Key Takeaways
- Software tests in large projects often have long runtimes, which leads to several issues in practice like costly delays or possible waste of resources.
- Long test run times cause long feedback round trips to developers; machine learning can be used to give almost instantaneous first feedback to developers while the tests are still running.
- The same machine learning system can be used to optimize test suites’ execution order such that the suites arrive at the first errors quicker; this can save resources of either time or physical machines.
- Data quality is important in any use case; for the above, the possibility for semantic integration, i.e. for linking heterogeneous data sources, is a necessity. However, this is worth it in and of itself, as it e.g. enables analyzing dependencies between data sources, which in turn leads to a better understanding of one's organization.
- In multi team environments, assigning defects to the correct team may be cumbersome; linking test logs and change management data sources can help with this by exposing similar past defects and their assignees.
Software testing, especially in large scale projects, is a time intensive process. Test suites may be computationally expensive, compete with each other for available hardware, or simply be so large as to cause considerable delay until their results are available. In practice, runtimes of hours or even days can occur. This also impacts developers; waiting too long for a test result potentially means having to re-familiarize themselves with their own code should a bug be detected.
This is far from an academic problem: Due to the sheer amount of builds and tests, the Siemens Healthineers test environment for example in parallel executes tests with a summed duration of 1-2 months for just one day of real-world time. Scaling horizontally, while possible, is limited by available hardware and not very efficient. Therefore, different ways of optimizing test execution, saving machine resources, and reducing feedback time to developers are worth exploring.
Predicting Test Results at Commit Time
The classical software development processes produce a lot of data that can help. Especially source control systems and test execution logs contain information that can be used for automatic reasoning with machine learning; combining data from these, specifically which test result was observed on which code revision, creates an annotated data set for supervised learning.
Since this annotation can be done automatically, no human in the loop is necessary, meaning one can quickly gather large amounts of training data. These can then be consumed by typical supervised learning algorithms to predict failing tests for a given commit.
Implementing this approach using decision trees (see scryer-ai.com and the InfoQ article Predicting Failing Tests with Machine Learning for more information) led to a system that was able to predict the results of 79,361 real-world test cases with an accuracy of on average 78%; each test case has its own model, which is trained several times on different parts of the available data to make visible the effects of data selection. The accuracies of each run are aggregated by macro-averaging. The distribution of mean accuracies for all test cases can be seen in Figure 1.

Figure 1: Accuracy of predicting test results
The models have a median mean accuracy of 0.78. While there are some test cases with low mean accuracy, most of them are outliers, i.e. they constitute the minority. This is also evidenced by the 25%-quantile of 0.7, meaning that three quarters of the test cases have models with 70% mean accuracy or better. This satisfies the project’s initial use case of getting fast feedback without having to actually execute tests. In addition to running the tests and getting their results later, a developer can access the predictions within seconds of preparing a commit and take first steps according to the likelihood of tests failing.
Side Benefit of Data Integration: Reducing “Defect Hot Potato”
The necessary step of integrating source control and test result data opens up an “incidental” use case concerning the correct routing of defects in multi-team environments. Sometimes there are defects/bugs where it is not clear which team they should be assigned to. Typically, if you have more than two teams it can be cumbersome to find the correct team to take care of a fix. This can lead to a kind of defect ping-pong between the teams because no one feels responsible until the defect is finally assigned to the correct team.
Since the Healthineers data also contains change management logs, there is information about defects and their fixes, e.g. which team performed a fix or which files were changed. In many cases, there are test cases connected to a defect - either existing ones when a problem is found in a test run before release or new tests added because a test gap was identified. This allows tackling the problem of this “defect hot potato”.
Defects can be related to test cases in several ways, for example if a test case is mentioned in the defect’s description or if the defect management system allows explicit links between defects and test cases. Defects are defined to be “similar” if they share test cases. If a new defect comes in, similar defects that were fixed in the past are aggregated by the teams that performed the fix. Quite often, there is a team that is most likely the correct assignee by a large margin - e.g. “team A fixed 42 similar defects, team B fixed 7,” and so on.
This analysis does not even need any machine learning - it only requires a couple of queries on the data gathered for prediction (see above). Evaluating this approach on 7,470 defects from 92 teams and returning the top three most likely teams leads to a recall of around 0.75, meaning that the correct team will be retrieved with 75% probability - which in turn means a person assigning tickets usually only needs to consider a handfull of teams instead of the full 92.
As an aside, there’s an interesting larger principle at work here - ML folk wisdom tells us that 80% of the work in ML projects consists of data gathering and preparation. Since that effort has already been expended, it might be worth it to check for additional benefits beyond the original use case.
Using Predictions for Test Suite Optimization
Another use case, this time for the system’s output, is test suite optimization. Feeding a commit (or rather its metadata) into the system outputs a list of test cases with either a fail or a pass prediction for each. Additionally, each test case reports the accuracy of its previous training runs - roughly speaking, the system for example reports “According to its model, test case A will fail. Past predictions of test case A’s results were correct in 83% of all cases”. It does this for all test cases known to the system. Interpreting the reported accuracies as probabilities of the predicted outcome (which is not completely the same, but close enough for this use case), we can order the list of test cases by probability of failure.
Thus, we can also switch a test suite’s order to execute its test cases in descending order of failure probability, which increases the likelihood of finding a failure sooner. We tested this on around 33000 real-world runs of test suites (incorporating almost 4 million distinct test executions) and compared the time it took for example to arrive at the first fail result. We found that with the actual order, test suites would take a median of 66% of their total execution time to arrive at the first failure. With prediction-based reordering, this reduces to 50% (see Figure 2). There are cases where the reordering increases the test run’s time (as expected - no model is 100% correct), but the average reduction, i.e. the overall effect, means this allows saving computation time e.g. in case of a gated check-in. Directly comparing the two approaches, the predicted order wins in ~57% of the cases, ~10% are a tie, and the traditional order only wins in 33% of cases - which is good, because it means we are able to save time noticeably more often than not (see Figure 3). This effect gets more pronounced the more actual fail results occur in a test run, but even if there is only one failure, the predicted order on average beats the actual order.
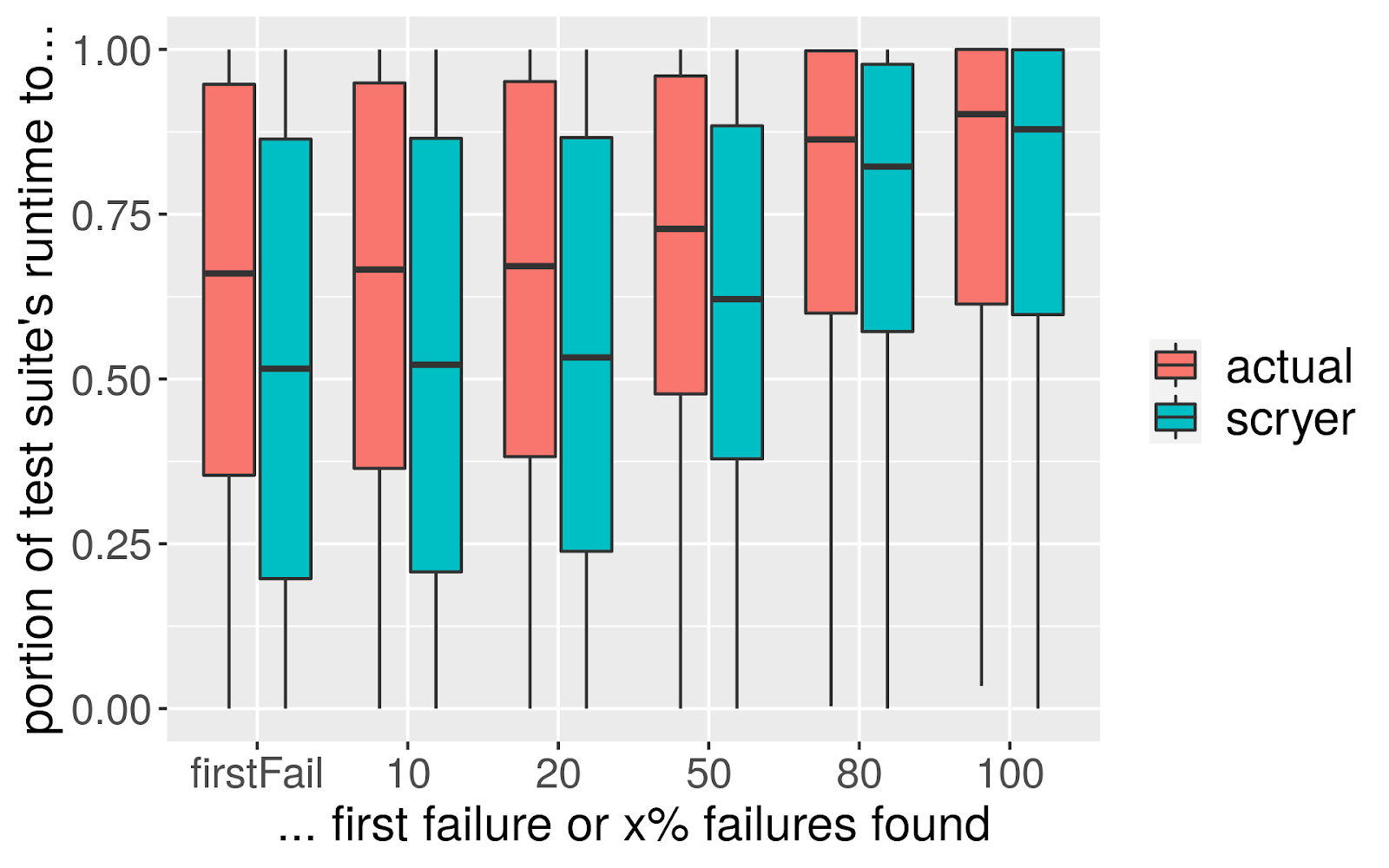
Figure 2: Time taken to first failure / to 10/20/50/80/100% failures found
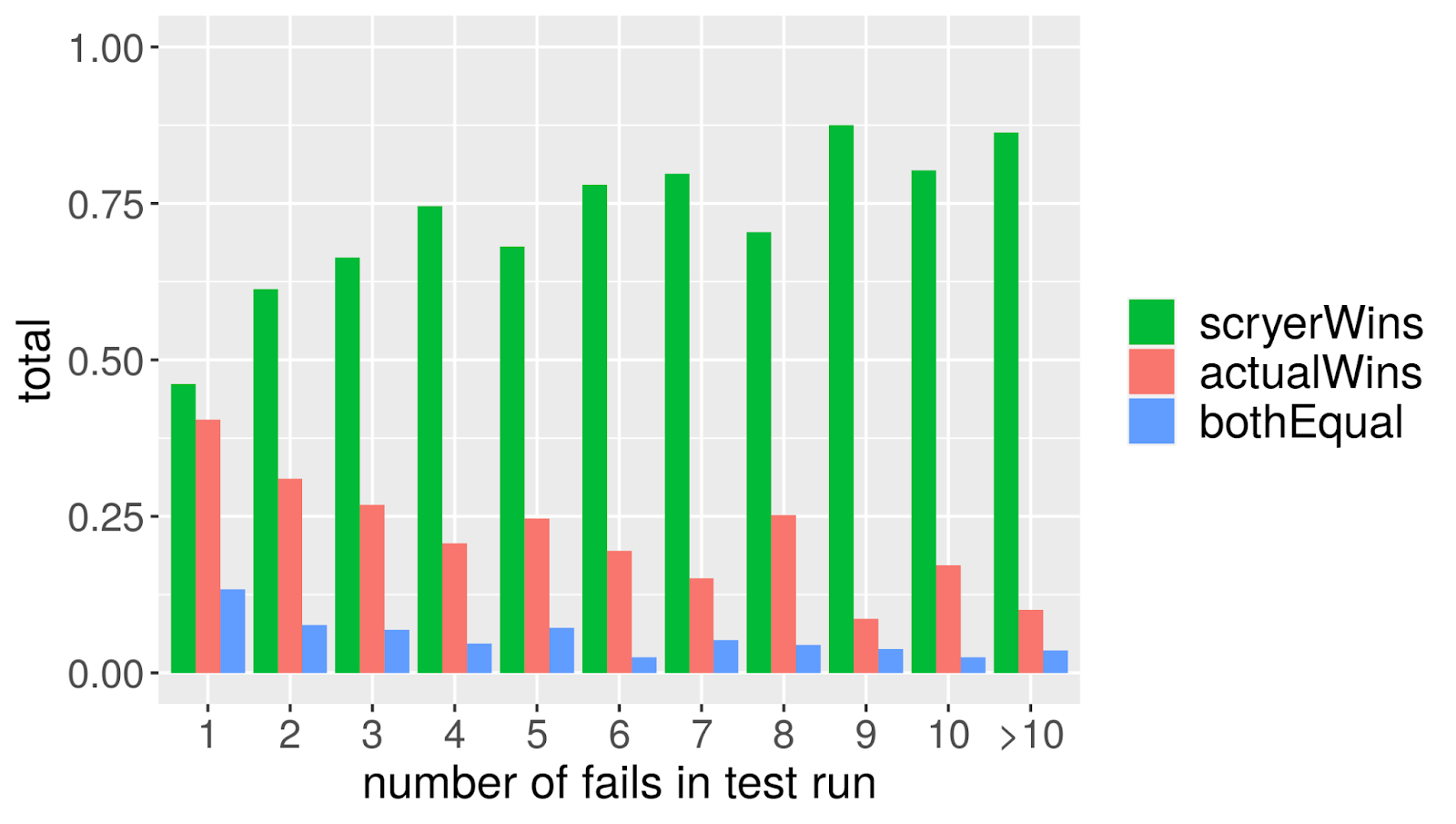
Figure 3: How often does the “predicted” order win over the actual order?
Simulating real-world application by summing up and comparing the total run times for predicted order and actual order shows that the predicted order is able to reduce run times by ~10%. To give these relative values an absolute number: For the Siemens Healthineers test executions in the test data, this translates to a reduction of 418.25 hours of runtime. In practice, this means that the amount of test machines can be reduced, leading to less costs for resources or administrative tasks.
Towards Practice
The evaluation results described above show that the approach works on real-world data.
Moving from the evaluation phase to putting the results into practice shifts the focus from rapid experimentation to engineering. The specific systems used for source control and test result storage vary, which is why a connector to Scryer’s API necessarily is dependent on the domain or even on specific customers (denoted by “Arbitrary API” in Figure 4).

Figure 4: Data Ingestion
Once connected to Scryer’s REST API, data can be ingested continuously in the correct format for machine learning.
At the other end of the pipeline, inference REST endpoints expose the trained models to interested parties, e.g. IDE plugins for feedback for developers or test schedulers for test suite reordering (see Figure 5).

Figure 5: Inference
The ingestion step requires explicit linking of source control and test results - which in and of itself may lead to new ways of thinking about data present in one's organization and potentially opens up new ways of analyzing data. As an example, having all test results in a unified database allows checking for tests that never fail during the time range present in the data. These may be candidates for scrutiny, lower priority in test suites, or possibly even deletion. Having source versions attached to tests also enables easy monitoring of flaky tests, i.e. tests that show varying outcomes on the same source code.
What are the key learnings?
For all of the above, data quality is key. Over the course of the project this especially meant changing how the different data sources already in place are connected; generally speaking, in larger projects there likely are several independent data sources as there will be different tools for different aspects. For many interesting analyses, and specifically for machine learning, it is important to ensure the traceability between the different data sources. This may even mean building an overarching domain model on the collected data or including extra parsing and mining steps to discover relationships between data.
Another aspect concerns scaling; in our case how the system evolved from a single process single thread application to multi-threaded, then multi-process and lastly multi-container. For the experimentation stage, scripted data collection mixed with analysis and ML is probably fine. When moving towards production however, there is a need for scalability to be able to digest the incoming amount of data. This also requires keeping the different items in the pipeline independent of each other to ensure that separate jobs cannot interfere with each other.
On the “people side” of things, the peculiarities of rolling out new tools using a new or currently hyped technology is worth considering. Especially when rolled-out to tech people, they are much more interested in how the tooling works instead of what benefits it brings them in their daily life. So in the beginning the explanation of how it works and what is actually processed is very important. Applying classical change management techniques is helpful here.
And last but not least, have a look at the data sources in your organization. Typically, there is gold quite near to the surface. You do not need to be a data mining expert - only a higher level view on what data is already there and how it could be connected may already be sufficient to suddenly be able to answer very pressing questions for your development cycle. This is beneficial whether you apply machine learning or artificial intelligence approaches or not.