The Neo4j team recently released version 3.1 of the graph database which introduces causal clustering and new security architecture.
Causal clustering, developed based on the Raft protocol, enables support for large clusters and different cluster topologies for data center and cloud. It includes built-in load balancing which is handled by Neo4j Bolt drivers. The Neo4j database also supports new cluster-aware sessions, managed by the Bolt drivers, that help with the infrastructure concerns for developers.
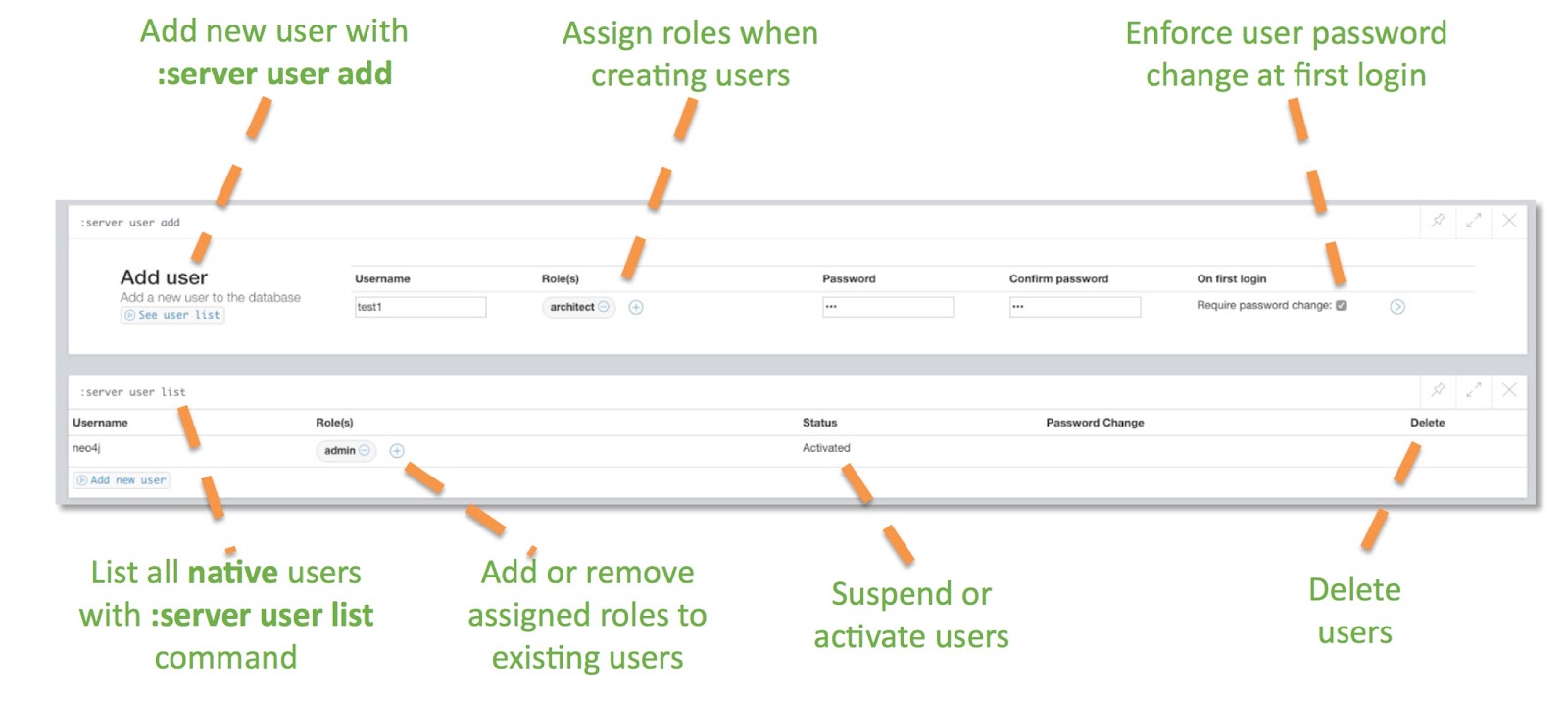
Security enhancements include features such as multiple users, role-based access control (comes with four predefined graph-global data-access roles: reader, publisher, architect and admin), query & security event logging, list and terminate running queries, and fine-grained access control.
Other features in the latest version include database kernel improvements with more efficient space management and a Schema Viewer that displays the graph model at the current point in time. Schema Viewer (shown below) uses database statistics for responsiveness and understanding & communicating the database contents between developers, admins and users.

InfoQ spoke via email with Michael Hunger, Head of Developer Relations at Neo4j about the new release of the graph database.
InfoQ: Can you discuss the new causal clustering feature in Neo4j 3.1 release and how it's different than the traditional clustering techniques?
Michael Hunger: The new Causal Clustering is a completely new architecture and approach to clustering a transactional database. It is independent of the previous implementation Neo4j High Availability (HA) and addresses several issues of the former approach.
The main focus is to provide total data safety, i.e. transactionally safe operations and availability. The approach builds on Neo4j’s historically strong transaction support via the Raft protocol and an asynchronous replication protocol to extend guarantees about reading your own writes even in very large clusters.
Eventual consistency – the default choice for most NoSQL databases – does not support this model. Despite read-your-own-writes being similar to how a standard Von Neumann computer works and so a familiar model, most NoSQL databases force developers to battle with consistency again and again in their applications.
For any clustered database, especially ones with eventual consistency, the "read your own writes" problem is tricky to solve, especially for user-facing applications. Usually it is handled with sticky sessions that redirect subsequent reads to the server that was written to, which limits scalability.
Causal Clustering goes far beyond eventual consistency to provide the simplest but most profound of guarantees: what you write you can subsequently read, even when the cluster is large.
Here are two additional resources on causal consistency (the consistency provided by Causal Clustering): The first is an outside paper and the other is background information on causal consistency.
The new Causal Clustering consists of two main architectural parts:
- A core of servers which accept writes and asserts data safety. This core forms the actual (active) cluster. It uses the Raft protocol to provide consensus on a number of cluster operations, which include quorum writes, cluster membership and leader information.
- An arbitrary number of read replica servers to allow scaling out graph queries.
The Neo4j operations manual has a section on cluster setup and operations including a step-by-step tutorial and detailed settings.
HA and data safety:
High availability, i.e. fail-over, is assured by the data safety provided by quorum writes within the core part of the cluster. Any write to the core will have to be acknowledged by a majority of servers before the commit returns as successful to the client. Raft demonstrates this is a safe action.
That's why in terms of the CAP theorem, a Neo4j Cluster is consistent and partition tolerant (CP). In the case of a network split, only the majority of members will continue to accept writes. If causal consistency with bookmarking is used, reading from the detached minority will not serve stale data, instead operations on orphaned instances will time out. If bookmarks are not used, the minority will serve the data it has. That is, Neo4j will never return stale or incorrect data. In pathological failure scenarios, the cluster eventually becomes read-only.
Neo4j Causal Clustering is implemented via a transaction-based bookmarking mechanism that allows you to get a bookmark token from your write operations. The bookmark represents a (strictly monotonic) transaction identifier for your write. For subsequent operations you then can use that bookmark to assure that you're only reading at or beyond the state of your transaction.
The official Neo4j Drivers are also cluster aware and support a built-in smart routing protocol (bolt+routing://any-server:port) that takes care of figuring out where to direct the current operation (write, read, bookmarked).
Scaling:
The core of a Neo4j cluster can also be deployed across data centers providing global scale. To enable end user facing applications, you can scale your cluster with an arbitrary number of read replicas. Those don't participate in cluster membership or write operations and are eventually consistent.
The aforementioned bookmarking feature still allows you to read your own writes. Read replicas can also be used to configure dedicated reporting instances or servers for graph compute operations.
For geographic availability, it is also possible to spread your core machines around different data centers. Although this means the commit path is across a WAN, the characteristics of Raft are such that it executes at the speed of the fastest majority of machines. Therefore if you have, say, data centers in New York, Boston and London, it’s likely the shorter network path between New York and Boston would be the limit on commit transactions, not the longer transatlantic path to London.
InfoQ: What is the Neo4j's new security foundation? How is it different from the security features already supported by Neo4j?
Hunger: Neo4j used to have a single built-in user, which offered protection from malicious attacks as the database was meant to run in protected networks.
Listening to our customers, especially in the financial and public sectors, we decided to add a strong security foundation for to Neo4j, starting in version 3.1
In this model, you have users with different and custom roles. The default roles include reader, publisher (read/write), architect (read/write/schema) and administrator, but you can also add your own roles and check against them in custom code (e.g., user-defined procedures). The authentication and authorization needs of this model are supported by either a built-in (native) implementation, an LDAP / Active Directory based implementation, or a custom implementation connecting to your own security infrastructure (e.g., Kerberos).
For native user management, the Neo4j Browser provides a UI to manage (create, suspend, delete) users and assign roles that are built upon procedures that are also useable in your own operational tooling. For the LDAP / Active Directory integration, there is a fine-grained configuration CAPA.
Currently, data-level security is provided via user-defined procedures that allow access to subsets of the data. Those procedures can be configured to be only available for users with certain roles.
The latest version of the database can be downloaded from Neo4j website.