Confluent recently announced the open preview of Apache Flink on Confluent Cloud as a fully managed service for stream processing. The company claims that the managed service will make it easier for companies to filter, join, and enrich data streams with Flink.
Apache Flink is an open-source, unified stream-processing and batch-processing framework developed by the Apache Software Foundation, designed to run in all common cluster environments and perform computations at in-memory speed and at any scale.
Confluent brings Flink to their cloud as a managed service, where users do not have to choose a version and will always have the latest. Furthermore, all Flink SQL Statements on Confluent Cloud are continuously monitored and auto-scaled to always keep up with the rate of their input topics, and billing is based on the average current size of Compute Pools. The pools elastically scale up and down based on the needs of the Statements that are using them - including scaling to zero if there are no Statements.
Confluent already has Apache Kafka in their cloud offering. Kafka provides the event streaming, while Flink is used to process data from that stream. Both are available in Confluent Cloud as managed services and can be used together for use cases like batch processing, stream processing, event-driven applications, streaming applications, data analysis (batch, streaming), and data pipelines.
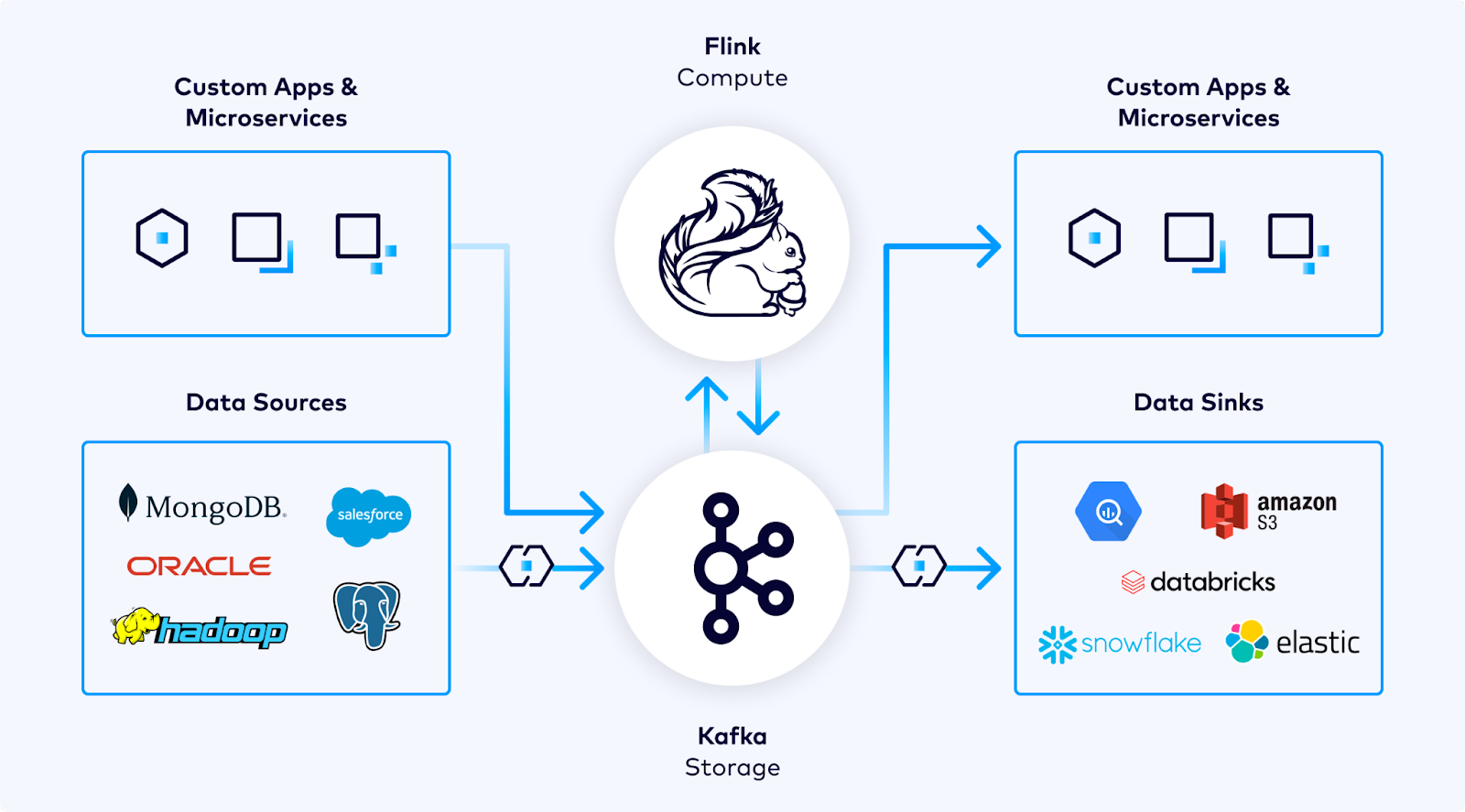
Flink as the streaming compute layer for Kafka (Source: Apache Flink on Confluent Cloud blog post)
When asked by InfoQ about what is driving this investment from Confluent, here is what James Rowland-Jones, director of product management at Confluent, had to say:
We chose to invest in Apache Flink because we believe it has all the ingredients needed to build a simple, serverless, and cloud-native stream processing service capable of operating at any scale. Flink also has a vibrant and passionate community that has contributed to its success over many years, aligning well with Confluent’s culture of contributing to open source.
In addition, he said:
Stream processing has strong synergy with Apache Kafka, and the overwhelming majority of Flink customers choose Kafka for their streaming storage. We believe Confluent is perfectly positioned to bring all the benefits of Flink and Kafka together to create a unified data streaming platform, empowering every organization to set their data in motion.
Also, Richard Seroter, a director of DevRel and outbound product management at Google, tweeted:
there haven't been a ton of ways to get a managed Flink experience, so it's good to see @confluentinc open this up in preview
Lastly, Apache Flink is currently available as an open preview for Confluent Cloud customers using AWS in select regions for testing and experimentation purposes. The company states that general availability is coming soon.