The Apache Software Foundation recently announced the General Availability of Log4j 2.0, containing many performance improvements over its predecessor Log4j 1.x. Years in the making, this release was written from scratch, and gained its inspiration from existing logging solutions such as Log4j 1.x and java.util.logging.
Log4j 2.0 introduces a new plugin system, support for properties, support for JSON-based configuration and automatic reloading of its configuration. It supports many existing logging frameworks, including SLF4J, Commons Logging, Apache Flume and Log4j 1.x, and provides a new programmer’s API.
Christian Grobmeier, Apache Logging PMC Member, first wrote about the new Log4j 2.0 in December 2012. He described the modern API:
In old days, people wrote things like this:
if (logger.isDebugEnabled()) { logger.debug("Hi, " + u.getA() + " " + u.getB()); }The log4j 2.0 team thought about things like that and improved the API. Now you can write the same like that:
logger.debug("Hi, {} {}", u.getA(), u.getB());
Grobmeier goes on to describe more API improvements, including Markers and Flow Tracing. He also mentions the improved plugin architecture, enhanced configuration (with hot-reloading, JSON and properties) and how Log4j 2.0 addresses many deadlock issues from Log4j 1.x.
On Hacker News, many complained about the proliferation of logging frameworks for the JVM. Ceki Gülcü, author of many Java logging frameworks including Log4j, SLF4J and Logback, expressed his reasons for not liking the Apache model. Gülcü still remains a community member and continues on the PMC of Apache Logging.
In July of 2013, Grobmeier authored another post, titled Log4j 2: Performance close to insane. In it, he raves about how Remko Popma's "AsyncLoggers" were able to produce twelve times more logging throughput than other frameworks.
We speak of more than 18,000,000 messages per second, while others do around 1,500,000 or less in the same environment.
I saw the chart, but simply couldn't believe it. There must be something wrong. I rechecked. I ran the tests myself. It's like that: Log4j 2 is insanely fast.
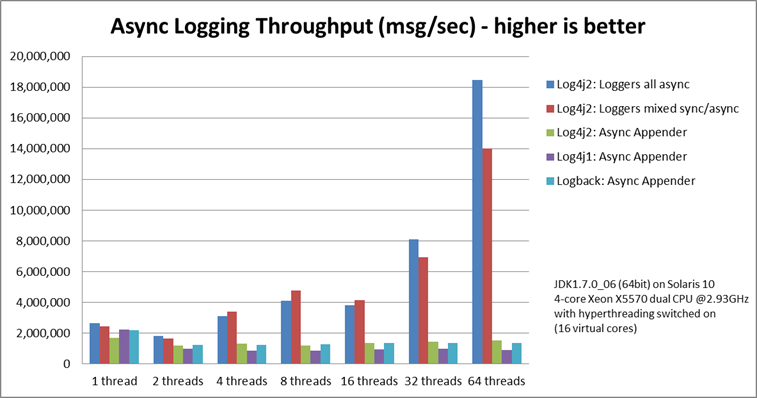
More information can be found in Log4j's async documentation.
Not everyone, however, is impressed with Log4j's async features. Michael Rose, Senior Platform Engineer at FullContact, penned the blog Overengineering: Log4j2's AsyncAppender. He concludes using this feature is not worth it:
I've concluded that the Log4j2's AsyncAppender, while neat, is just a shiny toy and there's really no appreciable difference for any sane application. Greatest respect for the Log4j2 team, but I really wish they'd focused on building a single, cohesive, next-generation Java logging framework rather than adding yet another logging framework to the mix.
Logback , however, natively implements SLF4J (the de-facto standard for classpath-binding logging) and has more than acceptable performance (especially with locations turned on). It continues to be my logging framework of choice. It's easy to use and I've never run into any issues with it.
If nothing else, avoid Log4j 1.x (Or really anything but Log4j2 or Logback) like the plague. In any system with load, you'll eventually find it causing contention issues.
Migrating from Log4j 1.x to 2.0
I recently upgraded Log4j 1.x to 2.0 in my AppFuse application and found it difficult to get the Maven dependencies right. At the very least, you'll need the log4j-core JAR (which depends on log4j-api). If you're using it in a webapp, you'll also need log4j-web as a dependency. To get Velocity 1.7 to work with Log4j 2, I had to add log4j-1.2-api. To make Spring work, I had to add log4j-jcl (because it uses commons-logging). For libraries that relied on SLF4J, including log4j-slf4j-impl was a must. To get Hibernate to work with Log4j 2.0, I had to upgrade to upgrade to JBoss Logging 3.2.0.Beta1.
You may need to exclude older Log4j dependencies from some dependencies. If you're using Maven, the following command is a good way to display dependencies that you might need to exclude.
mvn dependency:tree | grep log
The final step I needed to do was rename my log4j.xml files to log4j2.xml and refactor them to match its new configuration.
Summary
The new Log4j 2.0 release has many performance improvements, a new plugin system, and many improvements to its configuration settings. Some users may or may not find these enhancements compelling enough to upgrade, or move from an existing logging solution.