Key Takeaways
- The Goldman Sachs Core Front Office Platform team run an on-premise Apache Kafka cluster on a virtualised on-premise infrastructure that handles ~1.5 Tb a week of traffic
- The team has invested significant resources into preventing data loss, and with data centers in the same (or very close) metro area, the multiple centers can effectively be treated as a single redundant data center for disaster recovery and business continuity (DRBC) purposes
- The Core Front Office Platform team have invested significantly in creating tooling to support their infrastructure, including a REST service to provide insight into the Kafka cluster, and the creation of a comprehensive metrics capture component
- Failure will occur, and engineers must plan to handle this. The approach that has been adopted at GS is to run everything with high-availability, and be transparent in all of the trade-offs made
At QCon New York 2017, Anton Gorshkov presented “When Streams Fail: Kafka Off the Shore”. He shared insight into how a platform team at a large financial institution designs and operates shared internal messaging clusters like Apache Kafka, and also they plan for and resolve the inevitable failures that occur.
Gorshkov, managing director at Goldman Sachs, began by introducing Goldman Sachs and discussing the stream-processing workloads his division manages. The company’s Investment Management Division has $1.4 trillion in assets under management, and the Core Platform team interfaces with many other internal teams to provide platforms and infrastructure to run Apache Kafka, Data Fabric, and Akka. The team operates an on-premise Apache Kafka cluster running on virtualized infrastructure that handles ~1.5 TB a week of traffic, and although the message count is relatively low — in the order of millions per week — at peak periods, Kafka can see about 1,500 messages produced per second.
The deployment goals of the Apache Kafka cluster are:
- no data loss, even in the event of a data-center outage;
- no notion of primary/backup;
- no failover scenarios; and
- to minimize outage time.
The team has invested significant resources into preventing fundamental data loss, and this includes providing tape backup, nightly batch replication, asynchronous replication, and synchronous replication (e.g., synchronous disk-level replication with Symmetrix Remote Data Facility). Gorshkov reminded the audience of latency numbers that every programmer should know, and stated that the speed of light dictates that a best-case network round trip from New York City to San Francisco takes ~60ms, Virginia to Ohio takes ~12ms, and New York City to New Jersey takes ~4ms. With data centers in the same metro area or otherwise close, multiple centers can effectively be treated as a single redundant data center for disaster recovery and business continuity. This is much the same approach as taken by modern cloud vendors like AWS, with infrastructure being divided into geographic regions, and regions being further divided into availability zones.
Allowing multiple data centers to be treated as one leads to an Apache Kafka cluster deployment strategy as shown on the diagram below, with a single conceptual cluster that spans multiple physical data centers.
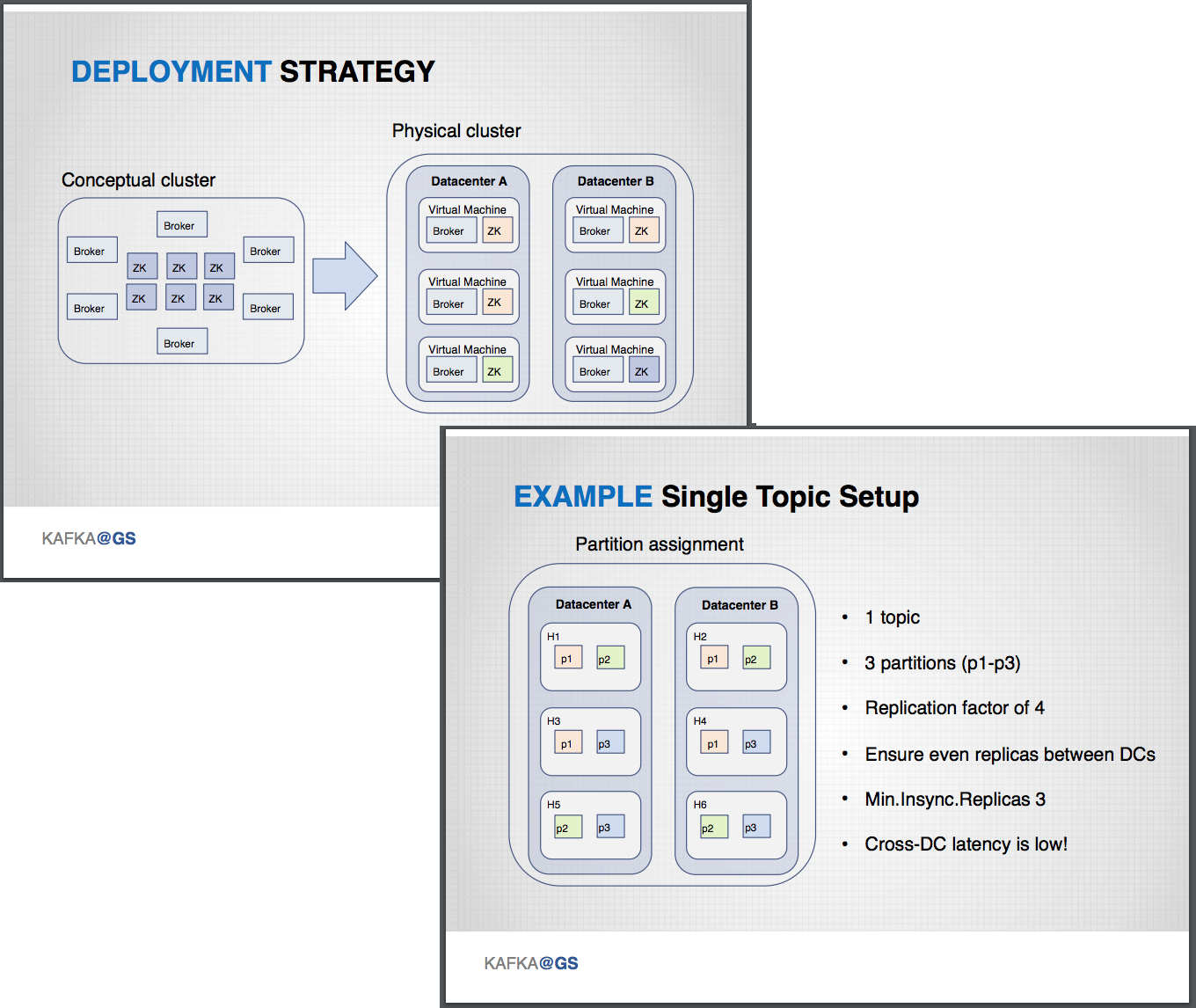
Gorshkov ran through a series of failure scenarios, starting with an exploration of what happens if a single virtual-machine (VM) host fails within a data center. This generally happens one to five times a year yet has no impact on Kafka producers or consumers, as the system is still able to satisfy the minimum required synchronization of at least three replicas. In this case, there is no manual recovery, beyond replacing the host. The occurrence of two hosts failing simultaneously occurs once a year or potentially more often if there is an underlying infrastructure or hypervisor failure. If this failure mode occurs, the processing for some Kafka topics will halt. The short-term fix is to add replicas for the affected partitions, and ultimately to replace the bad hosts. The Goldman Sachs compute infrastructure allows seamless VM replacement with no need to update DNS aliases or change Kafka configuration.
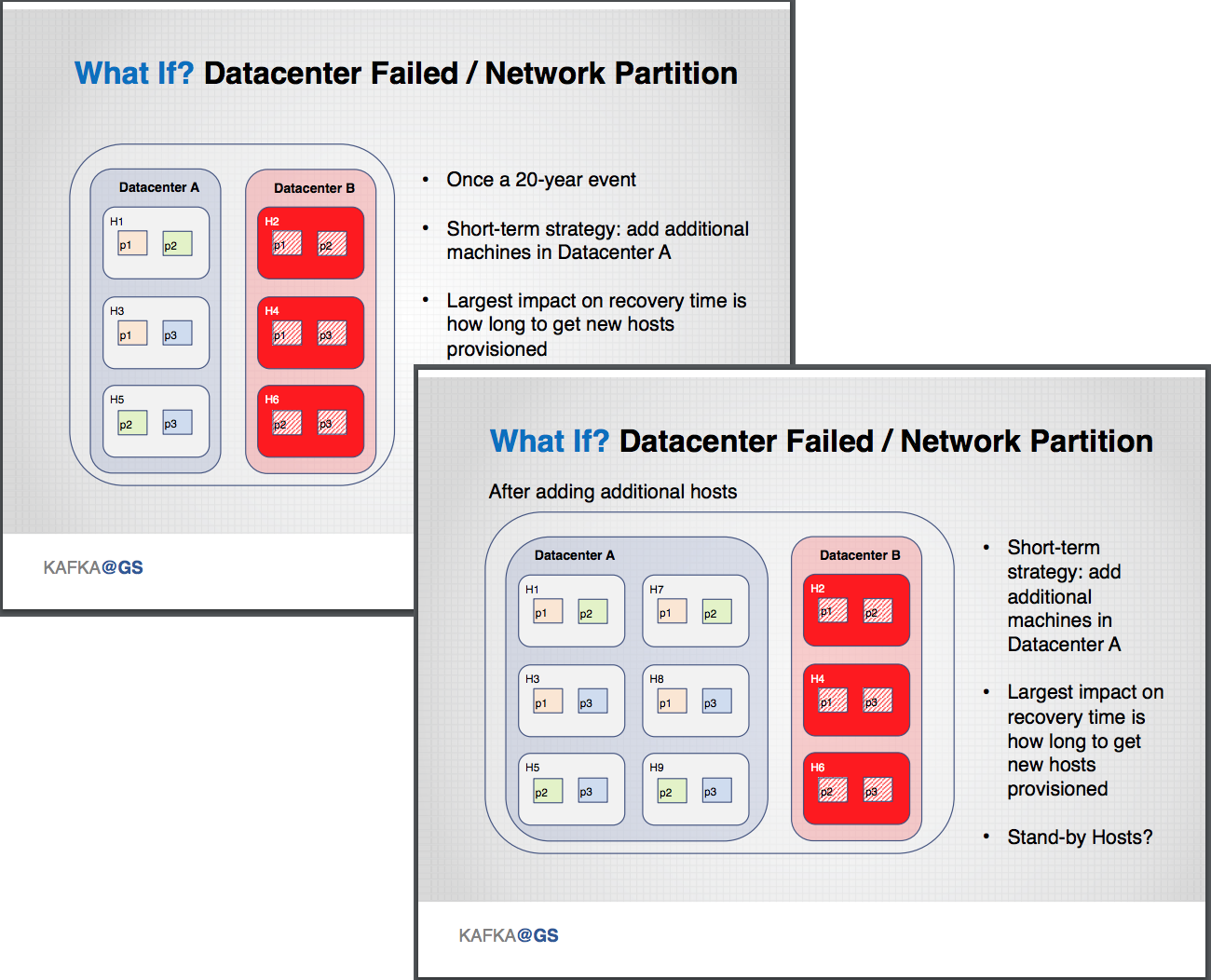
If three hosts within a data center fail then cluster processing immediately halts as this configuration can no longer satisfy the required number of in-sync replicas across the cluster. Fortunately, this only occurs once every few years. The fix is to replace the host as soon as possible. If a data center fails or a network partition occurs — which Gorshkov estimates is a “once a 20-year event” — then the short-term solution is to add additional hosts in the data center that is not affected. The largest impact on recovery time is how long it takes to provision new hosts, as data centers typically maintain spare capacity.
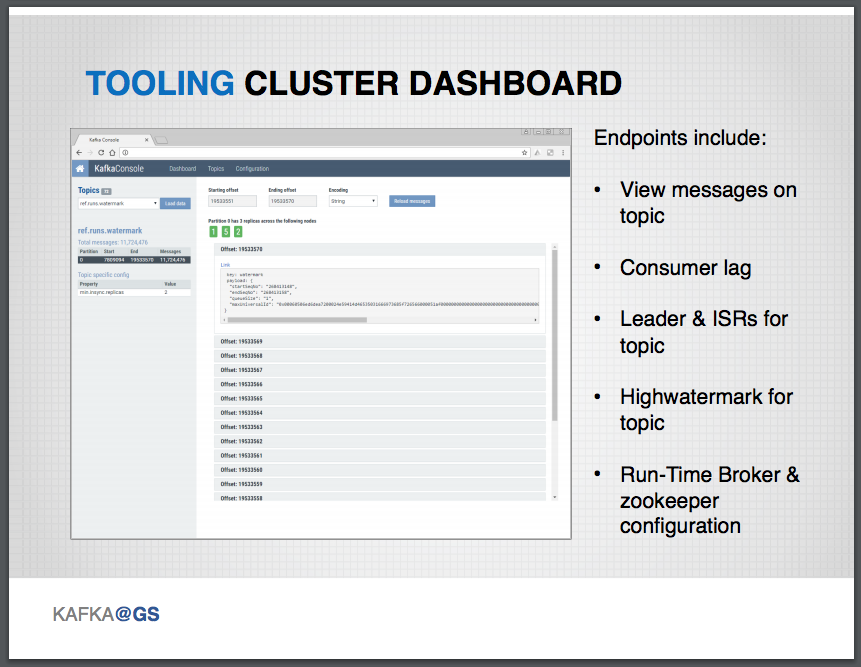
The Core Platform team has invested significantly in creating tooling to support their infrastructure, including a REST-like service and associated web application to provide insight into the Kafka cluster. The REST endpoints allow messages to be viewed on all topics, and core metrics like consumer lag and the number of in-sync replicas to be obtained. It is also possible to obtain information on ZooKeeper configuration, the process of leader election, and run-time broker metrics. The platform team has also created a component that records a multitude of metrics from the operation of the cluster at the application, JVM, and infrastructure levels. Metrics are sent to a time-series database and are forwarded to a centrally managed Goldman Sachs alerting instructure. From here, alerts can be issued to on-call engineers.
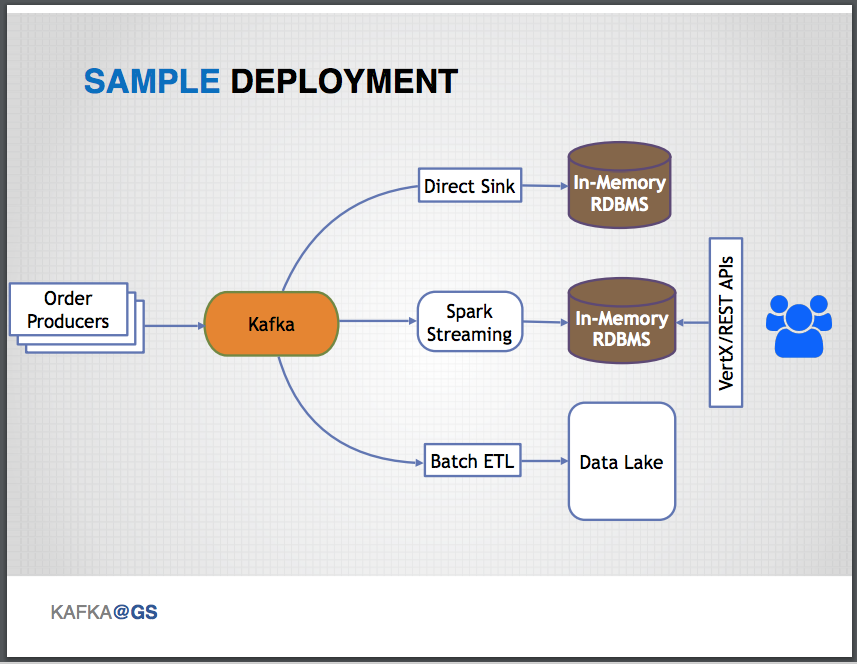
A typical sample deployment includes an upstream service — e.g., a trade-orders service — acting as a message source and sending events based on an internal state change (which is also captured in a data store local to the service) to the Apache Kafka cluster. The Kafka Connect API is used to connect message sinks to the Kafka cluster, and downstream targets typically include a direct sink to an in-memory RDBMS that maintains a tabular version of all messages for troubleshooting purposes, a Spark Streaming job that outputs results to an in-memory RDBMS that is queried by end users via the associated Vert.x or REST APIs, and a batch ETL job that persists all events to a data lake for audit/governance purposes.
If a significant outage does occur and messages need to be resent, then the globally unique identifier that is added to every message by the upstream service makes this relatively easy to replay without processing duplicate messages or breaking idempotency guarantees. If the upstream system did not generate unique identifiers, then Gorshkov recommends exploring the new exactly-once processing semantics introduced to Apache Kafka by the Confluent team, and also researching into Kafka Improvement Proposal (KIP) “KIP-98 - Exactly Once Delivery and Transactional Messaging”.
In the final section of the talk, Gorshkov stated that failure will always occur and that engineers must plan to handle this. The approach that his team has adopted is “belt and suspenders” for everything. Ultimately, a lot of the tradeoffs that are encountered for setting up resilient systems involves throughput versus reliability (versus cost). Apache Kafka has many configuration options — perhaps too many — and it can be best to hide some of the knobs from end users. For more details on configuring Kafka to run effectively, Gorshkov recommended the Confluent online talk series, “Best Practices for Apache Kafka in Production” by Gwen Shapira. He concluded the talk by stating the resilience must be implemented using a transparent approach, as this is the only way engineers will gain confidence in the system.
The video from Gorshkov’s QCon NY talk “When Streams Fail: Kafka Off the Shore” can be found on InfoQ.
About the Author
 Daniel Bryant is leading change within organisations and technology. His current work includes enabling agility within organisations by introducing better requirement gathering and planning techniques, focusing on the relevance of architecture within agile development, and facilitating continuous integration/delivery. Daniel’s current technical expertise focuses on ‘DevOps’ tooling, cloud/container platforms and microservice implementations. He is also a leader within the London Java Community (LJC), contributes to several open source projects, writes for well-known technical websites such as InfoQ, DZone and Voxxed, and regularly presents at international conferences such as QCon, JavaOne and Devoxx.
Daniel Bryant is leading change within organisations and technology. His current work includes enabling agility within organisations by introducing better requirement gathering and planning techniques, focusing on the relevance of architecture within agile development, and facilitating continuous integration/delivery. Daniel’s current technical expertise focuses on ‘DevOps’ tooling, cloud/container platforms and microservice implementations. He is also a leader within the London Java Community (LJC), contributes to several open source projects, writes for well-known technical websites such as InfoQ, DZone and Voxxed, and regularly presents at international conferences such as QCon, JavaOne and Devoxx.