Google's DeepMind announced the WaveNet project, a fully convolutional, probabilistic and autoregressive deep neural network. It synthesizes new speech and music from audio and sounds more natural than the best existing Text-To-Speech (TTS) systems, according to DeepMind.
Speech synthesis is largely based on concatenative TTS, where a database of short speech fragments are recorded from a single speaker and recombined to form speech. This approach isn't flexible and can't be adjusted to new voice inputs easily, often resulting in the need to completely rebuild a dataset when there's a desire to drastically alter existing voice properties.
DeepMind notes that while previous models typically hinge around a large audio dataset from a single input source, or single person, WaveNet retains its models as sets of parameters that can be modified based on new input to an existing model. The approach, known as parametric TTS implements sets of parameter-fed models to generate speech characteristics like tone and inflection, which are fed back into the model for refinement. This is in contrast to previous methods that used pre-generated raw audio fragments to train a model. WaveNet's Phoneme, word and sentence ordering parameters for generating meaningful word and sentence structure are separate from parameters that drive vocal tone, sound quality, and inflections of phonemes. This gives WaveNet the ability to generate sequences of language-like sounds, but without structure that would otherwise give the sound any meaning.
"Because the model is not conditioned on text, it generates non-existent but human language-like words in a smooth way with realistic sounding intonations... We observed that the model also picked up on other characteristics in the audio apart from the voice itself. For instance, it also mimicked the acoustics and recording quality, as well as the breathing and mouth movements of the speakers."
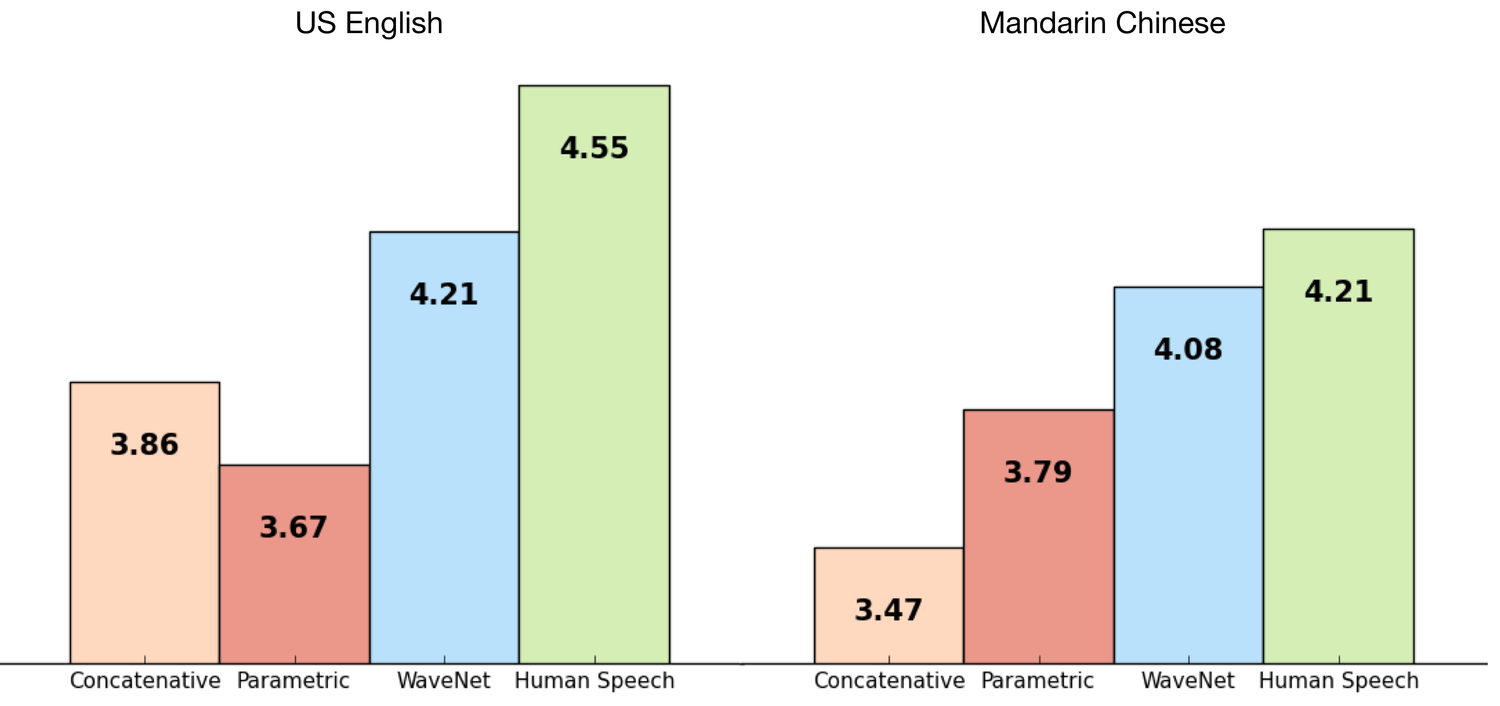
Listeners rate the WaveNet-generated audio as significantly more natural sounding than the best parametric and concatenative systems for both English and Mandarin. DeepMind details the experimental design in their paper, noting that:
"For the first experiment we looked at free-form speech generation (not conditioned on text). We used the English multi-speaker corpus from CSTR voice cloning toolkit (VCTK) (Yamagishi, 2012) and conditioned WaveNet only on the speaker. The conditioning was applied by feeding the speaker ID to the model in the form of a one-hot vector. The dataset consisted of 44 hours of data from 109 different speakers… For the second experiment we looked at TTS. We used the same single-speaker speech databases from which Google’s North American English and Mandarin Chinese TTS systems are built. The North American English dataset contains 24.6 hours of speech data, and the Mandarin Chinese dataset contains 34.8 hours; both were spoken by professional female speakers."
Naturalness scores are captured on a 1 to 5 scale for human-speech using a blind test consisting of Concatenative TTS, Parametric TTS, WaveNet and human speech audio samples, where human-speech is used in the control group. Listeners are subjected to audio samples and have to provide a score for each sample without knowing which of the four sources the audio comes from. The dataset for the paper consists of over 500 ratings from 100 test sentences and is used to compute a Mean opinion score (MOS), where WaveNet's naturalness rating is only surpassed by that of human speech audio samples.
{kind=link}
DeepMind also demonstrates how some of WaveNet's core learning abstractions can be used to synthesize music from an audio training data set. Questions abound around the long-term implications for speech synthesis and what’s described as AI by some. It's unclear at this time what core languages or processing engine WaveNet is built with and no sample code is provided.