YahooがTensorFlowOnSparkをオープンソース化した。データサイエンティストやエンジニアは、SparkやHadoopを動かしているCPU/GPUアーキテクチャ上で、分散トレーニングとモデル提供を行うことができる。彼らの報告によると、このライブラリを使うことで、既存のTensorFlowプログラムを新しいAPIにポーティングすることができ、トレーニングとモデル提供のパフォーマンスが改善されるという。
Yahooはその発表で、TensorFlowOnSparkを開発した動機について、ディープニューラルネットワークをトレーニングするためにSparkデータパイプラインの外部に追加のクラスターを管理することの運用オーバーヘッド、トレーニングクラスター内外のネットワークI/Oバウンドなデータセット転送、望ましくないシステムの複雑さ、全体的なエンドツーエンドの学習レイテンシなどを挙げた。TensorFlowOnSparkの取り組みは、それに先立ってYahooがはじめたCaffeOnSparkの取り組みと似ている。TensorFlowとSparkのインテグレーションという課題に対して、DataBricksのTensorFrameやAmp LabのSparkNetといった取り組みがある。Yahooによると、これらは正しい方向に進んでいるが、TensorFlowプロセスが相互に直接コミュニケーションするには不十分だという。Yahooの目標のひとつは、Spark処理パイプライン内に統合できるという点で、SparkSQLやMLib、その他コアSparkライブラリと同様に機能するよう、TensorFlowOnSparkを完全にSpark互換のAPIにすることだ。
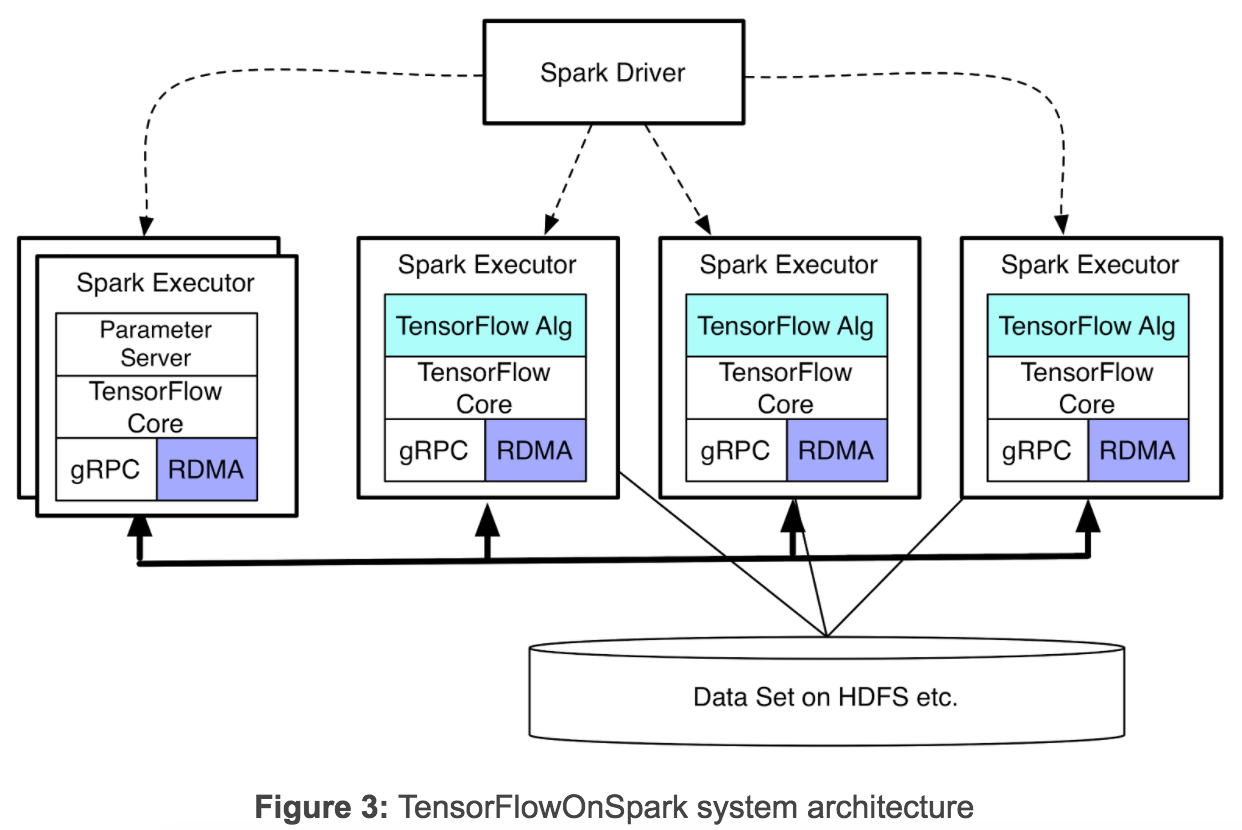
このアーキテクチャでは、与えられたTensorFlowアルゴリズムとTensorFlowコアをSpark Executor内に配置し、TensorFlowのFile ReaderとQueueRunner経由でHDFSデータに直接アクセスできるTensorFlowジョブを提供し、ネットワークI/Oの削減と「計算をデータにする」アプローチを実現している。TensorFlowOnSparkは、executorのポート予約/リスニングのためのセマンティックス、データおよび制御関数のメッセージポーリング、TensorFlowのメインファンクション起動、データ取り込み、HDFSから直接読み込むためのReaderとQueueRunnerの仕組み、feed_dictによるTensorFlowへのSpark RDDフィード、シャットダウンをサポートする。
{kind=link}
TensorFlowOnSparkに加えて、Yahooは独自のforkでコアのTensorFlow C++エンジンを拡張し、Infiniband上でRDMAを実現している。これはメインのTensorFlowプロジェクトで要求され、議論を生んでいる機能だ。YahooのAndy Feng氏は、gRPCベースのプロセス間通信上でRDMAを使うことで、様々なネットワークにおけるトレーニング速度が10から200%改善されたと述べている。
Rate this Article
- Editor Review
- Chief Editor Action