研究者グループが、一般的に使用されている100万件ではなく、3億件のイメージで構成されたデータセットを対象にトレーニングを行なったモデルを用いることによって、いくつかのベンチマーク結果で最高レベルを更新することに成功した。
研究者の大多数は、100万件のイメージで構成されるImageNetデータセットを使用して、自らのオブジェクト検出アルゴリズムをトレーニングしている。2011年以降、このデータセットにはイメージが追加されていない。その一方で、このデータセット上のトレーニングされるニューラルネットワークのパラメータ数は増加すると同時に、こういったモデルのトレーニングにGPUのパワーが使用されるようになった。Googleの研究者たちとカーネギメロン大学(CMU)の研究者たちは、ふと疑問に思った – トレーニングデータ数を増やしたらどうなるだろう?

データ数を増やした時に何が起きるのかをテストするため、Googleは3億のイメージからなる内部データセットを作成し、18,291のカテゴリでラベル付けした。データのラベル付けは、生のWeb信号とWebページ間のコネクション、ユーザのフィードバックを組み合わせた、ノイズの多い方法で自動的に行なった。手動でラベル付けしなかったため、ラベルの20%程度にはノイズが含まれている。
その結論は、トレーニングデータの多さは有効である、というものだ。自動ラベリングのためイメージのラベルにはノイズが多かったが、それでもアルゴリズムの精度は3%向上した。つまりは、データ規模の大きさがラベル空間のノイズに勝ったのだ。次のグラフに示すように、トレーニングデータの量に対してパフォーマンスが対数的に向上することも明らかになった。この研究を実施した研究者たちは、100万イメージの結果から生成されたモデルであっても、現在使用しているモデルを調整することによって、アルゴリズムの正確性にはまだ向上の余地があると考えている。
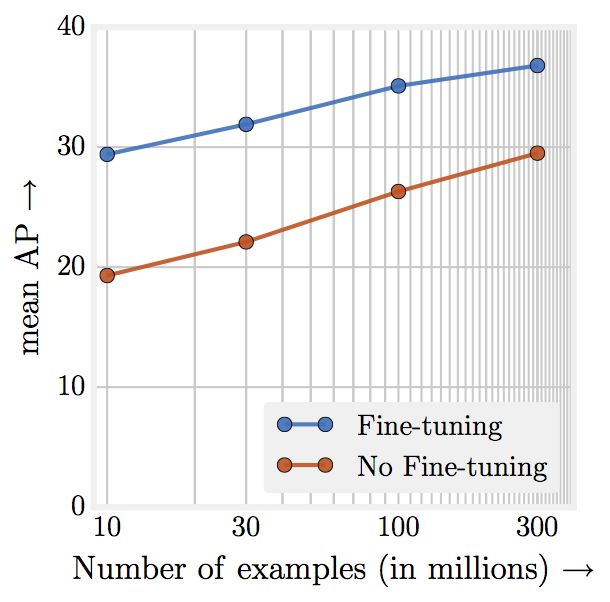
研究者たちがMicrosoftが開発したオブジェクト検出ベンチマークであるCOCOオブジェクト検出ベンチマークを使って、3億件でトレーニングしたニューラルネットワークをテストしたところ、平均精度で34.3から37.4という最高レベルの結果を達成した。GoogleとCMUは、トレーニング方法と結果をコンピュータビジョンに関するICCVカンファレンスで公開した。その内容についても、“Revisiting Unreasonable Effectiveness of Data in Deep Learning Era”という論文で、無償で提供されている。
この記事を評価
- 編集者評
- 編集長アクション