Researchers improved the state of the art results on several benchmarks with models trained on a generated data set with 300 million images instead of the 1 million normally used.
Many developers train their object detection algorithms using the ImageNet data set, which consists of 1 million images. Since 2011, no more images were added to this data set. However, the number of parameters in neural networks trained on this data set did increase, and so did GPU power used to train these models. The question Google researchers and scientists from the Carnegie Mellon University (CMU) asked themselves was: what happens if we increase the amount of training data?

To test what happens with more train data Google created an internal dataset of 300 million images, labelled with 18,291 categories. They labelled the data automatically in a noisy way, combining raw web signals, connections between web pages, and user feedback. As they did not manually label the images, about 20% of the labels is noisy.
The conclusion is that more training data indeed helps. Although the labels of images were noisy due to automatic labelling, the precision of the algorithm still improved by 3 percent. Apparently, the scale of more data overpowers the noise in the label space. They found that the performance increases logarithmically based on the volume of training data, which is depicted in the graph below. The authors of this research think that the accuracy of the algorithm can still be improved by adjusting the models they currently use, which were created based on results with 1 million images.
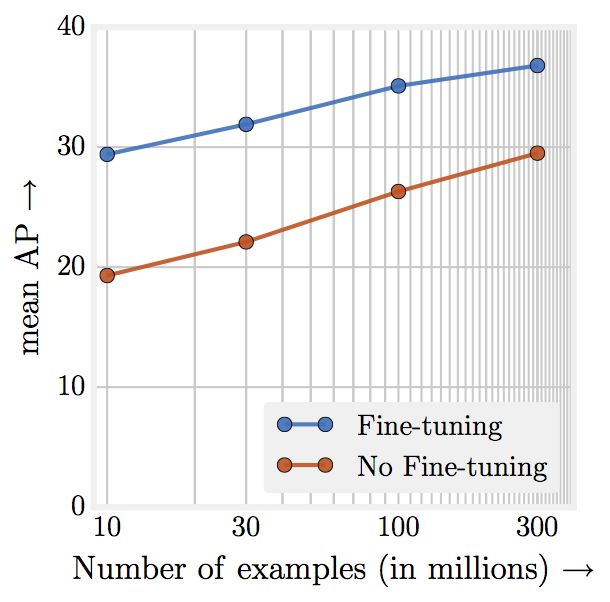
The researchers tested the neural network trained on 300 million on the COCO object detection benchmark: an object detection benchmark developed by Microsoft. On this benchmark they achieve state-of the art results, going from an average precision(AP) of 34.3 to 37.4. Google and CMU published the training methods and results at the ICCV conference on computer vision, they are also accessible for free in the paper Revisiting Unreasonable Effectiveness of Data in Deep Learning Era.