Key Takeaways
- Several recent data trends are driving a dramatic change in the old-world batch Extract-Transform-Load (ETL) architecture: data platforms operate at company-wide scale; there are many more types of data sources; and stream data is increasingly ubiquitous
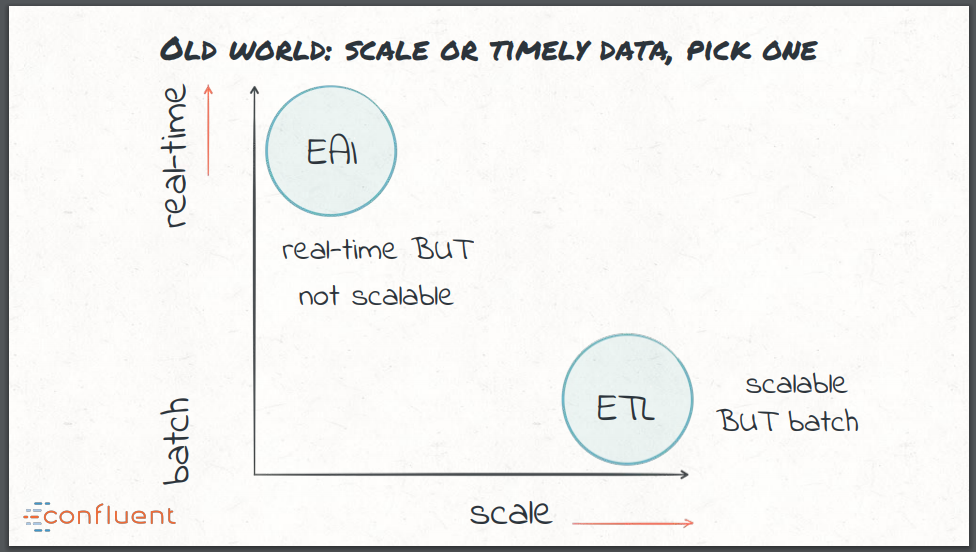
- Enterprise Application Integration (EAI) was an early take on real-time ETL, but the technologies used were often not scalable. This led to a difficult choice with data integration in the old world: real-time but not scalable, or scalable but batch.
- Apache Kafka is an open source streaming platform that was developed seven years ago within LinkedIn
- Kafka enables the building of streaming data pipelines from “source” to “sink” through the Kafka Connect API and the Kafka Streams API
- Logs unify batch and stream processing. A log can be consumed via batched “windows”, or in real time by examining each element as it arrives
At QCon San Francisco 2016, Neha Narkhede presented “ETL Is Dead; Long Live Streams” and discussed the changing landscape of enterprise data processing. A core premise of the talk was that the open-source Apache Kafka streaming platform can provide a flexible and uniform framework that supports modern requirements for data transformation and processing.
Narkhede, co-founder and CTO of Confluent, began the talk by stating that data and data systems have significantly changed within the past decade. The old world typically consisted of operational databases providing online transaction processing (OLTP) and relational data warehouses providing online analytical processing (OLAP). Data from a variety of operational databases was typically batch-loaded into a master schema within the data warehouse once or twice a day. This data integration process is commonly referred to as extract-transform-load (ETL).
Several recent data trends are driving a dramatic change in the old-world ETL architecture:
- Single-server databases are being replaced by a myriad of distributed data platforms that operate at company-wide scale.
- There are many more types of data sources beyond transactional data: e.g., logs, sensors, metrics, etc.
- Stream data is increasingly ubiquitous, and there is a business need for faster processing than daily batches.
The result of these trends is that traditional approaches to data integration often end up looking like a mess, with a combination of custom transformation scripts, enterprise middleware such as enterprise service buses (ESBs) and message-queue (MQ) technology, and batch-processing technology like Hadoop.
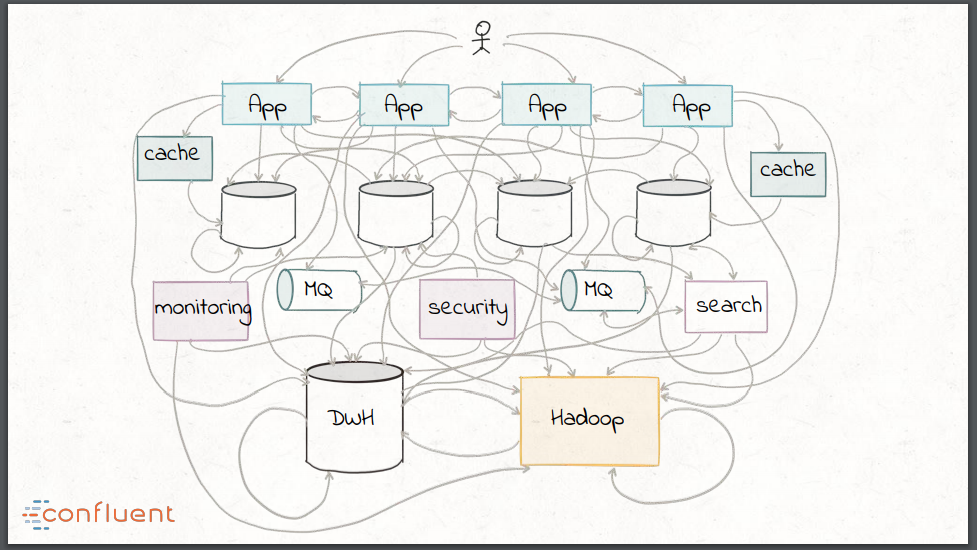
Before exploring how transitioning to modern streaming technology could help to alleviate this issue, Narkhede dove into a short history of data integration. Beginning in the 1990s within the retail industry, businesses became increasingly keen to analyze buyer trends with the new forms of data now available to them. Operational data stored within OLTP databases had to be extracted, transformed into the destination warehouse schema, and loaded into a centralized data warehouse. As this technology has matured over the past two decades, however, the data coverage within data warehouses remains relatively low due to the drawbacks of ETL:
- There is a need for a global schema.
- Data cleansing and curation is manual and fundamentally error prone.
- The operational cost of ETL is high: it is often slow and time and resource intensive.
- ETL tools were built to narrowly focus on connecting databases and the data warehouse in a batch fashion.
Enterprise application integration (EAI) was an early take on real-time ETL, and used ESBs and MQs for data integration. Although effective for real-time processing, these technologies could often not scale to the magnitude required. This led to a difficult choice with data integration in the old world: real time but not scalable, or scalable but batch.
Narkhede argued that the modern streaming world has new requirements for data integration:
- The ability to process high-volume and high-diversity data.
- A platform must support real-time from the ground up, which drives a fundamental transition to event-centric thinking.
- Forward-compatible data architectures must be enabled and must be able to support the ability to add more applications that need to process the same data differently.
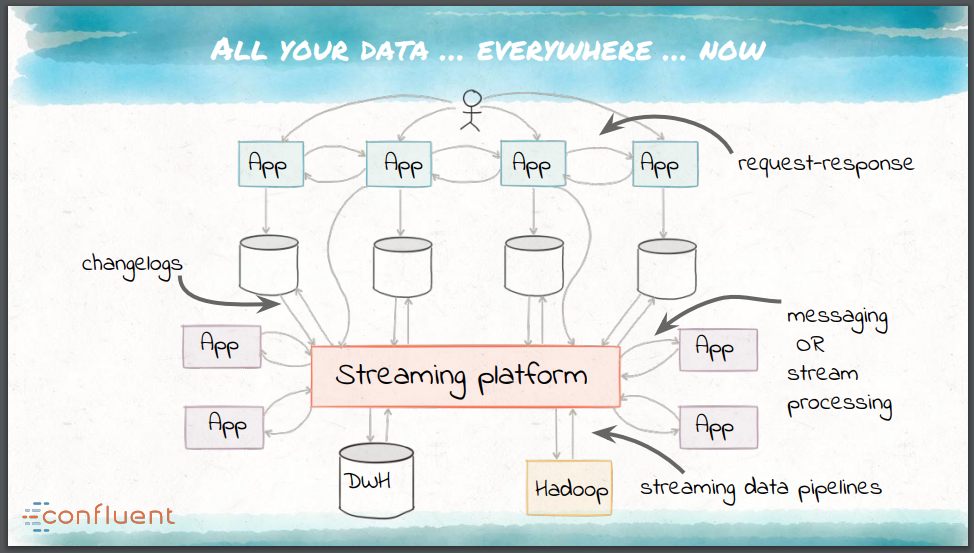
These requirements drive the creation of a unified data-integration platform rather than a series of bespoke tools. This platform must embrace the fundamental principles of modern architecture and infrastructure, and should be fault tolerant, be capable of parallelism, support multiple delivery semantics, provide effective operations and monitoring, and allow schema management. Apache Kafka, which was developed seven years ago within LinkedIn, is one such open-source streaming platform and can operate as the central nervous system for an organization’s data in the following ways:
- It serves as the real-time, scalable messaging bus for applications, with no EAI.
- It serves as the source-of-truth pipeline for feeding all data-processing destinations.
- It serves as the building block for stateful stream-processing microservices.
Apache Kafka currently processes 14 trillion message a day at LinkedIn, and is deployed within thousands of organizations worldwide, including Fortune 500 companies such as Cisco, Netflix, PayPal, and Verizon. Kafka is rapidly becoming the storage of choice for streaming data, and it offers a scalable messaging backbone for application integration that can span multiple data centers.
Fundamental to Kafka is the concept of the log; an append-only, totally ordered data structure. The log lends itself to publish-subscribe (pubsub) semantics, as a publisher can easily append data to the log in immutable and monotonic fashion, and subscribers can maintain their own pointers to indicate current message processing.
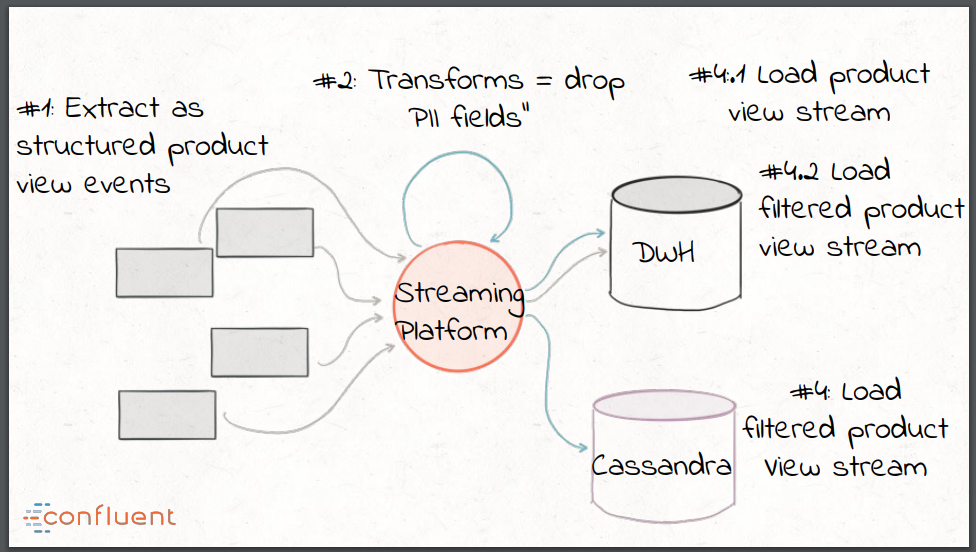
Kafka enables the building of streaming data pipelines — the E and L in ETL — through the Kafka Connect API. The Connect API leverages Kafka for scalability, builds upon Kafka’s fault-tolerance model, and provides a uniform method to monitor all of the connectors. Stream processing and transformations can be implemented using the Kafka Streams API — this provides the T in ETL. Using Kafka as a streaming platform eliminates the need to create (potentially duplicate) bespoke extract, transform, and load components for each destination sink, data store, or system. Data from a source can be extracted once as a structured event into the platform, and any transforms can be applied via stream processing.
In the final section of her talk, Narkhede examined the concept of stream processing — transformations on stream data — in more detail, and presented two competing visions: real-time MapReduce versus event-driven microservices. Real-time MapReduce is suitable for analytic use cases and requires a central cluster and custom packaging, deployment, and monitoring. Apache Storm, Spark Streaming, and Apache Flink implement this. Narkhede argued that the event-driven microservices vision — which is implemented by the Kafka Streams API — makes stream processing accessible for any use case, and only requires adding an embedded library to any Java application and an available Kafka cluster.
The Kafka Streams API provides a convenient fluent DSL, with operators such as join, map, filter, and window aggregates.

This is true event-at-a-time stream processing — there is no micro-batching — and it uses a dataflow-style windowing approach based on event time in order to handle late-arriving data. Kafka Streams provides out-of-the-box support for local state, and supports fast stateful and fault-tolerant processing. It also supports stream reprocessing, which can be useful when upgrading applications, migrating data, or conducting A/B testing.
Narkhede concluded the talk by stating that logs unify batch and stream processing — a log can be consumed via batched windows or in real time by examining each element as it arrives — and that Apache Kafka can provide the “shiny new future of ETL”.
The full video of Narkhede’s QCon SF talk “ETL Is Dead; Long Live Streams” can be found on InfoQ.
About the Author
 Daniel Bryant is leading change within organisations and technology. His current work includes enabling agility within organisations by introducing better requirement gathering and planning techniques, focusing on the relevance of architecture within agile development, and facilitating continuous integration/delivery. Daniel’s current technical expertise focuses on ‘DevOps’ tooling, cloud/container platforms and microservice implementations. He is also a leader within the London Java Community (LJC), contributes to several open source projects, writes for well-known technical websites such as InfoQ, DZone and Voxxed, and regularly presents at international conferences such as QCon, JavaOne and Devoxx.
Daniel Bryant is leading change within organisations and technology. His current work includes enabling agility within organisations by introducing better requirement gathering and planning techniques, focusing on the relevance of architecture within agile development, and facilitating continuous integration/delivery. Daniel’s current technical expertise focuses on ‘DevOps’ tooling, cloud/container platforms and microservice implementations. He is also a leader within the London Java Community (LJC), contributes to several open source projects, writes for well-known technical websites such as InfoQ, DZone and Voxxed, and regularly presents at international conferences such as QCon, JavaOne and Devoxx.