Twitter's ad pacing algorithms were initially part of an ad-serving monolith. Later, Twitter's engineering extracted them into a separate service to facilitate its development. Being an important service, it needs to be very reliable. An article was published recently describing how they built a reliable service by making economical design choices on managing different failure scenarios.
Twitter needs ad pacing algorithms to distribute advertising campaign budgets to maximise the campaign's reach and Twitter's revenue from said ads. Running them as an independent service brings advantages. For example, it becomes possible to run a time-based pacing model. Also, resources are saved because calculations are not repeated with each request, and development is accelerated since the new service is no longer hostage to the monolith's feedback cycle.
Since the service uses a time-based pacing model, campaign parameters are calculated every 10 seconds based on the campaign's spend and budget data. Once calculated, they remain in storage for other services to use. Pacing parameters are recalculated when ads are served from a campaign, and its spend data is updated.
Given that pacing is a critical component of Twitter's ad-serving mechanism, it must be resilient in the event of failure. Pacing parameters change constantly; therefore, they cannot be cached. Falling back to default parameters is not a viable solution because its consequences on other dynamic services could result in undesirable consequences for the business.
Considering that pacing parameters need to be updated every 10 seconds, building a single-instance service with sufficient memory and fast enough to meet such a deadline at Twitter's scale is impossible.
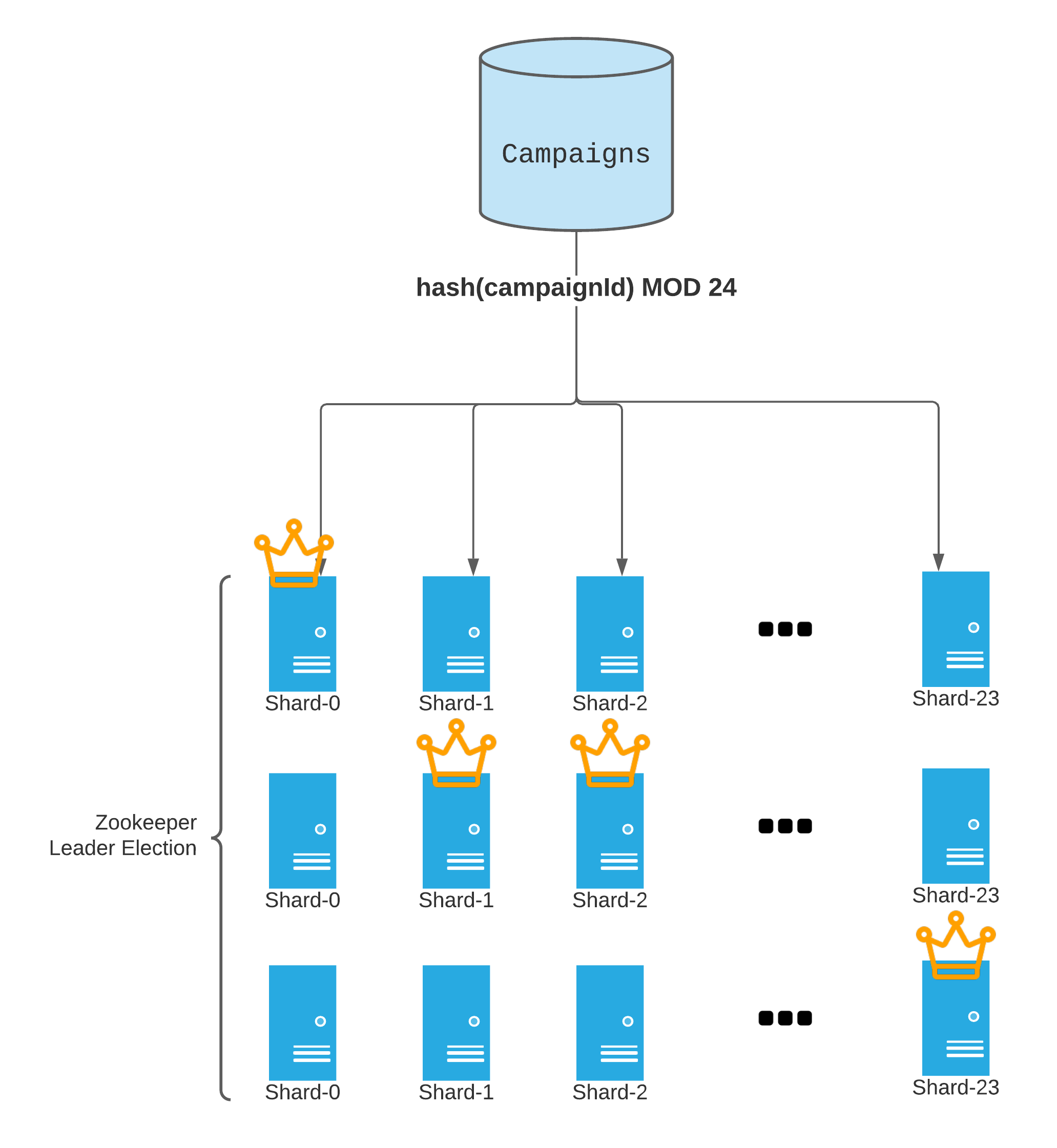
Computations must, therefore, be distributed. A sharded design was chosen, distributing campaigns using a 24-way hashing on their account identifiers. The number of shards was selected for consistency with other Twitter services and can be scaled up if necessary.
Ad campaigns can only spend their budget if they win at an auction. Since pacing parameters also depend on that budget, the auction process influences all the participating campaign’s pacing parameters. Because pacing parameters are calculated at 10-second intervals, the following calculation reflects any influence from the previous auction process.
Inter-shard communications are thus unnecessary, keeping the architecture simple.
One common error scenario is the failure of a service instance. Each shard's group of service instances elects a leader through a managed Zookeeper service to prepare for this scenario, hence the choice to run three instances per shard. Only the leader writes pacing parameters to storage, but all instances run the calculations to keep their internal states close to the leader's. The election mechanism ensures that a leader is always available if one or two service instances fail.
The low probability of all three instances failing makes it unnecessary to take preventive steps in case of total shard failure.
Another scenario that also is very unlikely is a failure to elect a leader. Given its low probability, Twitter's engineering team decided to handle such cases manually. They "have not had to intervene [in leader election] in two years of running the service".
Twitter ads are served from multiple data centres (DC). Ad pacing parameters are read and calculated from the same data centre, meaning there is one ad pacing service per data centre.
Data centres are designed for resilience, so failures are unlikely. However, if a failure occurs in one data centre and the services depended on by the ad pacing service fail to recover, a replication mechanism exists so writes can be directed to a different data centre.
Since the probability of a data centre failure that is too slow to recover from or is even unrecoverable is low, there is no automatic activation of the replication mechanism. It, too, can only be activated manually. "During (...) two years of operating the pacing service, there was only one time that [they] needed to flip the switch to writing cross DC."
The authors conclude that "it is impossible to design a service for all faults and design for exhaustion. Finding a balance between the complexities of fault tolerance and the likelihood of various faults is important."