LinkedIn open-sourced their Kafka Monitor at Kafka Summit last April under the Apache 2.0 license and recently published details about the architecture and motivations behind why they built it in the first place. LinkedIn briefly mentioned the Kafka Monitor earlier this year in a publication about their overall Kafka use, but didn't detail the semantic components of the project or the motivations behind it.
{kind=link}
The motivations for Kafka Monitor are threefold:
- A need to monitor and test Kafka deployments while keeping track of main trunk stability so they could catch issues in the ongoing changesets as early as possible
- A need to continuously monitor SLA's on production clusters and continuously run regression tests on test clusters
- Existing monitoring frameworks didn't fit their use-cases around extensibility, modularity and a need for custom client libraries
Site Reliability Engineering had monitored such metrics as bytes-in-rate, offline-partition-count, and under-replicated-partition-count to determine Kafka-cluster availability and overall systems health in the past. The challenge though was that such raw values don't in and of themselves indicate whether or not the cluster is truly available in terms of end-user experience.
LinkedIn mentioned a Microsoft project and the Netflix Kafka monitoring covered in their Keystone Pipeline publications as potential candiates for their Kafka monitoring needs but decided didn't fit their use-cases.
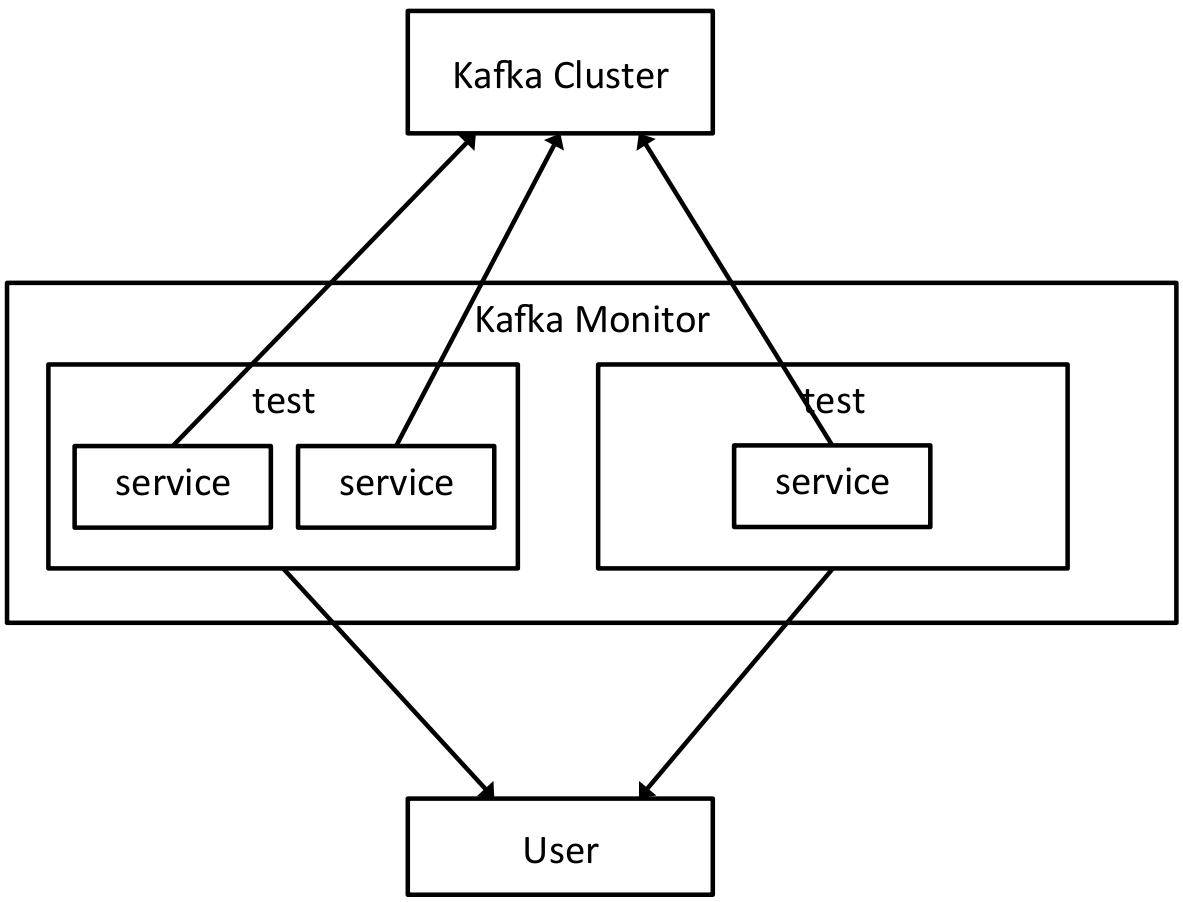
Kafka Monitor allows developers to compose modules that emulate various failure scenarios like GC pauses, broker hard-kills, rolling bounces, disk failures, and collects metrics around service behavior during runtime as the scenarios play out. Error rates in the producer service are determined by incrementing a metric every time an exception is thrown and caught when a producer creates a message. The consumer service tracks an incremental index counter segmented by Kafka partition, as well as timestamps in the message payload to measure message loss rate, duplication rate, and end-to-end latency.
The Kafka Monitor instance runs in a single Java process, runs multiple tests and sits between the user or consuming service and the Kafka cluster itself. Runtime metrics gathered by Kafka Monitor include production rate from producer services, consumer rates from consumer services, message loss, message duplication, and end-to-end latency. Multiple Kafka Monitors run a multitude of test scenarios across multiple Kafka clusters, which can be mirrored by a replication service to capture total cross-cluster latency metrics.
{kind=link}
Kafka Monitor supports Java natively but also provides a REST interface for non-JVM languages. Of particular significance to the open-source community, LinkedIn's Dong Lin stated that
We generally run off Apache Kafka trunk and cut a new internal release every quarter or so to pick up new features from Apache Kafka. A significant benefit of running off trunk is that deploying Kafka in LinkedIn's production cluster has often detected problems in Apache Kafka trunk that can be fixed before official Apache Kafka releases.
Given their close-coupling with the main Kafka trunk LinkedIn plans on implementing similar systems tests to those included in the Kafka project itself that get run on every code check-in. LinkedIn wants to integrate the Kafka Monitor with a fault injection framework like Simoorg as well as with Graphite or similar framework to allow all metrics generated across Kafka Monitor clusters to be viewed through a single web service.
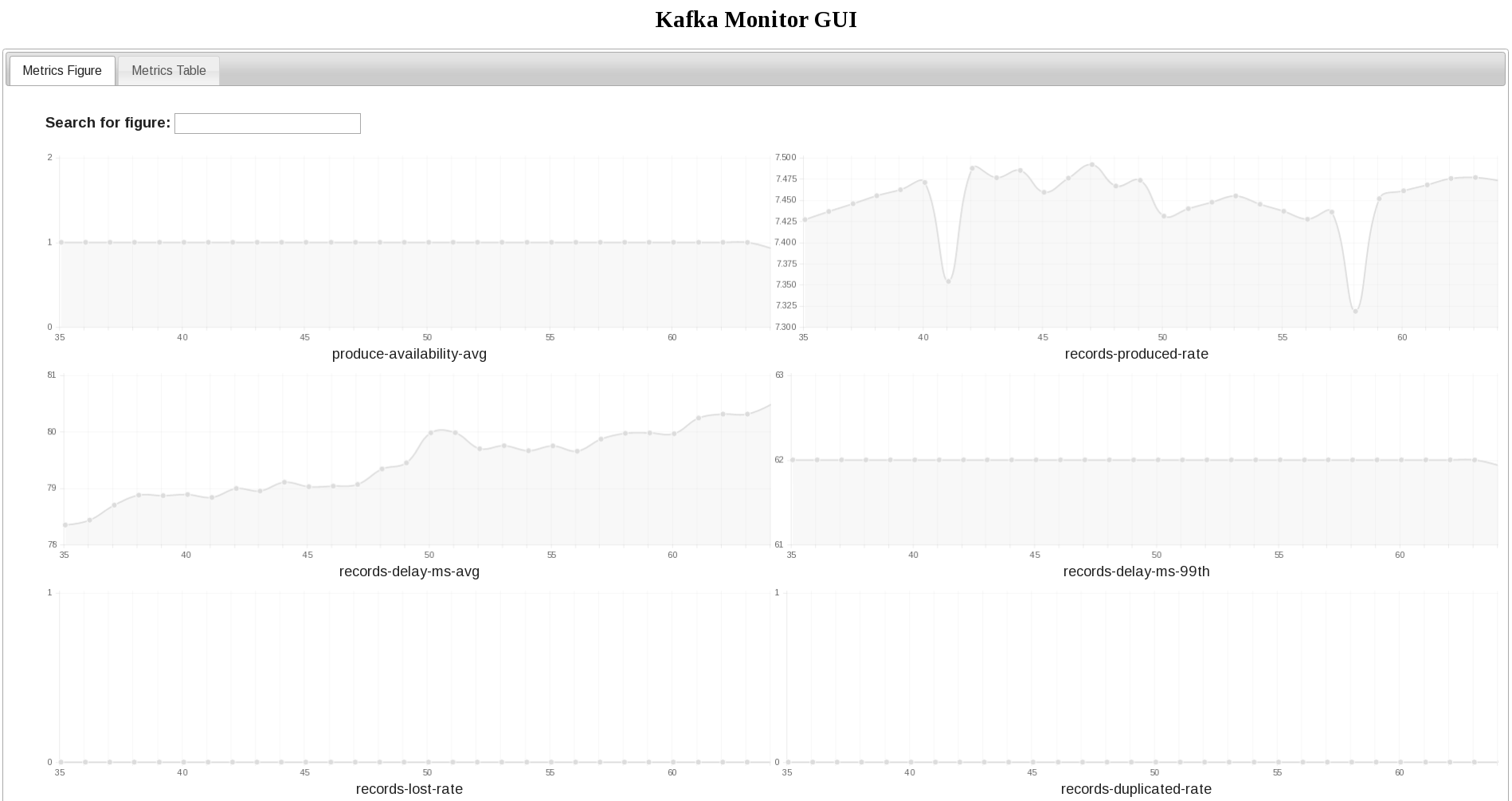
LinkedIn also briefly mentioned how to setup a basic monitor that would emit and visualize core metrics. The details can be found on their github page.
{kind=link}