Pivotal announced the General Availability of Spring Cloud Data Flow for Cloud Foundry, which is an orchestration service for composable microservice applications on Cloud Foundry.
Based around Spring Cloud Data Flow, which in itself is a refactor of Spring XD, Spring Cloud Data Flow for Cloud Foundry provides a foundational enterprise architecture for running data-centric microservice applications on Cloud Foundry by providing a series of patterns and best practices although it's not an out-of-the box ETL or data integration solution. Freed from distributed architectural concerns and one off integration to existing systems, Spring Cloud Data Flow developers have a solid foundation for project reuse.
InfoQ caught up with Eric Bottard, senior engineer at Pivotal responsible for the effort.
InfoQ: Can you briefly dive into what Spring Cloud Data Flow for Cloud Foundry is, and what other projects in the Spring ecosystem it is based on? Is there a shorter name for the project?
Eric Bottard: Spring Cloud Data Flow for Cloud Foundry is the incarnation of the Spring Cloud Data Flow product running on Cloud Foundry. It is part of a bigger family (other runtimes are supported through the concept of "deployer" abstraction), and could be described as an orchestration layer on top of Spring Boot applications. More precisely, it allows the coordinated deployment and monitoring of "streams" (a logical construct made of several data-driven apps where each app "talks" to the next, with data flowing from a start to an end) and tasks (apps meant to run only once on a fixed amount of data).
It is an optional addition to the toolset of the Spring developer, who uses Spring Cloud Stream or Spring Cloud Task, or a combination of the two. Data Flow itself is built using Spring Boot and other Spring Cloud libraries in a layer cake architecture.
Indeed, it has a long name, so sometimes we nickname it SCDF, with the Cloud Foundry edition being written "SCDF for CF."
{kind=link}
InfoQ: Did Spring XD heavily influence the project design? What are the limitations of Spring XD that you have overcome in Spring Cloud Data Flow, and how does this project compare to platforms such as Apache Spark, Flink, Kafka, etc.?
Bottard: Absolutely. We originally designed Spring XD as a standalone product for distributed data pipelines, investing a non-trivial amount of effort in building a resilient runtime for deploying apps. But as market requirements for features such as uninterrupted scaling, canary deployments or distributed tracing emerged, we realized these concerns were better handled by platforms such as Cloud Foundry. Spring Cloud Data Flow better focuses on value add for customers, greatly lowering the barrier to entry for writing a data driven app.
When it comes to comparing Data Flow to some of the products you mention, the Spring philosophy applies: while some technologies may be seen as occupying the same market share (such as Apache Flink), they often require a dedicated runtime environment that introduces an added cognitive burden that is often not needed when creating data centric applications. Some others are components that we leverage (Apache Kafka is definitely an implementation of choice as a binder —that’s the term Spring Cloud Stream uses for its abstraction of messaging middlewares). Sometimes also, integrations are possible to get the best of both worlds, or to transition from an existing architecture - this typically makes sense with Apache Spark.
InfoQ: Whereas Cloud Foundry is a platform for microservices, Spring Cloud Data Flow for Cloud Foundry is specifically for data microservices. Can you touch upon the distinction between microservices in general and data microservices in particular vis-à-vis the Spring Platform?
Bottard: When developers think of microservices, they think RESTful services, easy externalized configuration and dynamic service discovery, precisely what Spring Boot and Spring Cloud provide. But enterprise applications don’t stop at these basics. You also need a way to easily author message driven and task driven applications, without having to deal with the boilerplate of specific integration products. And this is exactly what Spring Cloud Stream and Spring Cloud Task bring to the table. Spring Cloud Data Flow orchestrates data pipelines composed of Spring Cloud Stream or Stream Cloud Task applications.
InfoQ: Spring Cloud Data Flow for Cloud Foundry can be used both for batch and streaming applications, correct? Can you provide some technical details of the implementation and how the platform is optimized for both?
Bottard: Well that's the trick: there is no such thing as a "Spring Cloud Data Flow" application that you would write. This is all really Spring Cloud Stream / Task apps that you orchestrate using Data Flow. This has been a key principle in the design of Data Flow: it really is here to help you hook together microservice applications that you could run "by hand", all of that also abstracting away the actual runtime the apps are running on. Cloud Foundry is only one of the many implementations that can be used.
Things start to get interesting when your use case involves both streaming and bounded data. Maybe you want task oriented events (such as notifications of the end of a batch being handled) to feed your continuous processing. This is the kind of thing Data Flow provides.
In terms of implementation details, streams and tasks apps closely map to the LRP and Task concepts of Cloud Foundry, respectively. LRP stands for Long Running Process and is managed by the platform, making sure that it is always on and even scaled if need be. A task, on the other hand, has a beginning and an end.
InfoQ: From a Developer perspective, there are a variety of ways of using Spring Cloud Data Flow including as a DSL, Dashboard and more. Can you comment on these approaches and what a typical way to get started is?
Bottard: That's right. Spring Cloud Data Flow maintains a model of constructs that help you fulfill your particular use case ("streams" and "tasks" in SCDF parlance) and whether and how those constructs are deployed on your runtime of choice (for example Cloud Foundry). All of this is exposed via a RESTful API, and whether you interact with it using the dashboard UI, the provided shell or even directly doesn't really matter.
The provided shell is a typical developer tool, often preferred by data engineer profiles. It uses a unix-like DSL where communication between apps are represented by pipes, as in "http --server.port=1234 | hdfs".
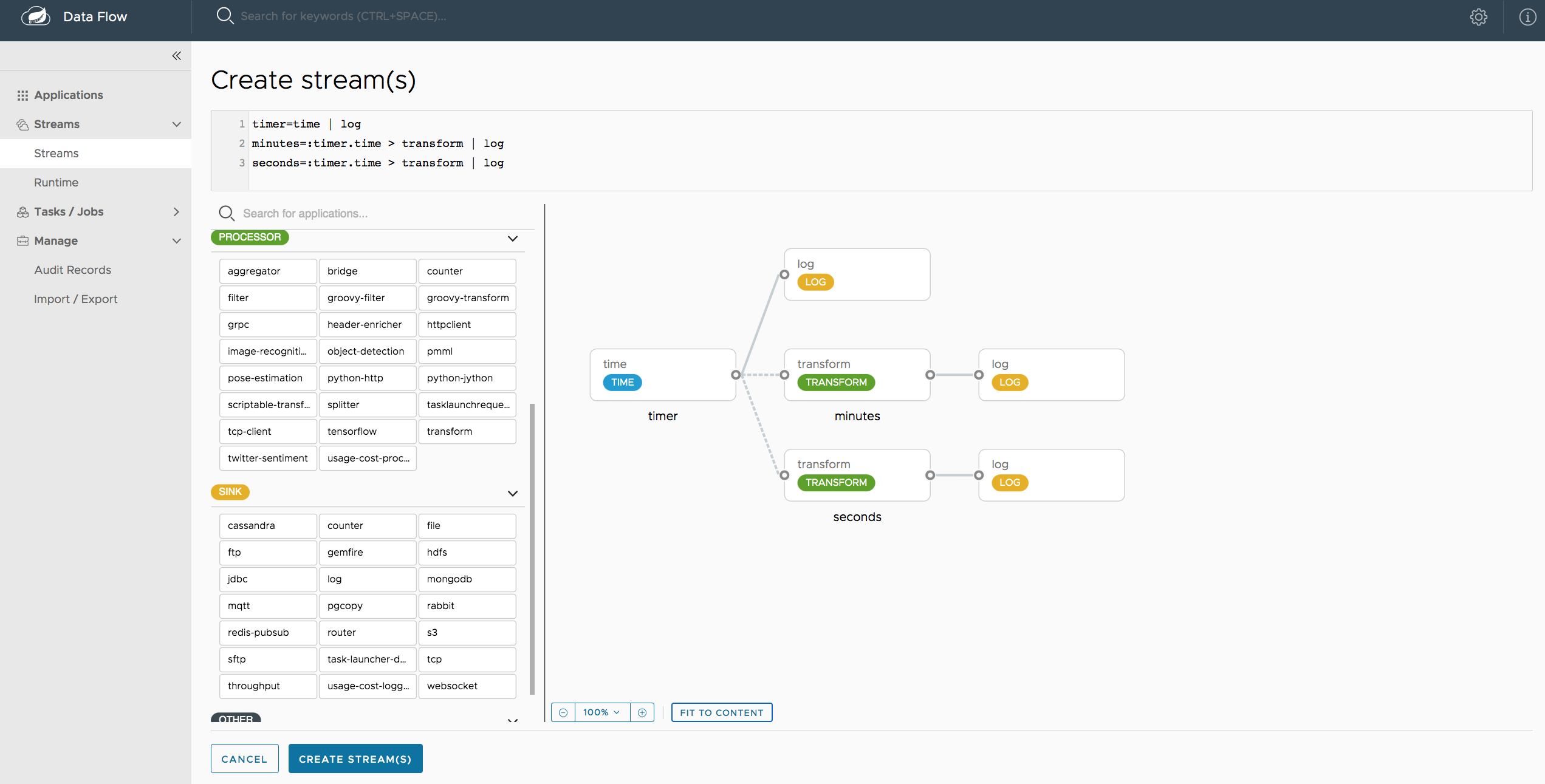
Data scientists and data warehouse guys on the other hand often like the Dashboard UI, which, on top of the DSL textual representation, also offers a blueprint view. This comes in handy when your solution grows in size and some streams start to "tap into" other streams as shown in this illustration.
{kind=link}
InfoQ: Is this aimed only for Pivotal’s version of Cloud Foundry, or can this be used in other Cloud Foundry based platforms? Can you elaborate on the roadmap for the project?
Bottard: Data Flow relies on a deployer abstraction to interact with Cloud Foundry, and this is built against the documented and open source Cloud Foundry API, so Data Flow itself is definitely compatible with other platforms. If any, limitations may come from the lack of support for a particular service (such as RabbitMQ) on some platforms, in which case your streams would need to use a different messaging middleware.
We strive to release a new version of Data Flow every three months. This often includes addition to the catalog of out-of-the-box applications that we provide, as well as core enhancements. For example, v1.2 will bring composed tasks, role based security and a better user experience when using Docker based apps.
A quickstart section and documentation is available on how to get started with Spring Cloud Data Flow for Cloud Foundry.