Dropbox has published a detailed account of why and how they unplugged an entire data center to test their disaster readiness. With a dependency on their San Jose data center, Dropbox ran a multi-year project to engineer away this single point of failure in their metadata stack, culminating in a deliberate and successful switch-off of the San Jose data center.
Dropbox had moved away from AWS for storing data, but were still heavily centralised and dependent on their San Jose data center. The recovery time from an outage at San Jose was considered to be far in excess of what was desired - hence initiating a project to improve this in case of a significant disaster - such as an earthquake at the nearby San Andreas Fault. The improvement was measured as a Recovery Time Objective (RTO) - a standard measure from Disaster Recovery Planning (DRP) for the maximum time a system can be tolerably down for after a failure or disaster occurs.
The overall architecture of Dropbox's systems involves a system to store files (block storage), and another system to store the metadata about those files. The architecture for block storage - named Magic Pocket - allows block data to be served from multiple data centers in an active/active configuration, and part of this new resilience work involved making the metadata service more resilient, and eventually also active/active too. Making the metadata stack resilient proved to be a difficult goal to achieve. Some earlier design tradeoffs - such as using asynchronous replication of MySQL data between regions and using caches to scale databases - forced a rethink of the disaster readiness plan.
The disaster readiness team began building tools to make performing frequent failovers possible, and ran their first formalized failover in 2019. Following this, quarterly failovers were performed, until a fault in the failover tooling caused a 47 minute outage in May 2020, highlighting that the failover tooling did not itself fail safely. A dedicated Disaster Readiness (DR) team was formed, also charged with owning all failover process and tooling, and performing regular failovers, thus removing the competing priorities involved before there was a dedicated team.
Early 2020 brought a new evolution of the failover tooling - with a runbook made up of a number of failover tasks linked together in a DAG (directed acyclic graph). This made for a much more lightweight failover process, with re-usable tasks and easier regular testing of each task. Also, it became easy to see whether tasks had succeeded or not, and important actions were guarded in case of a failure in a preceding task.
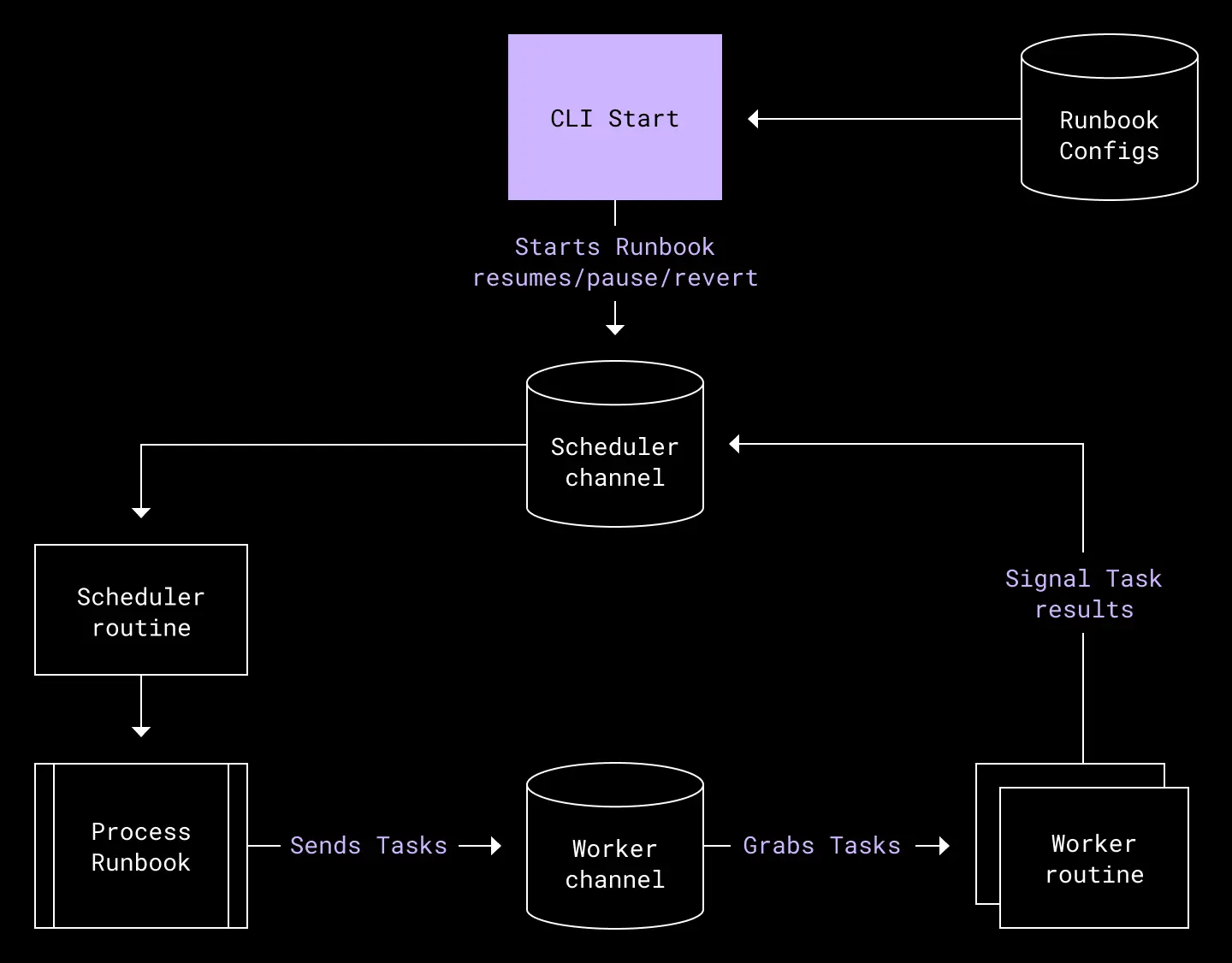
Dropbox implemented other changes to help reduce risk, with a customer-first strategy:
- Routine testing of key failover procedures - regular automated small-scale tests of failover tasks
- Improved operational procedures - a formalized go/no-go decision point, checks leading up to a failover "countdown", and clearly defined roles for people during a failover
- Abort criteria and procedures - clearly defining when and how a failover would be aborted
In addition to working on the DR processes and tools as described above, a small team also began working on true active/passive architecture. This involved improving internal services that were still running only in the San Jose data center, so that they could either run multi-homed in multiple data centers, or single-homed in a location other than San Jose. Techniques and tools used here included using the load-balancer Envoy, and using common failover RPC clients with Courier to redirect a service's client requests to another data center.
The final steps in preparation for unplugging San Jose involved making a detailed Method of Procedure (MoP) to perform the failover, and this was tested on a lower-risk data center first - that at Dallas Fort Worth. After disconnecting one of the DFW data centers, whilst performing validations that everything was still working, engineers realised that external availability was dropping, and the failover was aborted four minutes later. This test had revealed a previously hidden single point-of-failure in an S3 proxy service.
The failed test provided several lessons to the team - significantly that blackhole tests needed to test entire regions (metros) and not individual data centers. A second test at DFW after adjusting the MoP to accommodate these learnings was successful. Finally, the team was ready to disconnect the San Jose data center. Thanks to all the planning, the new tooling and procedures, there was no impact to global availability, and the anti-climactic event was declared a success. This provided a significantly reduced RTO and proved that Dropbox could run indefinitely from another region, and without San Jose.
The key takeaways from this multi-year project were that it takes training and practice to get stronger at Disaster Readiness. Dropbox now has the ability to conduct blackhole exercises regularly, and this ensures that the DR capabilities will only continue to improve, with users never noticing when something goes wrong.