and frameworks fostering the rapid development of a prototype.
This is a challenging situation because building an AI system requires addressing the following aspects:
- Data Collection / Annotation - The first important consideration is how to source annotated data to train a machine learning model. This also requires that data is not compromised. Anonymising data is an alternative but requires considerable effort.
- Training a model with a suitable algorithm. - Getting the right algorithm to train the model.
- Share the model with participating partners. - This solves the data sharing issue as we share the model and not the data.
- Making models available to users for feedback. - After training a model, there needs to be a mechanism where users can evaluate and have a feel for the model. In short, having the ability to evaluate a model.
- Reuse - use the previously trained model to foster rapid learning.
To address the above challenges, collaborative machine learning can be of great use. In this article, I am going to talk about how to use collaborative machine learning in a scenario where data sharing is difficult and yet it is possible to build better models by using model sharing and Institutional Incremental Learning.
The keyword here is model sharing and not data sharing. The focus of this exercise is to use the resources in the most optimized way to build a deep learning model system fast enough. This also requires that security issues around data are addressed.
In a collaborative learning scenario, collaboration can happen in the following ways:
- Multiple actors/ institutions train a model based on the private data available and pass the trained parameters to a central server. We know this as Federated Learning.
- Multiple actors/ institutions train the model incrementally and pass the model to the next actor. This can happen iteratively. This is institutional incremental learning.
What is Institutional Incremental Learning?
This is a way to collaborate in model training. Train a machine learning (or deep learning) model across multiple devices/ servers called Nodes. Following are the key features:
- The nodes have their version of local data samples.
- Instead of data going to one server, the algorithm is available to the node.
- Addresses data privacy, security issues.
- The participants can publish their models for the ecosystem.
- Applies to multiple domains, including defense, telecommunications, IoT, pharmaceuticals, and medical.
Institutional Incremental Learning is one of the promising ways of addressing data-sharing concerns. Using this approach, organizations can train the model in a secure environment and can share the model without having to share precious data.
Institutional Incremental Learning differs from federated learning. In federated learning, all the participants do the training simultaneously. This is challenging, as the centralized server needs to update and maintain models. This results in complex technology and communication requirements.

Fig 1: Flow of institutional incremental learning
Having understood about Incremental Institutional Learning, let us achieve this in practice. A project (available on Github) can serve this purpose. Data used is a public dataset that provides information on Chest X-rays. We address this problem by using deep learning object detection techniques called segmentation. The architecture chosen here is UNET with resnet34 as a backbone.
A pre-trained model is available which can diagnose problems in a chest X-ray. For local training, we can use this model as a pre-trained model. What we are doing here is important, which is known as incremental learning uses a well-known concept of transfer learning. This is the feature that allows us to get better models.
After the training process, we get a model which might be shared with other participants. If the model is good enough to be used, it is shared otherwise, we suggest more training. What is important to note here is that the data does not have to leave its premises. We share a model, which is a bunch of parameters that takes an image as an input and outputs the result using a technique called “Forward Propagation”. It can not be used to construct those images which helped it to train. This is a kind of irreversible process. The model knows only what it needs to know to come up with a prediction.
After training a model locally, the model, along with the metrics, is shared with participating entities. In this way, the decision to use a particular model lies with the organization, which is going to use them and not be forced by anyone. This truly enables decentralized machine learning, where a model is not only trained but also used at the user's discretion.
Incremental institutional learning helps to address catastrophic forgetting. This is because when we train a model with new data, the training does not start from scratch; it starts from a point when the last collaborator has completed the training process. The next collaborator then asks the training process to use a previously available model as a starting point for the next training iteration. In this fashion, the neural network learns from the new information, but this does not disrupt it.
Above process can help address catastrophic learning in a way. When a model is trained locally before it is used, it will see the data one more time. Even if the previous training iterations have made the mode to forget this, the last pass should ensure that this is retained where it is required. So, this is a good idea to train a model one last time locally to prevent catastrophic forgetting.
Now let us understand various parts of this process. Here, I am presenting a demo of this process through a project that uses Institutional Incremental Learning. The focus of this project is to use these concepts in a way that can help address the data sharing issues in the most efficient manner. Details are available in the next section.
The Use Case
To build a system that can detect pneumonia in Chest X-rays. The dataset used here is BIMCV COVID-19+, which provides information on the condition of an X-ray and also the location of this condition.
This is supported by an interface, as it is one thing to have some metrics to support the data, but having a way to look at the results and get a feel of that is entirely a different proposition. A deep learning model can be ‘seen’ or ‘felt’ by having a user interface. My project addresses this by providing a script that can make predictions.
Technically, we are looking for a rectangular area within the X-ray called the bounding box and associated condition. The dataset provided here is annotated with bounding boxes. These bounding boxes represent the area that shows pneumonic conditions. Another way of representing this information is through semantic segmentation. Since the data providers have provided the information using bounding boxes, the model should also return the diagnosis through bounding boxes.
Object Detection
The above problem falls under the umbrella of Computer Vision, where further it can be sub-classified as object detection. Object detection is becoming a sought-after field because of its applicability in various domains. Some popular methods/ algorithms used for object detection are R - CNN, Faster R - CNN, Single Shot Detector, and YOLO.
An object detection algorithm is complex because it has got two tasks to solve, what and where. A model typically has one task to solve, like classification or regression, but in an object detection scenario, it is to predict what the condition is and wherein the image, this condition, is present. Typically, this is accomplished by predicting a bounding box and associated conditions with that bounding box.
There is another way of doing bounding box detection, which is using segmentation. Bounding box methods are quite popular, but they seem to not do well with smaller objects. In this implementation, object detection using segmentation is employed.
Architecture/Libraries used
U-Net - U-Net is a convolutional neural network that was developed for biomedical image segmentation. A U-shaped architecture comprises a specific encoder-decoder scheme: The encoder reduces the spatial dimensions in every layer and increases the channels. The decoder increases the spatial dimensions while reducing the channels. U-Net is popular in biomedical image segmentation.
Resnet34 - Resnets or Residual Neural Networks are convolutional neural networks that use skip connections for residual learning. Deep Residual Learning is found to have worked better to learn networks of deep architecture.
fastai is a deep learning library that provides practitioners with high-level components that can quickly and easily provide state-of-the-art results in standard deep learning domains and provides researchers with low-level components that can be mixed and matched to build new approaches. It aims to do both things without substantial compromises in ease of use, flexibility, or performance.
scikit-image - or skimage is a collection of algorithms for image processing and computer vision. A model based on U-Net architecture outputs results in pixel form. Skimage helps in converting the pixel information into bounding boxes.
Method:
The project has two main modules, train.py, and inference.py.
Data Collection: We train the segmentation model on the BIMCV COVID-19+ dataset. The data is available in DICOM format and comma-separated files, which contain bounding box and label information.
Data Preprocessing: Since the segmentation model requires data in a specific format, images are extracted from DICOM format and create masked images with the bounding box and condition information available.
Model Training - A generic script is available which uses the fastai framework built over PyTorch. This offers various parameters like learning rate, the number of epochs, use model, training dir, mode (full or partial). The “use model” parameter supports the incremental learning part. When invoking the training script, one can supply a model reference (path) which the training script loads before the start of training.
So the learning from previous training iterations is retained (addresses catastrophic learning). By default, we provide a model which can be used. This model uses the transfer learning approach, using a pre-trained resnet34 model.
In this way, best AI practices are being taken care of. Once a collaborator trains a model and makes the model available to other parties, they can use the model to make predictions or for training.
Making predictions - Once a trained model is available, we can use it for making predictions with the help of script “inference.py”. This is a pretty involved process where the following things happen:
- Load the model into memory.
- Load the image into memory for prediction/ inference.
- The model processes the image, returning a masked image.
- Resizing of the masked image.
- Probabilities and bounding boxes related to them are obtained from the masked image.
- Probabilities and corresponding bounding boxes are drawn over the image.
- Saving the predicted image in the output directory.
In this step, the generation of original images with annotated data is also carried out if bounding box information is available. This is useful in those cases where the end-user has information on the image and (s)he wants to see how the model has performed.
Output:
Below is an example of the output generated on an image. Along with bounding boxes, it also provides information on labels.

Fig 2: An image for making predictions
Above image shows that the condition associated with the image has got a ‘typical’ type of Pneumonia along with the location. The dataset provides information through four labels: ‘normal’, ‘typical’, ‘atypical’ and ‘indeterminate’.
Determination of label and associated bounding box coordinates requires an intermediate step. The trained model provides information pixel by pixel, which is then converted into bounding boxes using skimage. Below is an example of the same. The left image contains original bounding boxes, and the right one contains the information as pixels.
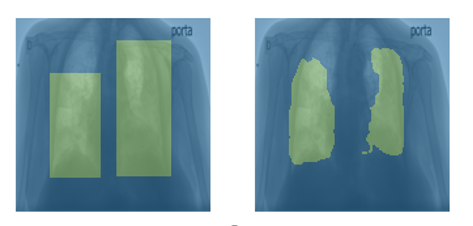
Fig 3: Model provides the output per pixel-wise, this is then converted into bounding boxes with help of the skimage library.
Original information: The inference script generates an image with labels and bounding boxes printed when ground truth information is available.

Fig 4: Image with original information
Applicability:
This application supports Institutional Incremental Learning by sharing only the model. Once a collaborator trains and shares a model with collaborators, there is no need for sharing of data. With the model, information is shared with the collaborators, which allows to get the label information associated with an image. Thus ensuring that learning is kept. Another advantage here is that anyone does not force a collaborator to use a particular model. They have the flexibility to
- Train their model with data available to them on a default model.
- Load a model provided by other users and draw conclusions.
- Load a model provided by other users and fine-tune that with their dataset.
This is especially helpful in Medical Domain where segmentation models have been useful and this approach has the potential to address data privacy issues.
Benefits of incremental learning:
We observe various benefits from institutional incremental learning, such as:
- Addressing data security issues.
- Achieving collaboration without sharing data. Getting better models without having access to all the data.
- Easy to implement. This approach is easier to follow as compared to another approach called Federated Learning.
- Flexibility to choose the model. Here, the participants are not restricted to use a particular model, they can choose the model of their choice.
This approach is simple to implement as compared to federated learning systems because there is a complex technological requirement where the central server plays the role of an umpire and ensures keeps the model up to date with updates from participating nodes. This introduces complex engineering challenges.
So, we can see that it is not so difficult to build an object detection system and make it available to the users while addressing data-sharing issues using Institutional Incremental Learning. The project available is ready to use and supports institutional incremental learning. With the help of the fastai library, we can easily develop models supporting other architectures like resnet50.
Institutional Incremental learning can be very effective, especially in the medical domain. This framework can support use cases which are:
- Brain tumor detection
- Pneumonia detection in Chest X-rays
- Abdomen scans