Meta社は、同社プラットフォーム全体で広告推薦を改善するために設計された基盤モデルGenerative Ads Model(GEM)の詳細を公開した。GEMは、クリックやコンバージョンといった有意なシグナルが極めて疎な、1日あたり数十億件規模のユーザーと広告の相互作用を処理することで、推薦システムにおける中核的課題に対処するモデルである。GEMは、広告主の目標、クリエイティブ形式、計測シグナル、複数の配信チャネルにまたがるユーザー行動など、多様な広告データから学習する複雑性に対応する。
同社は、このシステムを3つのアプローチで構築した。高度なアーキテクチャによるモデルスケーリング、知識移転のためのポストトレーニング技術、そして大規模基盤モデル学習の計算需要を支えるため、数千台のGPUと高度な並列化を用いる強化された学習インフラである。
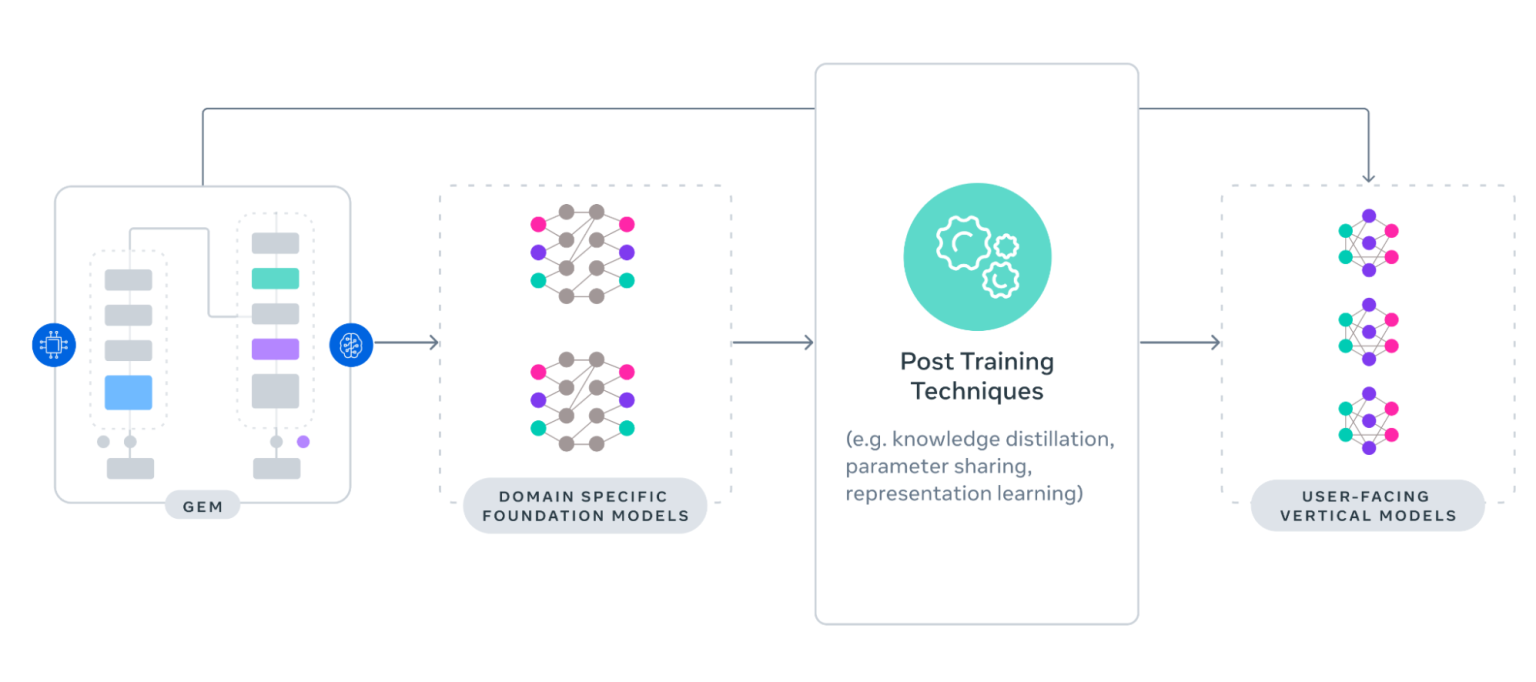
出典: GEM Architecture
Meta社は、最新の大規模言語モデルに匹敵する規模でGEMを支えるため、学習スタックを再設計した。同社は、モデルの各コンポーネントに適した多次元並列化戦略を採用している。密なモデル部分では、Hybrid Sharded Distributed Parallel(HSDP)を用いてメモリ使用量を最適化し、数千台のGPU間の通信コストを削減する。疎なコンポーネント、主にユーザーおよびアイテム特徴の大規模埋め込みテーブルでは、データ並列とモデル並列を組み合わせた二次元アプローチを採用している。
Meta社は、学習時のボトルネックを低減するため、複数のGPUレベル最適化を実装した。これには、可変長ユーザーシーケンス向けに設計された社内独自のGPUカーネル、PyTorch 2.0におけるグラフレベルコンパイルによるアクティベーションチェックポイントとオペレータ融合の自動化、アクティベーションに対するFP8量子化などのメモリ圧縮技術が含まれる。
同チームは、NVIDIAのNCCLをMeta社がフォークしたNCCLXを通じて、Streaming Multiprocessorリソースを使用しないGPU通信コレクティブを開発した。これにより、通信処理と計算処理の競合が解消される。Meta社は、トレーナー初期化、データリーダー設定、チェックポイント処理の最適化により、ジョブ起動時間を5倍短縮した。さらに、キャッシュ戦略によりPyTorch 2.0のコンパイル時間を7倍短縮し、新規データ処理に充てられる学習時間の割合を改善した。
このシステムは、モデルのライフサイクル全体でGPU効率を最適化する。探索段階では、軽量なモデル派生版が全実験の半数以上を担い、フルサイズモデルより低コストで運用される。Meta社は基盤モデルを更新するために継続的なオンライン学習を行い、学習とポストトレーニングの知識生成でトラフィックを共有することで計算負荷を低減する。
Meta社は、GEMを用いて、同社プラットフォーム全体で広告を配信する数百のユーザー向け垂直モデルへ知識を移転する設計をした。同社は、基盤モデルの能力を測定可能な成果へ変換するため、2つの移転戦略を採用している。
直接移転では、GEMが学習された同一データ空間内で、主要な垂直モデルへ知識を伝達する。階層的移転では、GEMからドメイン特化型の基盤モデルへ知識を蒸留し、それらがさらに垂直モデルを学習させる。
これらのアプローチは、知識蒸留、表現学習、パラメータ共有を活用し、Meta社の広告モデルエコシステム全体で移転効率を最大化する。
Tesla社の元ディレクターであるSwapnil Amin氏は、GEMについて次のように述べた。
これは、私たち全員が来ると分かっていた転換点のように感じます。後から部品をつなぎ合わせるのではなく、クリエイティブ、文脈、ユーザー意図を同時に学習するモデルです。
同氏は、23倍の実効FLOPs向上について次のように強調した。
これが経済性を変える部分です。
マイクロソフト社のシニアプロダクトマネージャーであるSri P氏は、広告主向けの応用可能性を指摘し、次のように述べた。
これはマーケターや広告主にとってゲームチェンジャーです。小規模事業者がマーケティング戦略を試行錯誤する必要がなくなり、賢いモデルに広告費の最適化を任せられるため、大幅なコスト削減につながる可能性があります。
Meta社は、広告推薦システム向け基盤モデルが、ユーザーの嗜好や意図をより深く理解し、よりパーソナライズされた体験を実現すると構想している。広告主にとっては、これを大規模での一対一のつながりを可能にするアプローチとして位置付けている。