Since announcements late last year about Google open-sourcing TensorFlow, the company’s open-source library for machine learning, and previous coverage at InfoQ, the data-science community has had an opportunity to try out TensorFlow for their own projects.
Databricks’ Tim Hunter demonstrates TensorFlow-generated model selection and at-scale neural network processing with Spark.
Hunter describes an artificial neural network as mimicking the neurons in the visual cortex of the human brain, which when adequately trained can be used for processing complex input data like imagery or audio.
Hunter detailed how he ran TensorFlow on various Spark configurations to parallelize hyperparameter tuning. Hunter stated that TensorFlow, currently available with Python and C++ support helped “automate the creation of training algorithms for neural networks of various shapes and sizes” for the purpose of training a neural network to process large amounts of data with high accuracy and optimal runtime performance.
{kind=link}
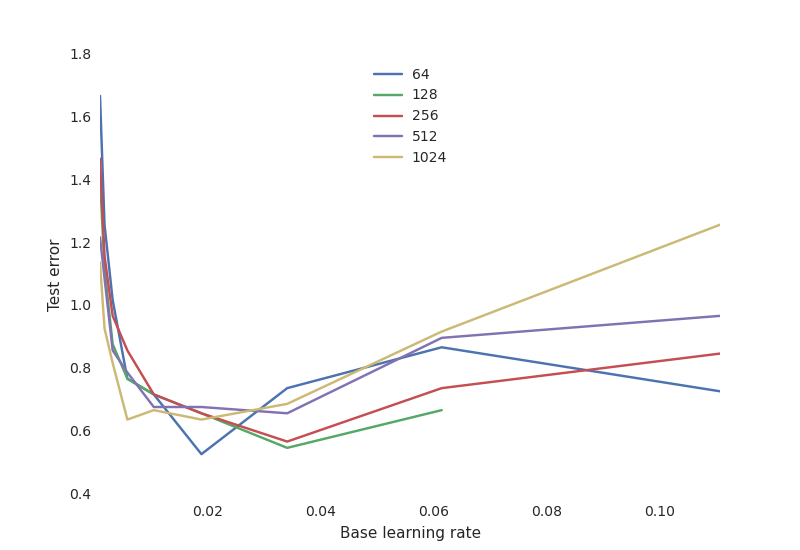
Some hyperparameters Hunter noted are the number of neurons in each layer and the learning rate, which are separate from the training algorithms used on the neural network itself.
How well tuned the hyperparameters are for a given algorithm affects run time and model accuracy. The hyperparameter settings were compared against each other to correlate variables like the number of neurons in each layer and test error. Hunter noted:
{kind=link}
The learning rate is critical: if it is too low, the neural network does not learn anything (high test error). If it is too high, the training process may oscillate randomly and even diverge in some configurations.
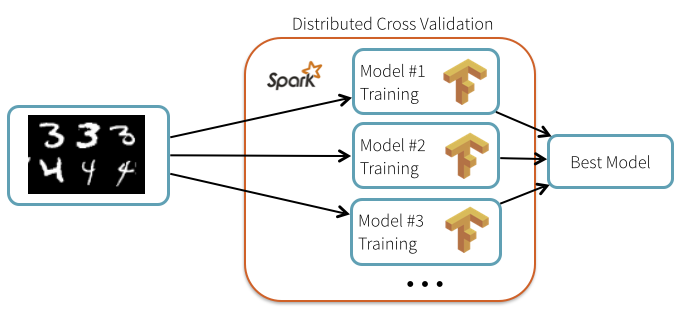
Databricks set up an experiment to measure the effects of Spark-based TensorFlow training algorithms on neural network accuracy and run time performance. The experiment consisted of a default hyperparameter group, a number of hyperparameter permutations, a test data set, and a single node, two-node and 13-node Spark cluster.
To address the need to discover the optimal hyperparameter set Hunter employed Spark to distribute processing the TensorFlow generated sets to concurrently test model efficacy.
Hunter described using Spark as a way
to broadcast the common elements such as data and model description, … then scheduling the individual repetitive computations across a cluster of machines in a fault-tolerant manner.
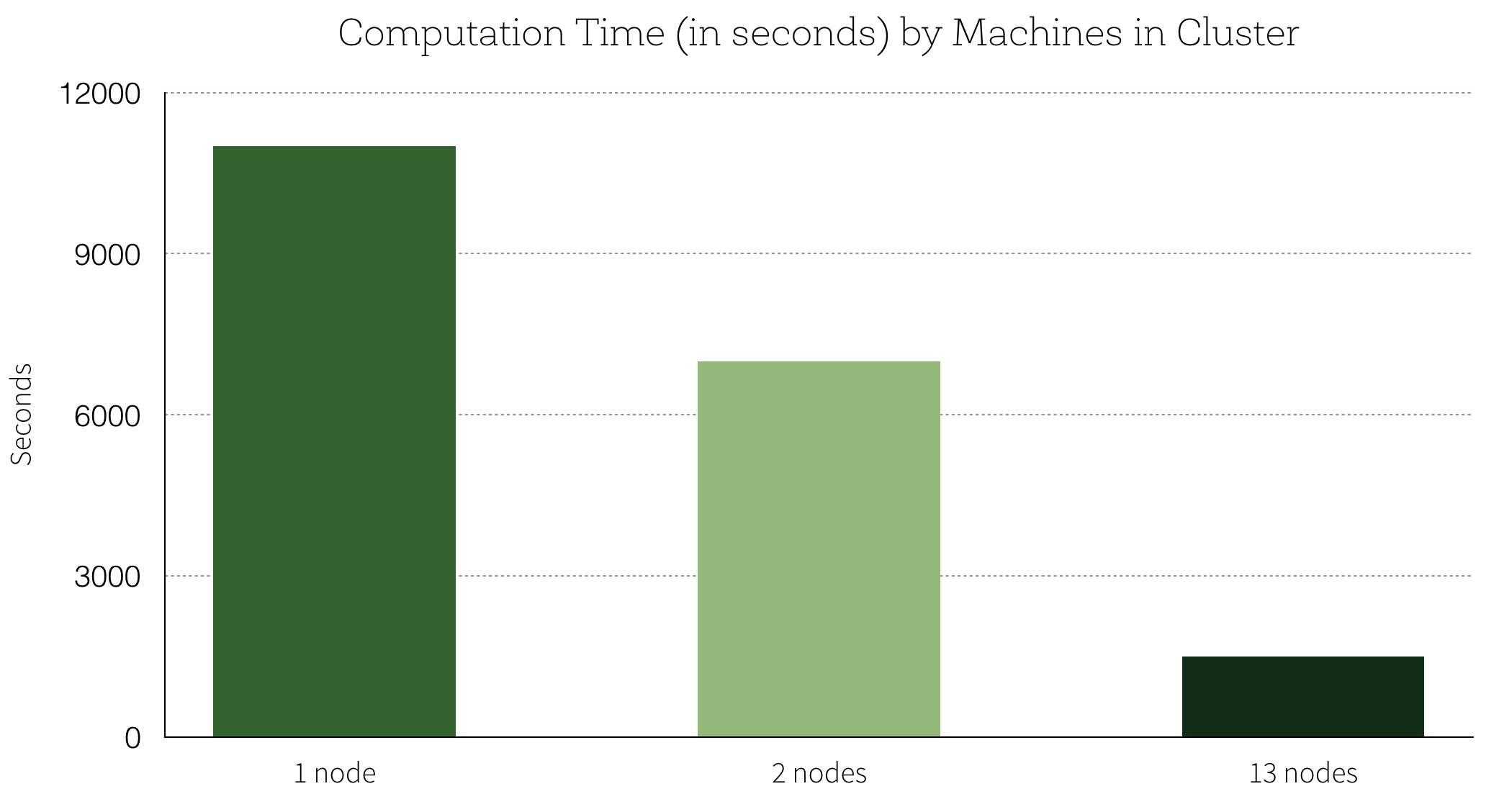
Hunter noted the improvements in model accuracy and runtime with Spark integration stating
{kind=link}
Even though the neural network framework we used itself only works in a single-node, we can use Spark to distribute the hyperparameter tuning process and model deployment …
Distributing algorithm selection cut down training time, improved accuracy by 34 percent over the control hyperparameter set and gave Databricks a better understanding of various hyperparameters’ sensibility.
It sped up model validation seven times over single node model validation by allowing multiple algorithms generated by TensorFlow to be tested concurrently or as Hunter noted “[in an] embarrassingly parallel” manner across the nodes for each of the three Spark clusters mentioned.
Once the best-fit model was selected and the neural network trained, the neural network was then deployed to Spark to run on large data sets.
Databricks didn't note the specific hardware implementation, but some indication may be made based on the iPython notebooks Hunter made available for reproducing the experiments, as well as Databricks’ cluster options for customers.
The ability to scale model selection and neural network tuning by adopting tools like Spark and TensorFlow may be a boon for the data science and machine learning communities because of the increasing availability of cloud computing and parallel resources to a wider range of engineers.