Microsoft has recently unveiled several new features for Azure Cosmos DB to enhance cost efficiency, boost performance, and increase elasticity. These features are burst capacity, hierarchical partition keys, serverless container storage of 1 TB, and priority-based execution.
Azure Cosmos DB is Microsoft’s globally distributed, multi-model database service that offers low-latency, scalable storage and querying of diverse data types. The burst capacity feature for the service was announced at the recent annual Build conference and is generally available (GA) to allow users to take advantage of your database or container’s idle throughput capacity to handle traffic spikes. In addition, the company also announced the GA of hierarchical partition keys, also known as sub-partitioning for Azure Cosmos DB for NoSQL, and the expansion of the storage capacity of serverless containers to 1 TB (previously, the limit was 50 GB).
Beyond Build, the company also introduced the public preview of priority-based execution, a capability that allows users to specify the priority for the request sent to Azure Cosmos DB. When the number of requests exceeds the configured Request Units per second (RU/s) in Azure Cosmos DB, low-priority requests are throttled to prioritize the execution of high-priority requests, as determined by the user-defined priority.
Richa Gaur, a product manager at Microsoft, explains in a blog post:
This capability allows a user to perform more important tasks while delaying less important tasks when there are a higher number of requests than what a container with configured RU/s can handle at a given time. Less important tasks will be continuously retried by any client using an SDK based on the retry policy configured.
Using Mircosoft.Azure.Cosmos.PartitionKey;
Using Mircosoft.Azure.Cosmos.PriorityLevel;
//update products catalog
RequestOptions catalogRequestOptions = new ItemRequestOptions{PriorityLevel = PriorityLevel.Low};
PartitionKey pk = new PartitionKey(“productId1”);
ItemResponse<Product> catalogResponse = await this.container.CreateItemAsync<Product>(product1, pk, requestOptions);
//Display product information to user
RequestOptions getProductRequestOptions = new ItemRequestOptions{PriorityLevel = PriorityLevel.High};
string id = “productId2”;
PartitionKey pk = new PartitionKey(id);
ItemResponse<Product> productResponse = await this.container.ReadItemAsync< Product>(id, pk, getProductRequestOptions);
Similarly, users can maintain performance for short, temporary bursts, as requests that otherwise would have been rate-limited (429) can now be served by burst capacity when available. In a deep dive Cosmos DB blog post, the authors explain:
With burst capacity, each physical partition can accumulate up to 5 minutes of idle capacity. This capacity can be consumed at a rate of up to 3000 RU/s. Burst capacity applies to databases and containers that use manual or autoscale throughput and have less than 3000 RU/s provisioned per physical partition.
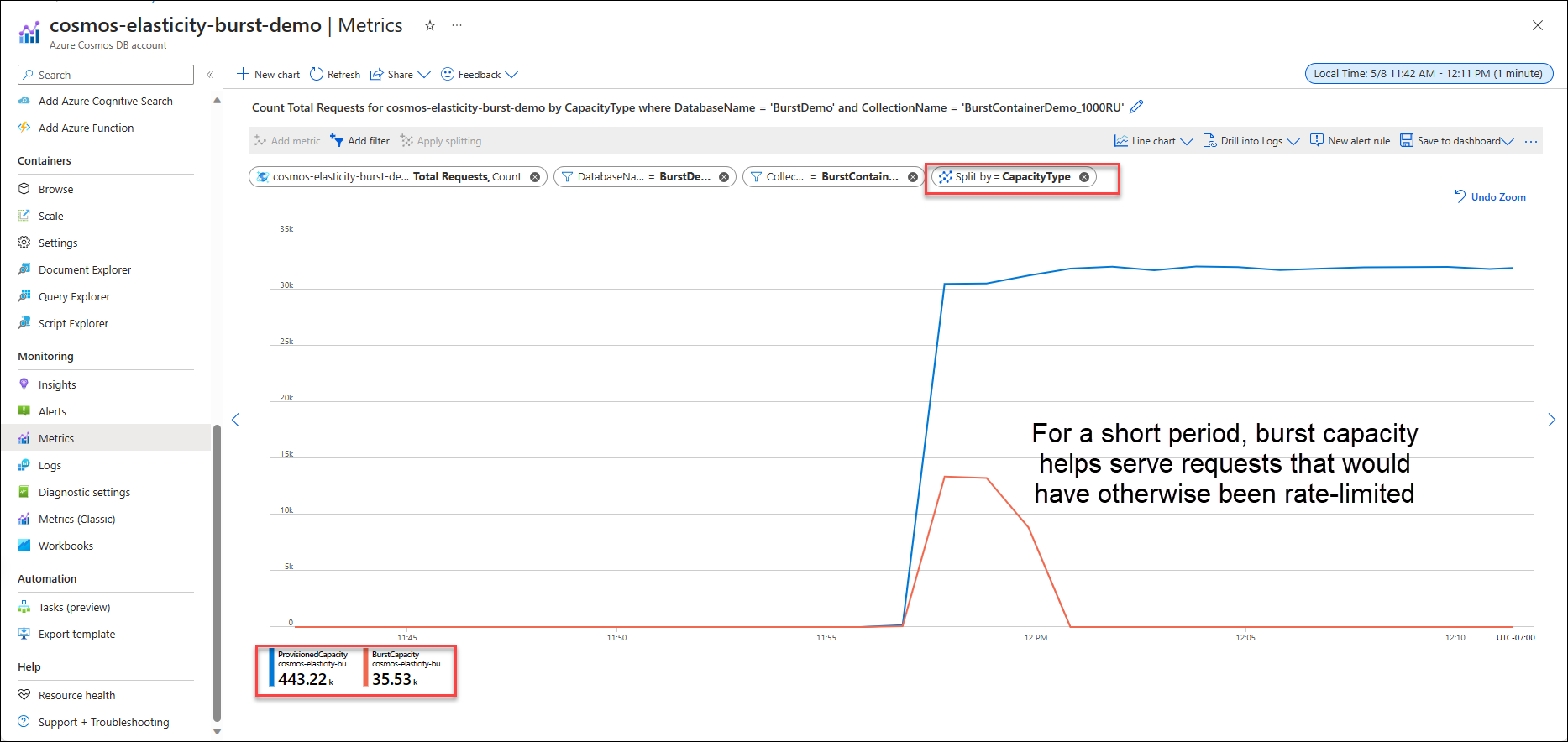
Source: https://devblogs.microsoft.com/cosmosdb/deep-dive-new-elasticity-features/
Next to optimizing performance, the hierarchical partition keys help in elasticity for Cosmos DB. The feature can help in scenarios where users leverage synthetic partition keys or logical partition keys that can exceed 20 GB of data. They can use up to three keys with hierarchical partition keys to further sub-partition their data, enabling more optimal data distribution and a larger scale. Behind the scenes, Azure Cosmos DB will automatically distribute their data among physical partitions such that a logical partition prefix can exceed the limit of 20GB of storage.
Leonard Lobel, a Microsoft Data Platform MVP, outlines the benefit of hierarchical keys in an IoT scenario in a blog post:
You could define a hierarchical partition key based on device ID and month. Then, devices that accumulate less than 20 GB of data can store all their telemetry inside a single 20 GB partition, but devices that accumulate more data can exceed 20 GB and span multiple physical partitions, while keeping each month’s worth of data "sub-partitioned" inside individual 20 GB logical partitions. Then, querying on any device ID will always result in either a single-partition query (devices with less telemetry) or a sub-partition query (devices with more telemetry).
Lastly, with the expansion of the storage capacity of serverless containers to 1 TB, users can benefit from the maximum throughput for serverless containers starting from 5000 RU/s, and they can go beyond 20,000 RU/s depending on the number of partitions available in the container. In addition, it also offers increased burstability.