Key Takeaways
- Pull Request-based async code reviews are a prevailing way of reviewing code in our industry
- When feedback is invited only after making a lot of changes, it becomes very difficult for both the PR reviewer(s) and the author to course-correct and build in quality
- Delays are an inherent property of asynchronous reviews, and they increase PR batch transaction cost
- With small Pull Requests, we lose throughput if we review them asynchronously because delays in communication start dominating PR lead time
- Co-creation patterns, Pair and Mob Programming enable continuous code review which enables both high throughput and high quality
Decades ago, open-source software gave us the ability for anyone in the world to contribute to a codebase of a public project. Contributors could be on different ends of the world, in vastly different time zones, not even knowing each other's names for that matter. A contributor to the project comes up with an idea for improvement, makes a change, and raises a Pull Request (PR) for that change. Then, the owner of the project gets to review the change and decide, when it suits them, if they’d like to integrate the proposed change or not.
Fast-forward many years later, Pull Requests and asynchronous ways of working are the dominant ways in which developers in product development teams review each other’s work. But, we have to be very wary of adopting solutions from contexts that don’t necessarily optimize for the same things that product development teams do in their day-to-day work.
This article dives into the throughput and quality of the async code review process, which are very important dimensions to optimize for in product development teams. It also explains why co-creation patterns – Pair and Mob programming – as an alternative way of working are able to optimize for both of those dimensions, instead of needing to trade off between them.
Async code reviews
In most of the teams I have had the chance to work with or observe, developers work individually on their own work items. At the start, that sounds like a sensible idea, but too often we forget how much integration we have with other people in the team. After all, we’re not part of the same team for no reason, right? Code reviews are one of these integration points where developers try to use code review as a means to building in quality and getting human judgement, before pushing the work downstream until it eventually reaches production.
The way it goes is that once a developer thinks they are done with coding, they invite other team members to review their work. This is nowadays, typically done by raising a Pull Request and inviting others for a review. But, because reviewers are busy with their own work items and a plethora of other things happening in the team, they are not able to react immediately. So, while the author is waiting for a review, they also want to feel productive, thus they start working on something else instead of twiddling their thumbs and waiting for a review.

Figure 1 – PR-based async code review
Eventually, when reviewer(s) become available and provide feedback on the PR and/or ask for changes, the author of the PR is then not available because they are busy with something else. This delayed ping-pong communication can extend over several days/weeks and a couple of iterations, until the author and reviewer(s) converge on a solution they are both satisfied with and which gets merged into the main branch.
Study on async code reviews
A good share of teams I had the chance to coach and advise in my career were at some point curious to try out ways of working that were different from async code reviews. One thing they were not sure about was how they were currently performing and what kind of metrics would help them understand that.
Also, having a background in eXtreme Programming (XP), Lean, and the Theory of Constraints, there were some metrics I was curious to see in the async code reviews world, so I decided to do a study. It started small but turned out to be a fairly extensive one, where I analyzed over 40,000 PRs from more than 40 very active repositories of product development teams doing PR-based async code reviews.
Over the course of the study, a couple of systemic insights jumped out at me. From personal and anecdotal experience, some of them I expected to see, but some of them were quite a surprise.
Big Pull Requests inhibit the ability to build in the quality
The bigger the PR, the more likely it will suffer from the so-called “LGTM syndrome”. If the PR is big, reviewers have way less incentive to build in the quality. It takes them a long time to review, lots of back and forth with the author, dragging for many days/weeks while the pressure for delivery piles up. It’s already too late and very difficult to course-correct at the point when work reaches the reviewer(s). They often tend to give up on the ability to steer the work, merely comment “LGTM” (Looks Good To Me), and approve the PR, hoping to build in quality later. That, of course, rarely happens.
Even when reviewers want to invest time, energy, and patience in reviewing big PRs, if the author makes a lot of changes before asking for feedback, and if they went astray at one point (the likeliness for that grows with the amount of work) it is emotionally very painful to divorce from the solution they went with. Sunk cost fallacy kicks in, and it’s very difficult to counteract it.
All of these points are the experience we mostly share across the industry, but it was interesting to see it in the data, as well.
Here, we have a scatter plot, where each dot represents a merged PR. On the X-axis, we have PR size in lines of code changed and on the Y-axis we see engagement per size (number of comments per 100 lines of code). This data set is just one example, but it’s important to emphasize that this behavior was visible across all the other analyzed data sets.

Figure 2 – Engagement per size by size scatter plot
As we increase the size of the PR, we get to see less engagement per size. We have a process to help us build in quality that is based on feedback and inviting human judgement, but if the system incentives constrain our ability to get the feedback, that also means we are less likely to build in quality. So, we end up introducing delays, at the cost of not being able to build in quality. It’s a lose-lose if you ask me.
There are additional reasons why big PRs affect our ability to build in quality that were not part of the study, but are worth mentioning here.
Context tends to decay with delayed feedback, which means it’s more likely for reviewer(s) to struggle in understanding the reasoning and context behind a certain author’s decisions. That makes it less likely for reviewers to contribute to the quality of the work.
Because they bundle a bunch of changes together, big PRs are more likely to cause a problem in production, which means they are more likely to cause a significant amount of rework. From my experience, the likelihood of rework grows exponentially with the number of changes introduced at once.
When the issue in production occurs, it also takes us longer to troubleshoot the problem and find the needle in the haystack that caused it. The loss of context, as a second-order effect of too many changes introduced at once, is another thing that contributes to a longer time to troubleshoot, as well.
Benefits of small Pull Requests
It’s been a long time now since our industry has understood the value of small batches from Lean. Smaller PRs take less time to write, which means we get feedback sooner, and we are able to detect earlier if we went astray. It’s also easier for reviewers to find 10 minutes of their time to review a small PR than having to find a couple of hours in their schedule to review a big PR. This makes it more likely that a PR will be reviewed sooner.
Also, since reviewers get invited for feedback sooner, we get to see more engagement on smaller PRs than on bigger ones. When they are able to provide feedback early, reviewers have a sense of being able to contribute to the quality. Small PRs are also less risky to deploy than big PRs, since fewer things can go wrong with a smaller change.
Furthermore, if something goes wrong, it’s easier to pinpoint the change that introduced the problem, which means we’re able to detect and resolve the incident sooner. All of these things positively contribute to all four key DORA metrics:
- Deployment Frequency – How often an organization successfully releases to production
- Lead Time for Changes – The amount of time it takes a commit to get into production
- Change Failure Rate – The percentage of deployments causing a failure in production
- Time to Restore Service – How long it takes an organization to recover from a failure in production
Small Pull Requests reviewed asynchronously have lower throughput
One of the surprising insights from the study that I didn’t expect, and that was persistent across all datasets, was around visualizing PR wait time per size, by size.
PR wait or queue time represents the time that PR spends in the queue, not being worked on, waiting for someone’s attention; e.g., waiting for a review from the reviewer(s), waiting for the author to respond to comments, or to make a change requested by the reviewer(s), waiting to get merged after the approval, etc.

Figure 3 – Wait time per size, by size
As we can see from this scatter plot, as we decrease the size of a PR, teams doing async code reviews incurred exponentially longer wait times per PR size. That exponentially longer wait time also translates to an exponentially higher perceived cost of code review per size as we make PRs smaller.
One of the reasons wait time per size dominates on the smaller PR size of the spectrum is that the engagement per size on smaller PRs is higher, as we saw on the engagement per size scatter plot. The cost of delays and latency that are incurred with the async communication grows exponentially as we reduce the size of a PR.
An important thing to have in mind is that as we incur more wait time per PR size, we incur more waste per PR, leading to more cumulative waste in our system of work. So, as we keep reducing PR size, we exponentially constrain our ability to push changes through the system of work.
That point was also supported by looking at the average PR flow efficiency.
The flow efficiency metric represents the time spent working on an item as a percentage of the item’s lead time.


The lower the flow efficiency, the more waste in the system and the less efficient the process is, and vice versa.

Figure 4 – Average flow efficiency by size
As you can see, as we reduce the size of a PR, flow efficiency at one point takes a nosedive. This means it takes us way longer cumulative lead time to push the same amount of code through the system if we split it into multiple smaller PRs, compared to when we do it in a single big PR. As we incur more wait time in the process, the denominator of the flow efficiency goes up, causing flow efficiency to drop, lead times to go up, and the throughput to go down.
So, with the async way of working, we’re forced to make a trade-off between losing quality (big PRs) and losing throughput (small PRs).
Interestingly, teams intuitively start feeling this pain as they reduce PR size beyond the point where wait time starts dominating PR lead time.
Inventory in the system expands until it matches the transaction cost
In Lean manufacturing, a concept called batch transaction cost describes the cost of sending a batch of work to the next stage of processing. In knowledge work, that cost could be in real terms (e.g., dollar value), and/or perceived ones, and there could be multiple factors contributing to it. The reason this concept is very important is that the higher the transaction cost of a stage of processing, the more inventory we pile up in front of that stage to compensate for the cost of transferring a batch.
Here’s an example from the real world. If the shipping cost from an e-commerce site is, say, $3, most often you’re not going to order an item that costs $1, right? You’ll typically batch it with some other items in the basket before ordering. On the other hand, when the shipping cost is very low or even free (think Amazon Prime), ordering low-price items becomes economically sound.
Also, compared to batching items over time in the basket before ordering, you’ll be ordering items exactly when you need them instead of only when the basket value is high enough to justify the shipping costs. That means that items will also arrive sooner, one by one, instead of all but the last item in the batch waiting for the last one. The flow of items increases.
A general point here, applicable to product development, is that any effort to get things out of the door sooner must involve reducing the transaction cost in the system, otherwise, we start batching the inventory throughout the system of work. That in turn delays delivery, feedback, and learnings that we get from our customers and production system, which means our learning cadence decelerates. Once our learning cadence decelerates, we become risk-averse and tend to go with more conservative solutions because the system is signalling that the cost of learning is high. That’s the way the economics of our system of work inhibits our capability to innovate because trying out riskier ideas becomes economically way less viable. Just asking people to be more risk-averse and innovative doesn’t make sense if the incentive structure of the system is pushing strongly against it. The behavior that we see is governed by the system, so if we want to see different behavior, we need to work on the system.
Now, when we talk about the transaction cost, delays in the system are also one type of it, and thus incentivize actors to increase the batch size to compensate for it.
If a delivery from your favorite online clothing store takes one week, and you want to try out multiple things before deciding which one you’ll keep, you’ll probably order all options and sizes you’re considering. On the contrary, if it’s same-day delivery you’ll probably order way fewer items, possibly just one, try it out, see if it fits, and only then order the next option if it doesn’t.
The same thing happens with a slow-running test suite. If it takes me 20 minutes to run the tests, I’m not going to run them after every line of code change I make. Incurring that much overhead so often doesn’t make any economic sense, so I’ll run the tests less often, which means introducing more changes to the system before getting feedback. That makes me slide back into bigger batches, which, as mentioned, brings its own set of problems that we want to avoid.
In the world of async code reviews, if it takes me 10 minutes to make a change and 2 hours to get a review, the wait-to-work time ratio for this change is 120/10=12. In other words, we have a flow efficiency of only 7.7% and the work is waiting 92.3% of its lead time! The system is signalling a high cost of code review, which incentivizes actors in the system to ask for it less often, which means making more changes before asking for it, which means going back into bigger PRs. A process that expensive will never incentivize making small changes, which means refactoring and incremental development in small steps become less likely. Corollary, teams having lower latency in their process and lower wait-to-work time ratio have higher chances of keeping their codebase healthy and keeping it responsive to change by enabling a continuous flow of small improvements that compound over time.
To put it in another way, if there are delays in the process (and they are inherent to the async way of working) I can always find you a batch size small enough for which flow efficiency is so bad that it doesn't make economic sense to have a batch size that small. This, in turn, incentivizes us to go back into bigger batches.
While you may ignore economics, it won’t ignore you. — Don Reinertsen
Another issue with delays and the async way of working is that they make it more likely for people to pull in more things, increasing Work in Process (WIP) inventory and context-switching. We saw it with Ema and Luka in “Figure 1 – PR-based async code review”. While Ema was waiting for Luka to review, she figured she could start working on something else. Per Little’s Law, the average cycle time is directly proportional to the average Work in Process and inversely proportional to the average throughput. That means that pulling in more work, as Ema did while she was waiting, increases delays, which makes cycle times go up and throughput go down.

When we work individually and review code asynchronously, WIP is often way higher than we think. If we have 4 people in a team, and they work individually, we might think we have 4 things in progress. But when there are delays in the system, and we rely on getting feedback from other people, as we do with code reviews, it’s very likely that we end up with at least twice as much WIP. Ema pulling more work while she’s waiting happens to everyone else on the team because they also need to wait for the review of their respective PRs. So we end up with 8 things in progress. In my experience, it’s not surprising to see teams having WIP equivalent to a couple of multiples of the number of people in the team.

Figure 5 – High WIP invites even more WIP Causal Loop Diagram
At the same time, ironically, if you were to ask Ema and others on the team, they’d probably say that they felt quite productive during this time. One of the most important lessons from Systems Thinking is that systems often deteriorate not in spite of but because of our efforts to improve them. The most intuitive solutions often tend to be far from the ones that help with shifting the system towards a more desirable state.
A general point here is that the second-order effect of high WIP is that it reinforces itself. The more WIP we have in the system, the less responsive it becomes, the longer the wait times and delays, and that, in turn, incentivizes even higher WIP because people pull in more stuff as they need to wait. Humans are great at piling up inventory and increasing WIP when they face delays.
Co-creation patterns
The conclusion of the study I did was that in order not to exponentially lose throughput as we reduce the average size of a PR, the author, and reviewer(s) need to react exponentially faster to each other’s request. And that eventually leads us to synchronous, continuous code reviews and co-creation patterns.
Co-creation patterns, Pair and Mob Programming are ways of working where we work together on the same thing, at the same time. We start together, work together, and finish together. Pair Programming1 is a technique where a pair of developers works on the same thing, while Mob Programming2 is more focused on having all the skills in the session necessary to get the feature into customers’ hands. Depending on the feature at hand, that might involve only developers, but also other skills (design, product, content…).
The idea is to move people to the problem, instead of moving the problem to the people; the latter involves splitting the problem and giving each person a piece of that problem to solve individually, and then trying to reassemble the whole piece afterward. When we swarm on the problem, as a byproduct, we have fewer delays in the interactions, which means a shorter lead time to get our work into customers’ hands. Think about it: when there’s an outage in production, how do we go about it? Typically, all the people needed to resolve the issue jump on a call and work together to resolve it.
The reason we’re working in this way is that we want to resolve the issue sooner, so we can reduce the time to recover and thus minimize the impact. But the important insight is that we can use the same way of working to minimize the lead time to deliver. That, in turn, accelerates the learning cadence that helps us cut solutions that don’t work sooner, and thus maximizes the throughput of the value of the team.
Eli Goldratt, the founder of the Theory of Constraints, had a lot to say about emergencies being a great learning opportunity. The rules used during emergencies violate our standard rules and challenge unquestioned assumptions, but we rarely ask ourselves if our “special rules” should actually be our standard rules.
Also, the incentive structure that we get as a byproduct of co-creation is also very different from the typical “You Burn, I’ll Scrape” approach. Instead of having an undertone of “an author and a critic”, we have people together building and being responsible for making it work.
…our system of make-and-inspect, which if applied to making toast would be expressed: ‘You burn, I’ll scrape. — W. Edwards Deming
One of the typical arguments I hear in favor of PRs and async code reviews is: “Code should be reviewed by someone who was not involved in the process of building”. But, from my experience, the delayed and out-of-context review is actually a disadvantage, not an advantage of this process.
What guarantees that the same person providing an out-of-context and delayed review wouldn’t provide the same or better feedback if they were providing it as the code was being written? It’s a hard and probably impossible thing to measure, but from my experience, more context, less delay in the process, and faster communication contribute to higher quality, more timely, and cheaper to integrate feedback. I’m guessing that’s also the reason I observed that teams co-creating had at least an order of magnitude less rework, including fewer bugs and problems in production.
BOTH throughput AND quality
I know it sounds utopian, but we can actually both have our cake and eat it too. We can both have high throughput and high quality. It also wouldn’t be the first time to discover that that’s possible, since the DORA research showed that stability and throughput have an AND instead of OR relationship. Instead of having either throughput or stability, we have either both throughput and stability, or neither of those.
The way that co-creation patterns change the economics of the system is that with Pair and Mob Programming review delays and wait times are, by design, essentially non-existent. As someone is physically or virtually sitting next to me, working on the same thing I am, they are able to provide continuous code review with every atomic change I make in the code, and vice versa. The process itself guarantees the availability of actors, which is necessary in order to have an immediate code review and consequently not lose throughput with smaller PRs.
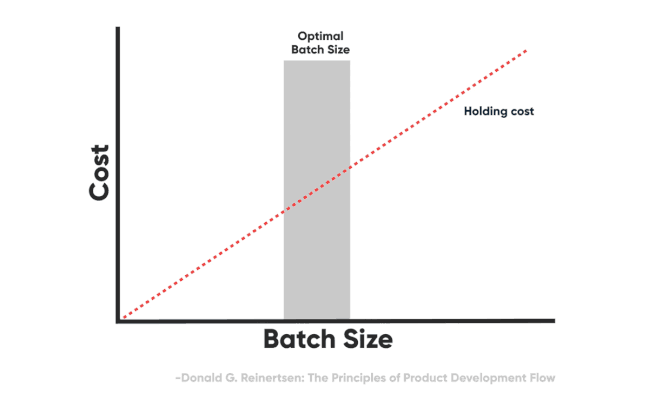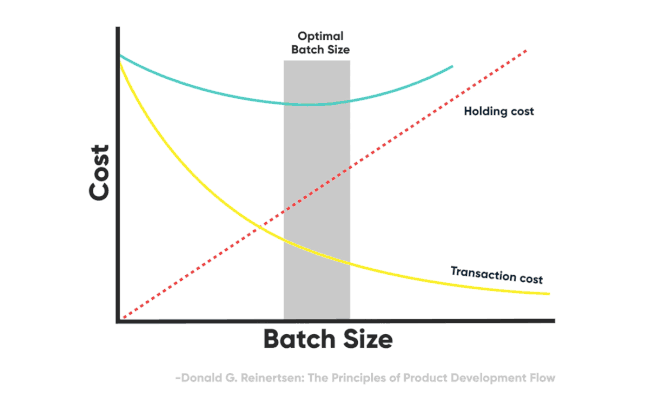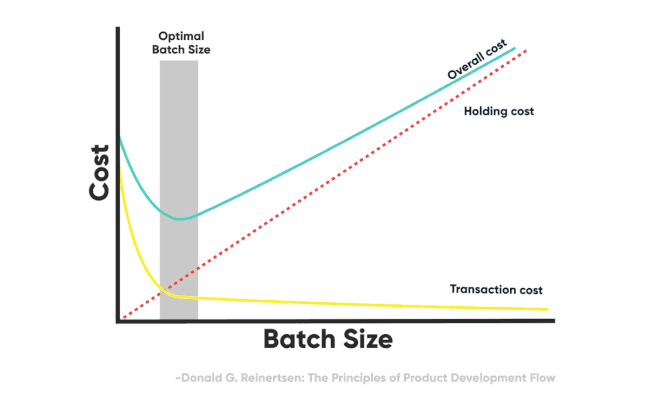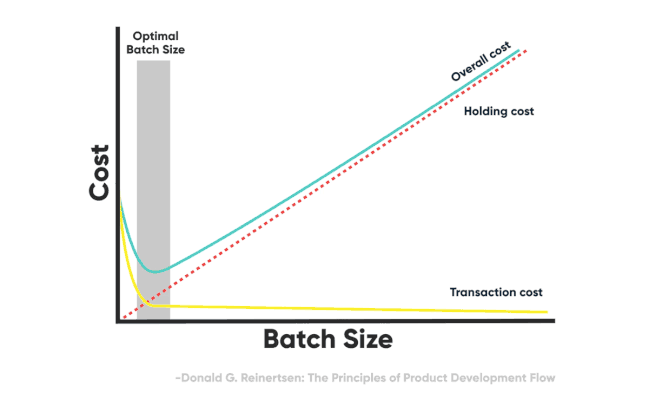
Figure 6 – Reducing transaction cost drives the smaller optimal batch size
Featured animation: Kelly Albrecht
Effectively, in Lean terms, we’re able to minimize the transaction cost because we’re minimizing the cost of code review, enabling even smaller batches, and increasing the flow through the system. The size of a PR effectively becomes a minimal, atomic change that could be as low as 1 line of code.
When we have immediate availability and free cost of code review, I’m able to get more timely, more frequent, and richer feedback (it’s verbal, immediate, and in the context). This is crucial in order to build in quality, but, as a byproduct, it also reduces the amount of rework. The reason is that when we go down the wrong route we avoid straying away for a long time since the course correction happens sooner, and that leads to more time left for value-added work and, thus, higher productivity. We reach a state of quality-enabled speed.
Another advantage that is often missed is that working together doesn’t only minimize the wait time. Typically, it also reduces the processing/work time, because other people often have an idea of how to do something in a faster way, which means the processing time goes down as well. That, in turn, translates into even shorter lead times and higher throughput.
When we have fast course correction, enabled by continuous code review, we also tend to counteract the sunk cost fallacy and falling in love with the solution. The only thing I have to lose is a minimal change that I just made. I can deal with that far better than having to discard a week’s worth of effort. Thus, we make it more likely to build in quality.
Besides that, and contrary to async code reviews, as a byproduct of working together on the same thing at the same time we reduce Work In Process, which accelerates the flow of work through the system. As mentioned, async work that needs to integrate makes us prone to pulling in even more work, which makes things even worse. In the case of a team of 4 people, when they work individually, they can easily end up with twice as much WIP. In the case of Pair Programming, they’d have a WIP of 2, which is 4 times less! With Mob Programming, WIP is even less. That’s an opportunity for a huge reduction in WIP that is hard to leave on the table.
Common misconceptions
Having said all this, I don’t think that everyone should do Pair/Mob programming all the time- this is a common misconception that I hear from people sceptical about these practices.
The point is, I think that when it comes to the way of working, we as an industry have wrong defaults in place, where most of the time everyone works individually. Most teams operate as N teams of 1 person, instead of 1 team of N persons.
The pandemic seems to have contributed to this, as well. From its onset, as the whole industry went remote, for some reason we’ve put an equals sign between being remote and async work. These two ideas are orthogonal to each other. We can both work remotely and co-create, so we keep the above-stated benefits of working together, while also having the flexibility of working from home.
A question I also often get is: “How is co-creation allowing for flexibility of individual schedules that we get with async work?” There are teams that want to try out Pair Programming, but they bump into the problem of having slippages in individual schedules and pairing partners not being available when needed. That’s an important crossroad where teams usually take a wrong turn and go async. The need to go async at that point is feedback about something. It’s feedback about the low flow resiliency with the given schedules. Instead of going async, we can consider increasing the resilience of the group by having more people in the session. That allows for more overlap in the schedules while keeping the flow efficiency high and getting things out of the door sooner. Mob programming especially provides that resiliency, and people can drop out and come back as they need. It’s not that everyone needs to be there all the time. That was never the idea.
Now, if you have a team whose team members are in very distant time zones and there’s not much overlap between team members during the work day, I’d question that team composition decision instead of jumping into the async wagon. Regardless of this whole topic, I’d expect a team to be composed of team members with enough overlap in working hours. The definition of enough may vary, but from my experience, at least 5 hours of overlap is a good target to aim for.
Interestingly, the way it also plays out in practice is that flexibility in individual schedules coupled with high resiliency of the group can actually be an advantage. Typically, as with in-office work, some people like to start their day sooner and some later. People that start sooner start working on the work item, then the rest of the people join, and then the group of people that ends their working day later wrap it up for the day. Since we’ve worked on the item for longer hours during the day, we’ll probably get it done sooner, while people keep their flexible individual schedules. It can be a win-win situation.
In a world where unfortunately most people only have had experience working alone, learning to work together is a new skill that takes time and patience to acquire. I remember attending Woody Zuill’s workshop on Mob Programming. Out of three days of the workshop, he spent the first whole day having people practice working together, contributing in a timely manner, and treating each other with kindness, consideration, and respect. Those principles are ground rules for working together. To be honest, at that time it seemed a bit superfluous to spend so much time on this topic. But over the years, as I started observing and working with more and more teams trying to co-create, it became obvious why being intentional about these principles and skills is so important.
It’s very important to have proper guidance and coaching for the teams that want to embark on the journey of co-creation, especially if no one from the group has prior experience with it. Otherwise, teams might end up evaluating a technique thinking they were doing Pair or Mob programming, while in reality, they were doing something very much different. People hijacking the keyboard, individuals dominating conversations, too long or non-existent rotations, people being disengaged and zoning out, etc. were never part of the co-creation idea, yet, that’s what I often get to see in the teams saying “This is not for us”. And they are right. But, first, we need to make sure we’re evaluating a technique we think we’re evaluating. Investing time in learning more about these practices and getting proper support helps us with that.
Another essential point is that working together bubbles up latent problems in the team very fast. When we work individually, by design there’s not much interaction between people, so potential issues tend to be way less visible and way more delayed. Once the issue of having difficulties working together in a team becomes obvious, there’s often a tendency to think “co-creation is not for us”. That might be the case, but only if addressing the problems in the team surfaced by a particular technique is not something we’re after. The technique is just a mirror of the underlying team dynamics. We get to choose what we do with that feedback, but, ultimately, we can’t blame a technique for the issues that exist without it anyway.
Nevertheless, working together should not be forced upon anyone. After all, you might give it a shot and find it’s really not your cup of tea. Everyone should try to find the environment that meets their needs best. Hopefully, that moves us closer to a state where more people find joy in their work.
Summary
Reducing PR size in async code reviews will only get you so far. There’s a point where a smaller PR size becomes economically unviable, and we have to make a trade-off between throughput and quality. Moving from async code reviews to pairing on code review, to doing work itself together (Pair/Mob Programming) is a progression that lots of teams in our industry might benefit from experimenting with.
There are lots of other benefits3 why teams might consider giving it a try, and from my experience it’s a way of working that has brought so much joy and productivity to teams I have had a chance to do it with, that I believe it’s a competitive advantage and capability for teams and companies that get to adopt it.