Recently, Amazon announced AWS Glue now supports streaming ETL. With this new feature, customers can easily set up continuous ingestion pipelines that prepare streaming data on the fly and make it available for analysis in seconds.
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy for customers to prepare and load their data for analytics. Since its general availability, Amazon updated the service with several features, the latest of which is the support for streaming ETL Jobs. Danilo Poccia, chief evangelist (EMEA) at Amazon Web Services, wrote in a blog post about the new feature:
Managing continuous ingestion pipelines and processing data on-the-fly is quite complex, because it’s an always-on system that needs to be managed, patched, scaled, and generally taken care of. Today, we are making this easier and more cost-effective to implement by extending AWS Glue jobs, based on Apache Spark, to run continuously and consume data from streaming platforms such as Amazon Kinesis Data Streams and Apache Kafka (including the fully-managed Amazon MSK).
Furthermore, customers can provision, manage, and scale the infrastructure needed to ingest data to data lakes on Amazon S3, and data warehouses such as Amazon Redshift, or other data stores. Next, they can create a unified view of their data via the Glue Data Catalog that is available for ETL, querying and reporting using services like Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum.
The use case for AWS Glue is when customers want to use the jobs to process event data such as IoT event streams, clickstreams, and network logs. When they process streaming data in a Glue job, they have access to the full capabilities of Spark Structured Streaming – allowing them to implement data transformations, such as aggregating, partitioning, and formatting. Furthermore, they can join this data with other data sets to enrich or cleanse the data for easier analysis.
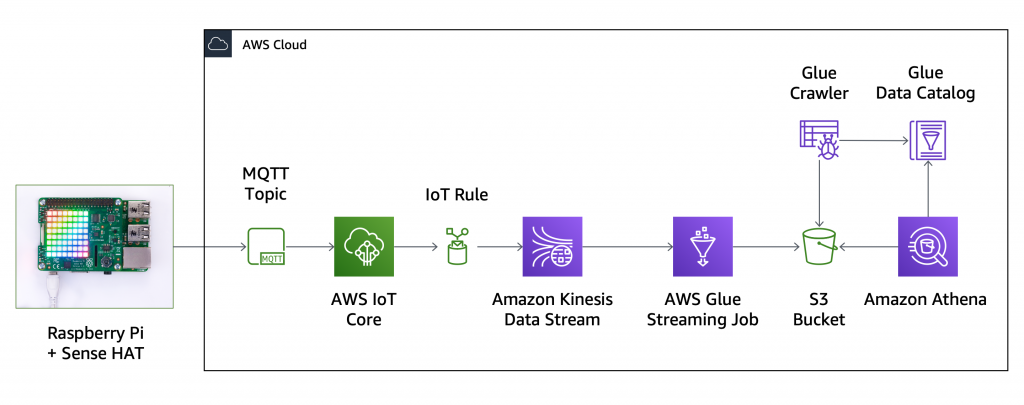
Source: https://aws.amazon.com/blogs/aws/new-serverless-streaming-etl-with-aws-glue/
AWS Glue will automatically generate Scala or Python code for the streaming ETL jobs that users can further customize using tools they are used to. Furthermore, AWS Glue is serverless - therefore, there are no compute resources to configure and manage. As Poccia states in the same blog post:
Managing a serverless ETL pipeline with Glue makes it easier and more cost-effective to set up and manage streaming ingestion processes, reducing implementation efforts so you can focus on the business outcomes of analytics.
The streaming ETL feature is now available in the same AWS regions as AWS Glue. Furthermore, pricing details of AWS Glue are available on the pricing page.