Recently, Google announced that its second- and third-generation Cloud Tensor Processing Units (TPU) Pods are now publicly available in beta. These pods allow Google's scalable cloud-based supercomputers with up to 1,000 of its custom TPU to be publicly consumable, which enables Machine Learning (ML) researchers, engineers, and data scientists to speed up the time needed to train and deploy machine learning models.
Google announced the first generation custom TPU’s at the Google I/O event in 2016, and started offering access to them as a cloud service for customers. The follow-up, the second-generation TPU, made its debut in 2017, and the liquid-cooled TPU v3 was presented at Google’s I/O keynote last year. Until the recent Google I/O 2019 a few weeks ago, the single TPU v2 and TPU v3 were publically available as individual devices in the Google Cloud. Now the TPU v2 and TPU v3 hardware come as robust interconnected systems called Cloud TPU Pods.
A single Cloud TPU Pod can have more than a 1,000 individual TPU chips which are connected by an ultra-fast, two-dimensional toroidal mesh network. The TPU software stack uses this mesh network to enable many racks of machines to be programmed as a single, giant ML supercomputer via a variety of flexible, high-level APIs.

Developers can now access either a full TPU pod or slices of a pod for specific workloads such as:
- Models dominated by matrix computations
- Models with no custom TensorFlow operations inside the main training loop
- Models that train for weeks or months
- Larger and very large models with very large effective batch sizes
A Cloud TPU Pod brings the following benefits relative to single Cloud TPU:
- Increased training speeds for fast iteration in R&D
- Increased human productivity by providing automatically scalable ML compute
- Ability to train much larger models than on a single Cloud TPU device
Zak Stone, Google’s senior product manager for Cloud TPUs, wrote in a blog post about the announcement:
We often see ML teams develop their initial models on individual Cloud TPU devices (which are generally available) and then expand to progressively larger Cloud TPU Pod slices via both data parallelism and model parallelism.
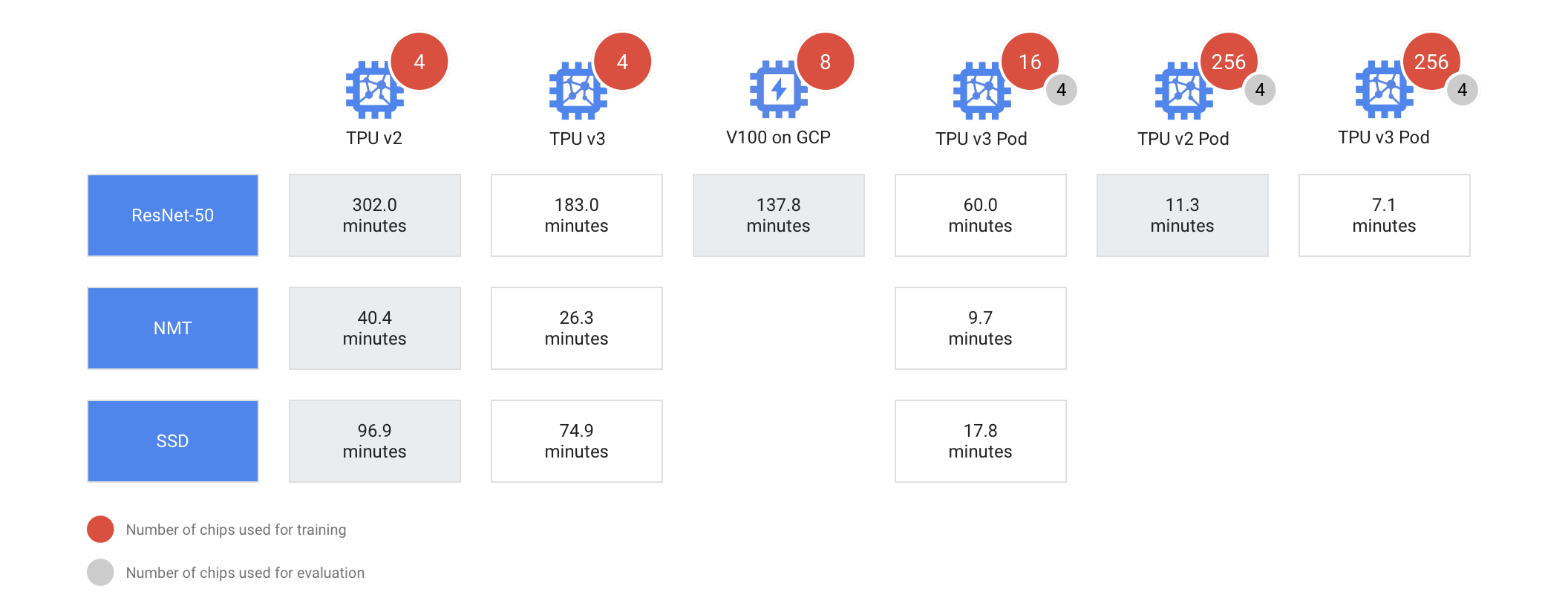
With the liquid-cooled v3 TPU users will get the most performance. In a pod each TPU can deliver up to 100 petaFLOPS. As a comparison, a TPU v2 Pod will train the ResNet-50 model in 11.3 minutes while, a v3 Pod will only take 7.1 minutes. Moreover, according to Google, the TPU 3.0 pods are eight times more powerful than the Google TPU 2.0 pods.
Source: https://techcrunch.com/2019/05/07/googles-newest-cloud-tpu-pods-feature-over-1000-tpus/
Besides Google, Amazon, Facebook and Alibaba have been working on processors to run AI software – betting their chips can help their AI applications run better while lowering costs, as running hundreds of thousands of computers in a data center is expensive. Still, Google is the first of the tech giants to make such a processor publicly available. Peter Rutten, research director at IDC, said in a TechTarget article:
Apart from what the other vendors are planning, the Google TPU Pods appear to be extremely powerful.
Currently, a variety of customers, including eBay, Recursion Pharmaceuticals, Lyft and Two Sigma, use Cloud TPU products.
Lastly, both Cloud TPU v2 and v3 devices price in the single digits per hour, while Cloud TPU v2 and v3 Pods have different price ranges. More details are available on the pricing page.