Late last year Yelp open-sourced their Python and Apache Kafka-based data pipeline client library that provides an interface to publish and consume data pipeline topics. The earlier discussion covers Yelp’s data pipeline components and challenges with data integration coming from distributed services, namely the N+1 problem and Metcalfe’s Law.
{kind=link}
On motivation and justification for the data pipeline, of which the client library is just the latest component to be released, Yelp reports saving itself $10M US dollars a year by cutting over to the new data pipeline. Yelp’s vice president of engineering Jason Fennel noted:
The impetus for us was that we were looking at our data warehouse. We stuff all our data together, and business and strategy folks can make data-driven decisions about sales, strategy or product strategy. That process used to be extraordinarily manual. For every table in our MySQL, an engineer would have to do work to get it out to that data warehouse. It was from several days to a couple weeks of work… We started by looking at our data warehouse. It would take 10 to 15 years of work to get all our data there, and we needed it there sooner. Even with the amount of time and effort we put into this pipeline, we think we saved $10 million in terms of lower engineering costs by building this system. Once we connected up Salesforce, that starts to push that number up.
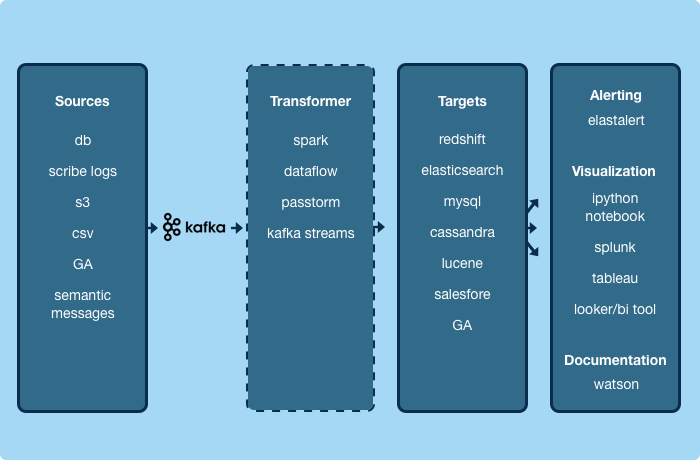
Services consume from the pipeline via the client library, and at Yelp feed into targets like Salesforce, RedShift and Marketo. The library reportedly handles Kafka topic names, encryption, and consumer partitioning. Centralizing service communications through a message broker while enforcing immutable schema versioning helps protect downstream consumers and is also a primary motivation behind the broader data pipeline initiative.
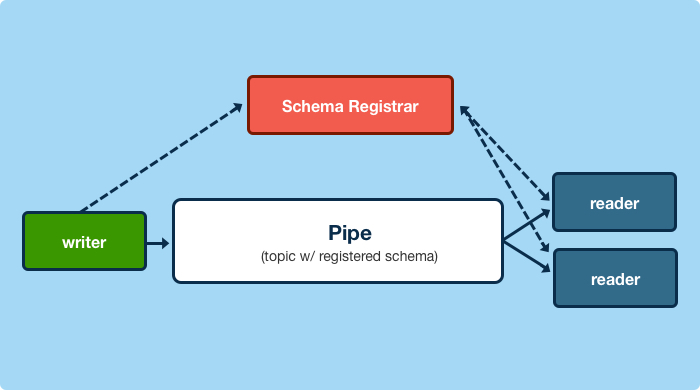
For example, physical changes or business-logic laden data from an upstream MySql database backing a service can be streamed to Kafka by publishing messages with Yelp’s MySql streamer. The Schematizer and the data pipeline client register the topic’s schema, its data types and format, and envelops messages in relevant metadata and versioning for downstream consumption. The metadata wrapper guarantees consistency between messages of varying payload types and kafka topics, but the payload contents themselves can be used for change data capture and take advantage of Kafka streaming and log compression for downstream updates.
{kind=link}
The new pipeline led to drastic improvements in end-to-end time between upstream changes and data warehouse updates. Fennell noted:
We managed to make a process that could take as long as three weeks to get data, down to a few seconds… We can start plugging in other sorts of things. It’s not just Salesforce, but also Redshift that a lot of our business strategy folks use. As we hook up other things like MySQL so logs are coming into our data pipeline, Kafka forms this central routing layer for us, which means each additional source we add gets multiplicative influence.