Amazon Web Services (AWS) は先頃、UltraClusters機能を備えたElastic Compute Cloud (EC2) P4dインスタンスが利用可能になったことを発表した。これらのGPUを利用したインスタンスは、前世代のP3インスタンスよりも高速なパフォーマンス、低コスト、機械学習 (ML) トレーニングおよびハイパフォーマンスコンピューティング (HPC) 用のGPUメモリを提供する。
新しいP4dインスタンスには、8つのNVIDIA A100 Tensor Core GPUと400Gbpsのネットワーク帯域幅がある。これらのGPUは、単一インスタンスで最大2.5ペタフロップスの混合精度パフォーマンスと320GBの高帯域幅GPUメモリに対応している。マルチノード分散ワークロード全体のスケーリングのボトルネックを解消するために、AWSはNVIDIA GPUDirect RDMAネットワークインターフェイスを利用して、サーバ間でGPU間の直接通信を行った。これにより、レイテンシが低くなり、スケーリング効率が高くなる。96個のIntel Xeon Scalable vCPU、1.1TBのシステムメモリ、および各P4dインスタンスの8TBのローカルNVMeストレージはすべて、単一ノードのMLトレーニング時間を短縮するのに役立つ。
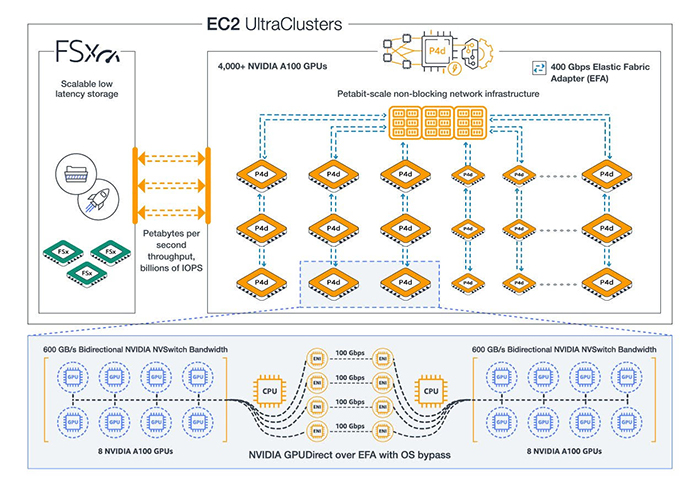
AWSは、データサイエンティストやエンジニアが、多くの一般的なMLタスクでサイズが拡大し続けるデータセットを持つ、より大きく複雑なMLモデルを作成できるように、パフォーマンスが3倍速く、コストが60%低く、GPUメモリが2.5倍多いことを約束している。自動運転車のビジョン、自然言語処理、画像分類、オブジェクト検出、および一般的な予測分析のモデルをトレーニングする顧客は、トレーニングの時間とコストの両方を削減したいと考えている。
AWSの最大の顧客の一部は、MLエンジニアが直面する課題と、複数世代のAWS GPUベースのインスタンスがこれらの課題への取り組みにどのように役立ったかについてコメントした。GE Healthcareの人工知能担当VP兼GMのKarley Yoder氏は次のように述べている:
当社の医用画像装置は、データサイエンティストによる処理が必要な大量のデータを生成します。以前のGPUクラスタでは、シミュレーション用にプログレッシブGANなどの複雑なAIモデルをトレーニングし、結果を表示するのに数日かかりました。新しいP4dインスタンスを使用すると、処理時間が数日から数時間に短縮されました。さまざまな画像サイズのモデルのトレーニングで2〜3倍の速度が見られましたが、バッチサイズを大きくするとパフォーマンスが向上し、モデル開発サイクルが速くなり、生産性が向上しました。
Toyota Research InstituteのインフラストラクチャエンジニアリングのテクニカルリードであるMike Garrison氏は、次のように述べている:
前世代のP3インスタンスは、機械学習モデルのトレーニング時間を数日から数時間に短縮するのに役立ちました。追加のGPUメモリとより効率的な浮動形式により、機械学習チームが、さらに高速により複雑なモデルのトレーニングを行えるようになるためP4dインスタンスの利用を楽しみにしています。
現在、P4インスタンスは p4d.24xlarge サイズで提供されており、米国東部および米国西部リージョンで利用できる。