Yahoo open sourced TensorFlowOnSpark so data scientists and engineers can do distributed training and model-serving on CPU/GPU architectures directly running Spark or Hadoop. The library reportedly allows porting existing TensorFlow programs to the new APIs and achieves reported training and model-serving performance improvements.
In the announcement, Yahoo reported on motivators for TensorFlowOnSpark such as the operational overhead of managing additional clusters outside Spark data pipelines specifically for deep neural network training, network I/O bound dataset transfers into and out of the training cluster, unwanted system complexity, and overall end to end learning latencies. The TensorFlowOnSpark effort is similar to prior art Yahoo embarked on with CaffeOnSpark. Existing work on the challenge of TensorFlow and Spark integration by DataBricks with TensorFrame, and Amp Lab's SparkNet were steps in the right direction according to Yahoo, but fell short on allowing TensorFlow processes to communicate directly with each other. One of Yahoo's goals was to make TensorFlowOnSpark a fully Spark-compatable API that works as well as things like SparkSQL, MLib and other core Spark libraries in terms of integration ability within a spark processing pipeline.
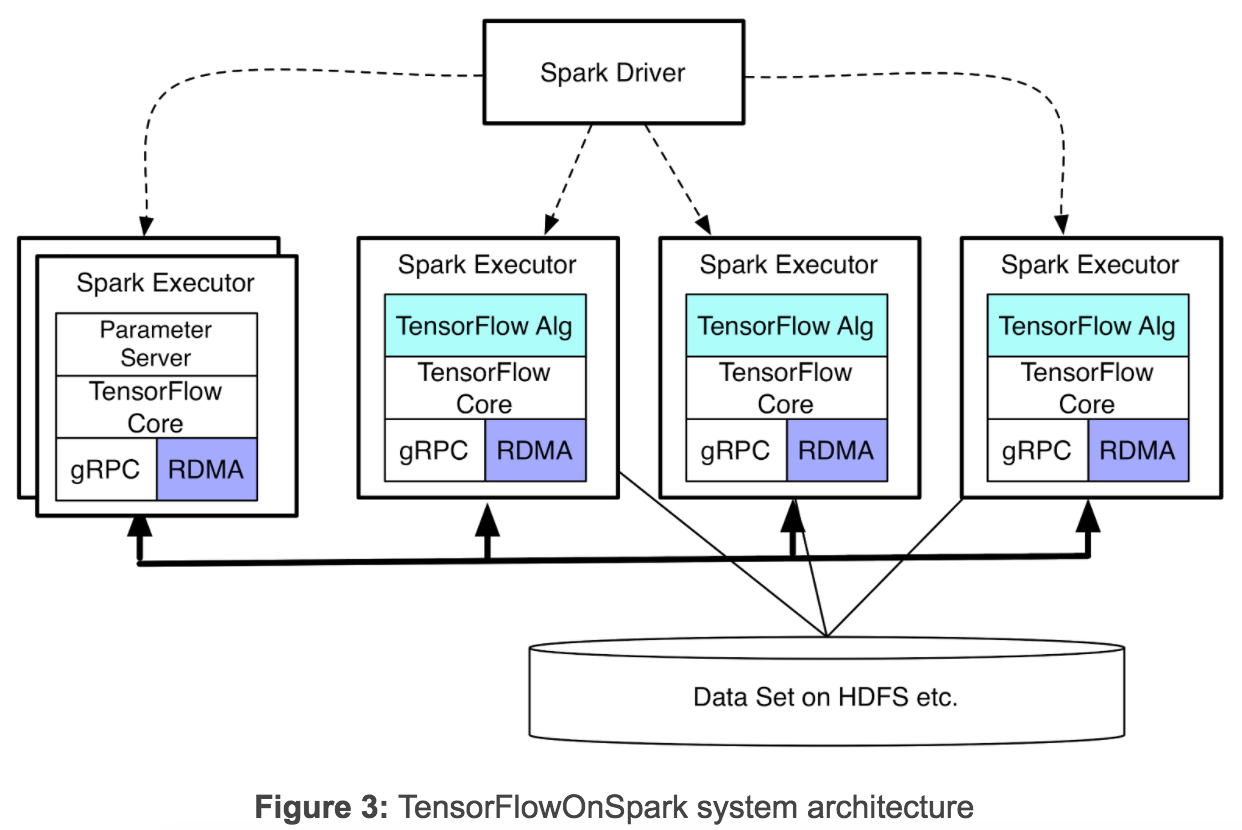
The architecture places a given TensorFlow algorithm and TensorFlow core inside a Spark Executor, and provides the TensorFlow job with direct access to HDFS data via TensorFlow's file readers and QueueRunners, allowing for less network I/O and a "take the computation to the data" approach. TensorFlowOnSpark supports semantics for port reservation/listening for executors, message polling for data and control functions, TensorFlow main function startup, data ingestion, reader and queue-runner mechanisms for reading directly from HDFS, Spark RDD feeds into TensorFlow via feed_dict, and shutdown.
{kind=link}
In addition to TensorFlowOnSpark, Yahoo also extended the core TensorFlow C++ engine on their own fork to enable RDMA over Infiniband, a feature that had been requested and generated discussion on the main TensorFlow project. Yahoo's Andy Feng noted a ten to two-hundred percent training speed improvement on various networks using RDMA over gRPC based inter-process communication.