Microsoft Research recently developed a new object-attribute detection model for image encoding, which they named VinVL - Visual features in Vision-Language.
To mimic human abilities to understand images they see and interpret sounds they hear, researchers in Artificial Intelligence (AI) try to allow a computer to have the same skills. These skills can be made possible by providing computers with a visual language to understand the world around them effectively. For instance, vision-language (VL) systems allow searching the relevant images for a text query (or vice versa) and describing an image's content using natural language. Such systems consist of two modules:
- An image encoding module to generate feature maps of an input image and
- A vision-language fusion module mapping the encoded image and text into vectors in the same semantic space so that their semantic similarity can be computed using the cosine distance of their vectors.
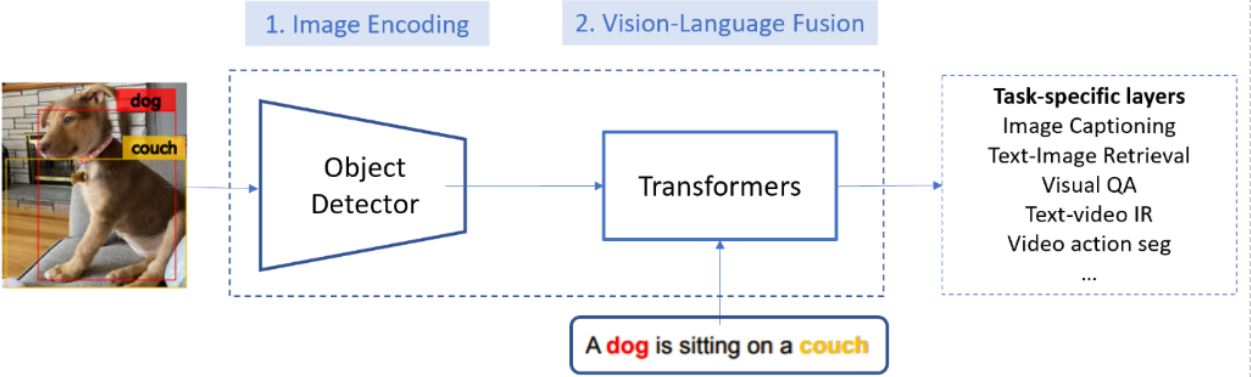
The researchers at Microsoft worked on the improvement of the image encoding module by developing VinVL. By combining VL fusion modules such as OSCAR and VIVO with VinVL, the Microsoft VL system sets new state of the art on all seven major VL benchmarks. According to a Microsoft Research blog post on VinVL, the VL system achieved top position in the most competitive VL leaderboards, including Visual Question Answering (VQA), Microsoft COCO Image Captioning, and Novel Object Captioning (nocaps). Moreover, the Microsoft VL system significantly surpasses human performance on the nocaps leaderboard in terms of CIDEr (92.5 vs. 85.3).
Microsoft trained their object-attribute detection model for VL tasks by using a large object detection dataset containing 2.49M images for 1,848 object classes and 524 attribute classes and merging four public object detection datasets (COCO, Open Images, Objects365, and VG). They first pretrained an object detection model on the combined dataset - and then fine-tuned the model with an additional attribute branch on VG, making it capable of detecting both objects and attributes. As a result, the model can detect 1,594 object classes and 524 visual attributes. Moreover, according to the blog post, in experiments by the researchers, the model can detect and encode nearly all the semantically meaningful regions in an input image.
In the blog post, the authors state:
Despite the promising results we obtained, such as surpassing human performance on image captioning benchmarks, our model is by no means reaching the human-level intelligence of VL understanding. Interesting directions of future works include: (1) further scale up the object-attribute detection pretraining by leveraging massive image classification/tagging data, and (2) extend the methods of cross-modal VL representation learning to building perception-grounded language models that can ground visual concepts in natural language, and vice versa like humans do.
Lastly, in the Research blog, the company announced it would release the VinVL model and source code to the public. More details are available in the research paper and the source code in a GitHub repository. Furthermore, Microsoft will integrate VinVL into its Azure Cognitive Services offering.