AWSはこのほど、AI/MLおよびHPCワークロードで高いパフォーマンスとスケーラビリティを必要とするユーザー向けに、最新のNVIDIA H100 Tensor Core GPUを搭載したAmazon EC2 P5インスタンスの一般提供(GA)を発表した。今回のGAは、先に発表されたインフラストラクチャの開発に続くものである。
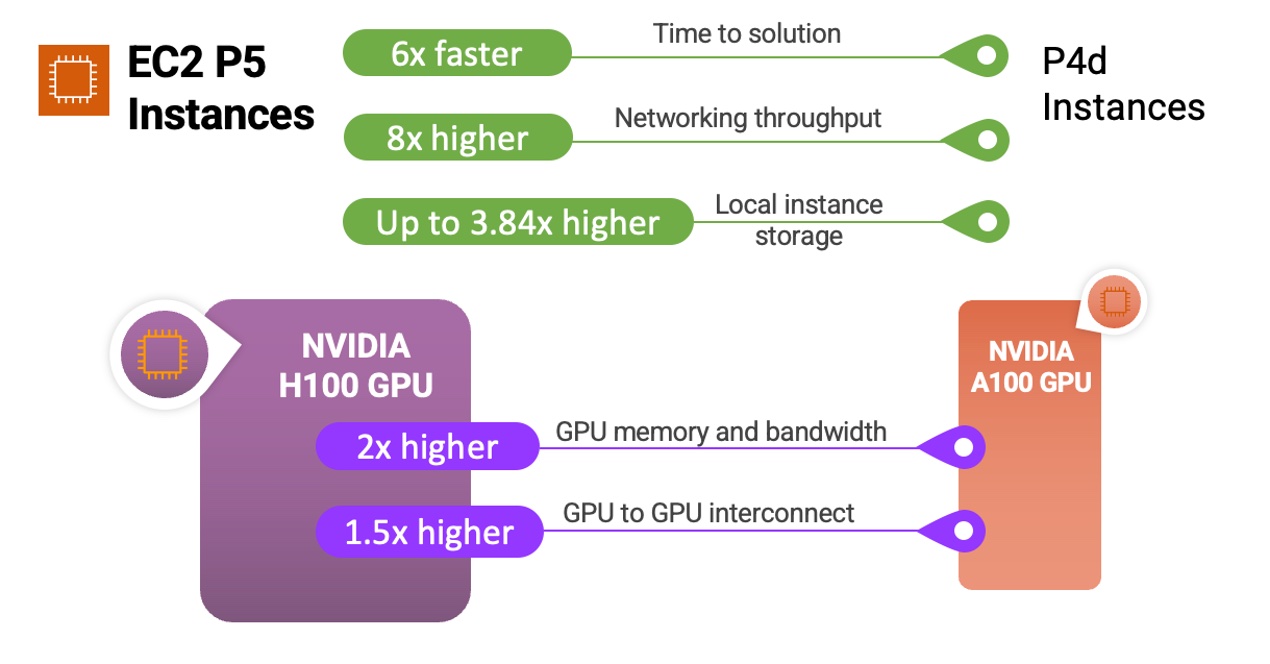
Amazon EC2 P5インスタンスは、AWSとNVIDIAの長年の協力関係から生まれたもので、ビジュアル・コンピューティング、AI、ハイパフォーマンス・コンピューティング(HPC)クラスタ向けのインスタンスの11番目のバージョンである。これらのインスタンスは、8 xNVIDIA H100 Tensor Core GPUsを搭載し、640GBの高帯域幅GPUメモリと、第3世代AMD EPYCプロセッサを搭載し、2TBのシステムメモリを提供し、30TBのローカルNVMeストレージを備えている。さらに、P5インスタンスは、GPUDirect RDMAをサポートする第2世代のElastic Fabric Adaptor(EFA)テクノロジーを使用して、3200Gbpsの総ネットワーク帯域幅を提供し、ノード間通信中にCPUをバイパスすることで、より低いレイテンシーと効率的なスケールアウト性能を実現するのだ。
同社は、前世代のGPUベースのインスタンスと比較して、トレーニング時間を最大6倍(数日から数時間)短縮し、トレーニングコストを最大40%削減できるとしている。
P5インスタンスとNVIDIA H100 Tensor Core GPUを従来のインスタンスやプロセッサと比較したインフォグラフィック(出典:AWS News Blog)
Amazon EC2 P5インスタンスを利用することで、ユーザーは、質問応答、コード生成、動画・画像生成、音声認識などのジェネレーティブアプリケーションの背後にある、複雑化する大規模言語モデル(LLM)やComputer Visionモデルのトレーニングや推論の実行に活用できる。さらに、創薬、地震解析、天気予報、金融モデリングなどのハイパフォーマンス・コンピューティングのワークロードにインスタンスを使用できるのだ。
さらに、P5インスタンスはEC2ウルトラクラスターと呼ばれるハイパースケールクラスターにデプロイできる。このウルトラクラスターは、高性能コンピューティング、高度なネットワーキング、ストレージ機能をクラウドに統合したものだ。各EC2ウルトラクラスターは堅牢なスーパーコンピューターとして機能し、ユーザーは相互接続された複数のシステムで複雑なAIトレーニングや分散HPCワークロードを実行可能である。
NVIDIAのアクセラレーテッド・コンピューティング製品担当ディレクターであるDave Salvator氏は、NVIDIAのブログ投稿で次のように述べている。
P5インスタンスは、Amazon EC2インスタンス用の3,200 Gbpsネットワーク・インターフェースであるAWS EFAによって駆動されるペタビット・スケールのノンブロッキング・ネットワークを備えている
さらに、nOps.ioのインターナショナルGMであるSatish Bora氏は、Jeff Barr氏の投稿にコメントしている。
インスタンスの中に小さなデータセンターがあるように見える
AWSの競合であるマイクロソフトとグーグルは、AI/MLやHPCワークロード向けに同様のサービスを提供している。例えば、マイクロソフトは最近、Azure Managed Lustreの一般提供を開始した。EC2ウルトラクラスターは、オープンソースの並列ファイルシステムであるLustreファイルシステム上に構築されたフルマネージド共有ストレージであるAmazon FSx for Lustreを使用している。さらにマイクロソフトは、HPCワークロード向けにAzure HBv4とHXシリーズ仮想マシンをリリースした。さらにGoogleは、ハイパフォーマンス・コンピューティングに最適化されたCompute Engine C3マシンシリーズをリリースした。
最後に、Amazon EC2 P5インスタンスは現在、米国東部(バージニア州北部)と米国西部(オレゴン州)で利用可能で、価格の詳細はEC2の価格ページで確認できる。